 It would be very arrogant of me to suggest that I have the solution for measuring the effort that goes into post-editing translations, wherever they originated from, but in particular machine translation. So let’s table that right away because there are many ways to measure, and pay for, post-editing work and I’m not going to suggest a single answer to suit everyone.
It would be very arrogant of me to suggest that I have the solution for measuring the effort that goes into post-editing translations, wherever they originated from, but in particular machine translation. So let’s table that right away because there are many ways to measure, and pay for, post-editing work and I’m not going to suggest a single answer to suit everyone.
But I think I can safely say that finding a way to measure, and pay for post-editing translations in a consistent way that provided good visibility into how many changes had been made, and allowed you to build a cost model you could be happy with, is something many companies and translators are still investigating.
The first problem of course is that when you use Machine Translation you can’t see where the differences are between the suggested translation and the one you wish to provide.

I’m reliably informed that a better translation of this Machine Translated text would require a number of changes that would equate to a 58% fuzzy match:

But how would I know this, and is it correct to view the effort required here as a 58% fuzzy match and pay the translator on this basis? Well, if you could measure the effort in this way there are a few obvious things to consider. First of all you don’t know it was a 58% match until after the work was complete. Secondly a 58% post-edit analysis may not require the same effort as a 58% fuzzy from a traditional Translation Memory because there is no information provided to help the translator see what needs to be changed in the first place. Thirdly it may be quite appropriate when post-editing to be satisfied that the structure is basically correct and the meaning can be understood. So no need to change it so that it is written more in keeping with the style and perfection you might be expected to deliver for a legal or medical task.
You could consider other methods such as a fixed rate, an hourly rate, a productivity measure (useful on large Projects perhaps… not so much on small jobs) or perhaps a way to measure the quality of the original Machine Translation and the likely effort to “improve” it. All of these are subject to more variables such as the quality of the Machine Translation in the first place, and this can not only vary between Machine Translation engines but also quality of the source text and the language pairs in question. There are probably more factors outside the scope of this article I haven’t mentioned at all, but the overriding consideration in my opinion is that you want to be able to provide fair compensation for the translator (or post-editor) and balance this with a fair return for the work giver who has probably adopted and invested into Machine Translation looking for better returns for their own business.
All of these methods have their pros and cons, some allowing you to estimate the costs of the translation before you do the work, and some only once the work has been completed. In this article I want to discuss one possible solution based on the post-edit analysis approach I introduced at the start. This used an application written by Patrick Hartnett of the SDLXLIFF to Legacy Converter, SDLXLIFF Compare and the TAUS Search TM Provider fame.
Post-Edit Compare is a standalone application (available on the OpenExchange from here : Post-Edit Compare) that uses the Studio APIs to compare Studio Projects. So the idea is that you would take a copy of the original pretranslated Project and then compare this with a post-edited version. The pretranslation could be based on machine translation, conventional Translation Memory or you could even use this to compare a human translated Project before and after client review for example.
Comparing Projects
The main interface looks like this, with the files for the original Project on the left and the post-edited Project on the right. There are various controls to display more or less files as you see fit, so for example in this view the red files have been post-edited whilst the black ones are exactly the same; but I could filter in this to see only the ones that have changed.
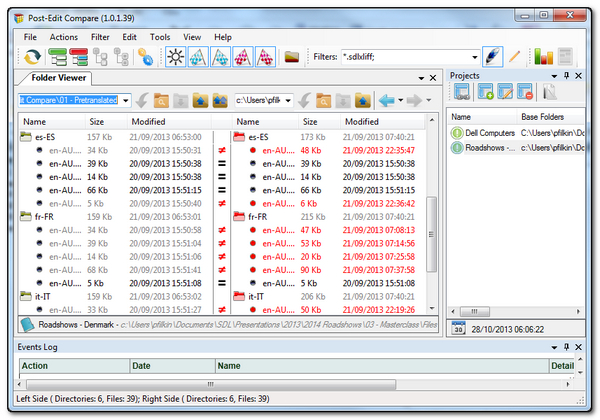
On the right hand side you can see a Projects Pane. This allows you to have many Comparison Projects on the go at the same time and easily navigate to them which will be a god send for a busy Project Manager as the Project list grows. It also maintains the file name alignment functionality which is useful if the filenames changed slightly during the course of a Project as it can quickly re-match the files and save the information in the right place.
Once you have selected the Projects you wish to compare you can create various reports out of the box to show things like these:
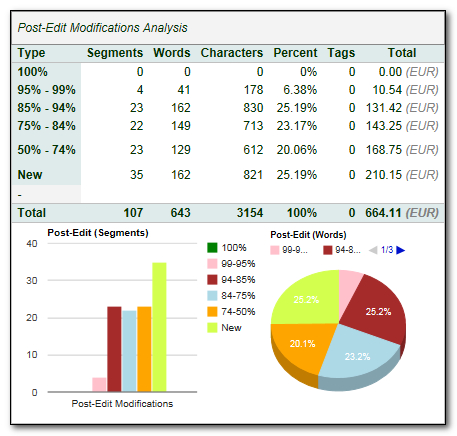
- Studio summary analysis providing the post-edit statistics across all files in the project and an associated value for the work. You can also get an overview at a glance of many of the statistics by reviewing the nicely laid out graphical representations:
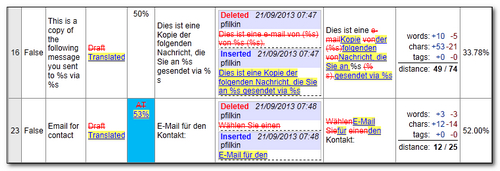
- At a more detailed level you can drill into the individual changes and see exactly what changes were made, by whom if track changes are used for the editing, and the Edit Distance calculation (based around the Damerau-Levenshtein method for those of you interested in the theory of these things). In this screenshot you can see segment 16 was the result of post-editing a Translation Memory result with a low 50% fuzzy match whereas segment 23 was a post-edit of a Machine Translated segment. The help files with the application explain in some detail what all the columns are for and how they are calculated:
There is a lot more information in the reporting than this, and you have a lot of built in options within the tool itself that can reduce or increase the level of detail you want to see. I also know the developer is very keen to extend the reporting capability as he has built in an excellent reporting tool, so I’m sure your feedback as you use the tool will be welcomed. But for now the only other part I want to look at briefly is the costs shown in the Post-Edit Modifications Analysis… Studio doesn’t report on costs out of the box so this is another nice feature within this tool.
Allocating Costs
The detailed Post-Edit Modification (PEM) calculations allow the application to assign the PEM changes to the appropriate analysis band. So just like Studio these are based on analysis bands (100%, 95% – 99%, 85% – 94% etc.) and it can apply a price calculation based on rates for the different analysis band categories. It does this by storing the rates in something called Price Groups.
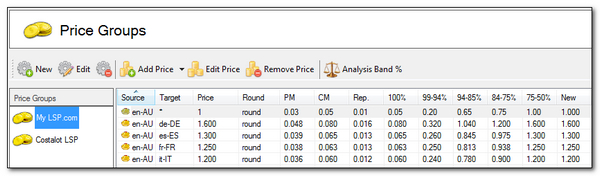
These Price Groups are very powerful and they give you the ability to create different price groups for different Companies, or Translators and also for different language pairs. Once you have set these up in the way you wish you can then generate the appropriate costs for the changes in a post-editing Project at the click of a button… more or less!
I’m not going to go into too much detail on this aspect because it would be worth downloading a trial version to take a look yourself. The price of the full version is € 49,99 and in my opinion well worth it. The use cases are numerous… here’s a few off the top of my head:
- An Agency looking for a way to agree appropriate rates for post-editing work and then be able to consistently pay on this basis with different Price Groups for different linguistic requirements perhaps;
- A Translator looking for a way to agree, or charge rates for handling occasional requests for post-editing work. If you are not part of a regular post-editing workflow then it’s a convenient way of playing with the rates to see whether the occasional post-edit assignment can work for you and then store your rates to make it easier in the future;
- A Project Manager can use the Reporting to quickly and easily check the amount of changes needed to correct translation work and then provide appropriate feedback, with accurate details, to the translator to help them meet quality expectations for final delivery of target files… and this could be less editing or more depending on the context.
Whilst I deliberately didn’t go into too much detail around the use of Machine Translation and the different ways of handling compensation for post-editing effort I’d be interested to hear your views on this topic in the comments, and also if you try the application what you thought?
Excellent article!
Thank you for all your support with this project development; your insight with the logical aspect of how and what is needed at various stages of development has been invaluable.
I do hope it solves the puzzle at some level and helps simplify & automate this process for companies and professionals requiring this type of functionality.
I truly am interested in getting feedback so that we can continue to evolve the development of this tool and improve it
Patrick.
With this tool in my toolbox, I may be willing to consider MT post editing.
The fundamental flaw that I find with this and similar methods that aim to count the number changes and/or “fuzziness” and use them as the base for effort estimation is that they completely ignore what the translation work is all about.
Simply put, the translation work is all about capturing an idea in one language and convey it naturally in another. The translation work is not about trading in words: words are not the raw material nor the product of the translation work, they are just how the work is presented. Not all words and texts are equal and sometime a short sentence could take hours to translate, and making few edits can take considerable amount of time and could significantly improve (or damage) the text way beyond their plain numerical representation – this is because the translation process is about expertise and skills, not the number of words.
First, post editing is not translation, it is editing. Translation and editing require different mindsets and skill-sets; just because they both superficially seem to deal with language doesn’t make them one of the same.Furthermore, there are some serious health concerns (http://www.mt-archive.info/Aslib-1981-Bevan-1.pdf) regarding the repetitive exposure to low quality language.
And lastly, the MT technology and its appropriate use are an interesting topics to discuss. There are use cases in which it makes sense, mostly in very controlled environments and for low-important and short shelf-life bulk communications, and information screening in some scenarios to name a few.
Technology is a tool that helps the professional; technology can also be abused. In this point in time MT is heavily – and I would even risk saying mostly – abused in the translation market. The MT technology is much more complicated and hard to maintain and use than the majority of snake-oil vendors claim it to be. Many naive and opportunistic translation buyers get scammed this way out of their money, and so do many pseudo-translators who jump on the PEMT wagon.
I can understand how some naive or opportunistic buyers fall into this trap, I can certainly understand the motive of the resellers (both of the technology and translation services) behind it, but I fail to understand how true professional translators fall into that trap.
As one colleague has put it: “PEMT is a horrible way to die, indeed”.
Hi Shai, I read this a few times and to be honest I’m not sure I completely understand your point. I agree that post-editing and translating are different things. But as you said yourself towards the end there are use cases in which it makes sense, so if you do this how do you suggest you get paid for the effort? I think this would be a more interesting observation than one comparing the work of a human translator with that of a post-editor. I also think it’s incorrect to view a post-editor as less professional than a “true” translator. They are different skills and if you don’t want to do it then that’s fine, but I think being able to post-edit effectively takes practice and should be valued accordingly.
I also agree that misuse of machine translation gives this technology a poor reputation, and it is important to discuss this too. But this article is about one method of how you might get paid for taking on post-editing work. I did mention there are others… perhaps you have some thoughts on this?
I didn’t criticize your method and certainly not you, I just commented on why I think the entire approach of determining effort mainly based on the number of words is lacking. My point is that translation is a complex process that requires skill and expertise. Therefore the focus on the number of words and word similarity (i.e. fuzziness) is very misleading and therefore in accurate (and is promoted in part by stakeholders who stand to gain out of it a the expense of the translators/editors). I also commented that editing and translation are not the same thing, so when translators are being targets and PEMTs – someone got their priorities all mixed up. Moreover, editing a monolingual document is not like editing a translation against the source. The latter takes much more time and effort.
My last point was that 0constant exposure to broken language raises some health concern that no one seems to care to discuss.
I don’t have a better suggestion than yours, I actually don’t think that there is a one-size-fits-all solution anyway (as you commented). If I would have to come up with something: A fee should be charged for reading the entire text against the source, and then the a separate fee for the editing effort starts to make a little more sense, but this is just a very crude suggestion that needs a lot of refinement.
I also disagree with the claim that PEMT is venturing into a new realm that still needs charting. Similar post-editing scenarios exist for years now with poor human translations playing the role of MT, and if that experience has thought us something is that there are no magic solutions or shortcuts, and the number of edits is often not reflective of the effort, nor considered a very interesting task (mind-numbing is probably its best description).
There are use cases in which MT can help, but this is the operative word – help. If a human professional can incorporate MT in his or her own workflow, for whatever use, that is one things; but sending volumes of MT produced texts to random editors is a completely another thing.
Hi Shai, probably we’re misunderstanding each other then. I didn’t take offence, I just couldn’t see what you were getting at that related to this article. You seem to have fairly strong views on the use of MT altogether and this almost makes it seem as though you’re commenting on a different discussion 😉 What I like about this particular solution, if I ignore the whole MT or not debate for a minute, is that it helps you to put a measure to this and helps you with the cost models around it for different scenarios. I did expect to see come commentary around this but I guess I wasn’t prepared for the debate on whether MT should be used at all. I think there will always be cases where MT is inappropriate and using well qualified human translators is the only way to go… but I also think MT has opened up the possibility to translate material that probably wouldn’t get translated at all, so in this vein I think it’s worth reviewing how we all value it when post-editing is required. It might be like this, it might be through other means, and it’s this discussion I’m personally more interested in.
My opinion about MT is irrelevant to this discussion. I also didn’t try to steer it towards the MT for or against debate.
Currently, translation supporting technology is heavily abused in the marketplace – this is a separate discussion from the discussion about the technology itself – but it is quite on-topic when it comes to talking about cost-models. While I appreciate and support any much needed attempt to discuss *true* best practices, I find that the discussion usually concentrates on the number or words and other (sometimes contrived) quantitative measures, but just rarely takes into account the expertise and other professional factors involved. Again, translation is not about trading in the number of words – they are not the raw material nor the product of the work – and therefore any attempt to assign them a fixed face-value is missing quite a lot on the professional side of things.
It started with that silly concept of “fuzziness”, that now on its foundation an attempt is being made to establish the concept of MT-fuzziness that, from a professional standpoint, is even more ridiculous than the traditional fuzziness concept.
This is why I have commented, not to criticize your suggested solution, and not to steer the discussion into the debate about MT, but to raise some of the usually ignored issues for the benefit of the readers who may or may not have bought into the FUD and ideas spread by the MT-lobby.
I think you’ve made your position quite clear now… at least I understand it better anyway. How would you measure the translation from one language into another? Not just where an expert and qualified translation is required, but also where the material being translated doesn’t have to be perfect… but rather good enough to get the idea across? In the latter case where an excellent and expensive translation in terms of cost and time could prevent the material from being translated at all.
At the end of the day, everyone has to be paid for their efforts. I know translators who are happy with the word rate mechanism, but based on their own professionalism and the need to use their expertise, they are able to charge more per word than perhaps someone with less domain experience. I know other translators who work on the basis of time alone. I don’t know how you work as you have not given any indication of what is preferable for you. So in my opinion the mechanism for payment is less important then the need to make sure that the translator feels they are being suitably reimbursed for their efforts; the work giver has to be happy with their take for organising the availability of the work in the first place and the end client has to be happy that they can even afford to have the work done. If taking an overview of this using the concept of a fuzzy mechanism for payment means you win some and you lose some, but overall you achieved what you wanted from the Project then I personally don’t see a problem with this at all. It certainly provides for visibility that makes it easy to justify the rates being paid throughout the supply chain.
In many ways the introduction of Machine Translation may even make more work available than there was before. It may be post-editing rather than translation, and this means adopting a different technique than pure translation (if you wish to pursue this kind of work of course). But I think one thing is for sure… it won’t be going away any time soon. On this basis the best way to make sure that the FUD and ideas being spread by “some people” using MT are not allowed to become the norm is to embrace this technology and make sure that best practices are in place. This won’t be easy, and there will always be charlatans as there were before the introduction of MT. But best practices and education are the way to provide governance around this.
I must confess, I didn’t expect this article to head in this direction… although perhaps it’s unsurprising and I was naive in thinking otherwise. Perhaps you’ll be at the ITA next month and we can discuss it face to face… I’m sure that will be far more enjoyable!
Hi Paul,
I didn’t intend to steer the discussion away from the original topic, nor to take over the comments section. I only intended to make a general remark about some of the potential pitfalls regarding PEMT as a form of a remainder/note. The points I have tried to made are usually absent from the discussion about PEMT, so I felt the need to add them in the background for anyone interested.
I think that I said what I had to say on the subject (I actually have a lot more to say, but this is not the time or place), and therefore prefer to stop the discussion now and allow it to get back on the track of the original topic.
Just a couple of short comments about your last post:
1) The entire subject of PEMT should be discussed with a lot more transparency. Even those advocating it don’t seem to know a whole lot about it. Editing a translation in general is not like editing a monolingual text. To edit you need to first read the source, translate it, and compare that translation with the existing translation. This little and often ignored step of translating the source for comparison reasons is the core work of the translator; this is where his or her expertise lies. The mere fact that this is done in one’s head and not in writing doesn’t make this step less important and certainly not negligible. Again, translation is not about reading or writing words, it is about the cognitive process or capturing ideas and messages and expressing them. Otherwise, the PEMT-lobby would have targeted editors (who are the natural choice if this is a mere editing task, isn’t it?) and not translators perform this task.
The bottom line: if you do PEMT you stop being a translator because you will (quicker than claimed) lose your translation skills; you will develop your PEMT skills, but these two are not interchangeable. Again, there are years of accumulated experiences with post editing bad human translation to draw conclusions about the skill-loss, health and mental issues, and inefficiency involved – yet, no one seems to care too much to discuss them openly.
2) You asked how I work. I try to be flexible and find the most appropriate way to quote to make sure I get fully compensated for my work on the one hand, and that the client understand it on the other hand. It is a little different between agencies and direct client (the former differ further depending on their business sector and how they are used to “talk” business), but overall – and this is mostly how I work nowadays – I try to quote a per project fee after internally assessing and determining the effort involved.
3) MT is not going away, but I would disagree slightly about the reason for that. It is not here only by merit, but also because there is a huge money to be made here by some stakeholders who doesn’t necessarily understand or respect the profession and the importance of the service. Sure, MT has its uses, but their commercial scope is smaller than claimed by many. I also disagree about the claim that it will create more business opportunities (as opposed to opportunists), at least in the way it is being abused today which further devalues the profile pf the profession and important of the service in the eyes of the translation buyers (and this ultimately will come back to haunt many of the agencies now so avidly promoting it).
3) Yes, people need to get fairly compensated for their work; and yes again, true best practices are needed – those include an honest discussions about the limitations of MT and where is less appropriate. Unfortunately, judging from the cases one usually sees “in-the-wild”, this is not the case, and this is what made me comment in the first place.
I will not argue whether PEMT is true translation work or not.
But I do agree that the flaw of a tool just based on calculating the edit distance is that it doesn’t capture the time spent reading the source sentence, understanding it, reading the target translation and making a human judgment about its quality.
Let’s say the MT output was perfect, leading to nearly no post editing. Wouldn’t the post editor still spend valuable time determining that fact?
So I think these tools should look at BOTH the edit distance and the TIME spent until the “Reviewed” button is pressed by the post editor. Or, alternatively, the tool could determine an approximation of the complexity of the source sentence (how many words, how complex the vocabulary is, and many other factors). I’m sure some smart AI can do this kind of things these days (so not much in 2013 when this came out).
If I used that tool to determine how to pay a freelance post editor for his/her work, I worry that this could lead to a bad behavior from the post-editor where he/she would make some inconsequential changes, just to get paid, like changing “this” into “that” or “which” into “that”, etc.
I think a better use of that tool is for evaluation of MT engines. You want to compare 3 engines. You send the same text to translation through all 3 engines, get the text postedited by different translators, do some averaging and determine which engine requires the least amount of postediting, which hopefully correlates to its output quality. But again, even in that scenario, the TIME variable should be considered.
In all fairness, I have not used the tool, so it may be doing that, but not from what I seem to read in the help. I landed on this page because I was looking for a general purpose DIFF tool for SDLXLIFF files. Do SDLXLIFF files store timestamp of each TUs? If so, I would recommend this as improvement
Hi Michel, you picked a pretty old article to review!
Qualitivity may be what you’re after in this case… written several years later. It can be extremely granular and can record keystrokes, times in an out of segments, movement up and down the document, overall times in a segment etc. I think it’s a wonderful research tool, but in practice for your needs… doubtful. The reason I think this is because you need to get the translators permission before you can record this level of detail and most translators I have met in my career would be very reluctant to provide this for a commercial project.
Even more recent would be a more recent version of post-Edit Compare (there is a video here) where it was built into an application for comparing versions of a project within a new view in Studio. This adds time tracking capability to it if you want it. But again, requires the translators cooperation.
I sometimes wonder if the best approach to paying for post-editing isn’t to agree a time rate with trusted translators and use something like post-edit compare just to validate how much effort probably went into the post-editing. I think it would provide a reliable way of identifying what changes were made and you would be able to assess from that whether you wanted to continue working in more of a partnership with your post-editors or not, and it would be a safe way for the post-editors to be paid irrespective of the quality of the engines used. Certainly it would be a way of working that would not suit hawking the work around for the cheapest post-editors, but it would be a way of working where quality and realising the value of experienced professionals is key to getting good translations.
Hi Paul,
“Secondly a 58% post-edit analysis may not require the same effort as a 58% fuzzy from a traditional Translation Memory because there is no information provided to help the translator see what needs to be changed in the first place”
I would normally consider a 58% fuzzy match as completely useless (i.e., it’s faster to translate the segment again from scratch), so I would say that the effort needed to kick into shape a 58% fuzzy match and a machine translation that is the equivalent of a 58% fuzzy match is the same: normally they both need to be retranslated from scratch.
There is a good way to fairly compensate people engaged in post-editing: pay them by the hour, at fair hourly rates, without imposing a maximum number of hours per project, and provide them with (paid) good training before hand and detailed guidelines about the desired quality level for the project.
Hi Riccardo. You may be right… I was just illustrating the point with a 58% match. I guess if you did do it again from scratch then the analysis would see this because you’d delete the original rather than edit it. Actually that’s a stupid thing for me to say… I just tested this a little and no matter how you edit it (change individual words or delete the entire thing) the post-edit percentage is the same, and this is how it should be. So I guess the best approach in your case would be to simply set your cost bands to pay a 58% as a new translation if this is your experience. At the end of the day this is simply a tool to help you with getting payment, based on a post-edit analysis, that is commensurate with your own requirements. It has lots of other useful applications too… particularly with the new version that is integrated to Studio 2014, but it is just a tool and you use it in the way that works for you.
An hourly rate may also be a good way to go. I think this kind of mechanism works when you have a good trusting relationship between the work giver and the work doer… so long term post-editors perhaps.
Spot on, Riccardo. It’s amazing how much effort people go to creating contorted calculation models for “compensation” for these activities instead of simply paying for the time involved as one would for most forms of work. In fact, review (editing, proofreading, etc.) is usually compensated hourly except by the worst of the bottom barrel scrapers. If the MT engines cannot generate usable material, then that will be reflected easily and directly in the time involved revising it. I hope a lot of this work will be done by salaried employees as well, ones with good health insurance to cover the rehabilitation that will probably be necessary after engaging in these activities for a while.
Just on this part Kevin “… paying for the time involved as one would for most forms of work …”. I’m not pushing one payment mechanism over another as there are many ways to handle payment for work, but in my own experience I can’t relate to what you have said here. Twenty years in the construction industry taught me that hourly payments for work is a last resort… and at least in Construction this almost always resulted in much higher costs. It did happen, but usually only when there was no time for anything else. The most common method I came across was a Bill of Quantities, sort of like an analysis.
I think the most important thing is to make sure you are being recompensed adequately, and how you get there is fairly irrelevant. A post-edit analysis is just one method, and if you use it the important point would be that you worked to the analysis bands and rates you were comfortable with.
I think there are plenty of charlatans out there in every industry who pay low hourly rates, who pay low fixed costs and who pay low quantity based rates. The payment mechanism isn’t as important as the end result… in my opinion.
Hi Paul!
Great post! May we repost it under your name and with a link to your original post at http://translation-blog.com/ ? Many thanks!
Sure… it’s all about sharing!
Many thanks, Paul!
Is this new application available yet?
Yes… the links are in the blog. This one – Post-Edit Compare. The current version is standalone, but I imagine by next week there will be a new one for Studio 2014 only that has an excellent integration into the user interface for managing the project versions for compare.
Dear Paul/readers of this wonderful blog,
Has anyone tried downloading the tool, SDLXLIFF Compare, http://appstore.sdl.com/app/sdlxliff-compare/89/ and use it for Studio 2017?
I am not able to run it on my machine. Should I use Post-Edit Compare http://appstore.sdl.com/app/post-edit-compare/610/ instead? What are the main differences?
Kind regards,
David
Hello David, yes, I can use it on my machine. Did you review this article? It may answer both questions you have.
Dear Paul,
Thanks a lot for your reply!!
I finally found it under Files>SDLXLIFFCompare. Is it not possible it has more visibility; id est, I can find on the Welcome menu, or from the Windows search box?
Kind regards,
David
Dear David, the app is now a plugin, not a standalone tool. Are you sure you are not looking at the old one?
Dear Paul,
Dear Paul,
Thanks again!
I think I count on the current one. Version: 14.05821.4.
My question was if it was possible to find the plugin from the Welcome menu on Studio, or from the Windows search box, as I would do with SDLXLIFF toolkit, for instance.
It took me “ages” to find out the plugin was under Studio>Files>SDXLIFF Compare (next to Task History), but, as you are pointing out, and since this is not a standalone tool, I guess that’s the only way to find/use this tool.
At least I have just found out, it’s also in the View panel (under File Attributes). That’s at least something! 🙂
Regards,
David
Well… you’ve successfully confused me! The SDLXLIFF Toolkit and SDLXLIFF Compare are both plugins now. So if you did not have them installed previously you will not find them in any of the locations you mentioned here. They are both in the View Menu from Studio under the Information Group. You can then add them as dockable or floating windows that are always available as you work.
Maybe we’re talking the same thing but using different language!
We can’t add them to the Welcome menu as this is only for external applications that are just started from here. These are just links to the application and are not integrated tools at all.
So far so good! Hahaha! Just a little bit of misunderstanding!
I will use it from the View Menu. I am still so used to Studio 2014… The SDLXLIFF Toolkit I meant is still for Studio 2014! I will have to upgrade! 🙂
Thanks again a have a nice weekend!
Regards,
David
Hello Paul, I get this error when running a comparison (Studio 17), any idea?
“Input string was not in a correcet format”
Hi Paul,
I just found several reason to revisit this very interesting blog post and the ensuing discussion. Today, five years after your original posting, the matter of PEMT remuneration, and in particular the use of so-called post-analysis (in the same way as is done in Post-Edit Compare and with other, similar methods — Memsource is a big case in point) is being hotly discussed here in Sweden along much the same arguments as those that Shai brings forward.
Anyway: My first question concerns the Comparing Projects section above and in particular the last image. The reference to the Damerau-Levenshtein method is not much help to me since I don’t want to delve into it even if I could understand it. But in the next-to-last column in the image there are some interesting and also confusing figures. I can understand the rows “words”, “chars” and “tags”, and I also understand how the very last percentage is calculated based on the “distance” figures. But what stumps me is the step from what is above the “distance” row and that row itself. I assume that’s where the D-L method comes in, but it would certainly be helpful if you — and the program itself — would make some brief comment on this. (Obviously the calculation is based neither on the number of words changed nor the number of characters changed.)
My next question concerns your comparison with TM fuzzy matches, and this I believe is really interesting. There is a world of difference between the TM fuzzy match percentage and the edit distance D-L percentage, and one which I have never seen discussed, which is why I would appreciate your comments.
The TM fuzzy percentage indicates how much of the TM mach coincides with the source text, and which hence may be used (or “be useful”) in the target text. The post-edit modification percentage indicates how much was done by the translator/editor in order to produce a good target text — but it does not say much about how “useful” the MT suggestion was!
I’ll give you a simple example. Let’s say the MT suggestion consists of a 15 character compound word. The last 10 characters is a word that is perfectly “useful”, but unfortunately the target language is such that there is no simple equivalence to the first 5 characters and you have to replace that with three words totalling 25 characters.
Then the post-edit modifications would sum up to 25 new characters and 5 deleted ones. What that would amount to in the D-L analysis I don’t know, but I suspect it would come close to (25+5)/35, or 86%, giving a “fuzzy match” result of 14%. Not very impressive!
However, if I use the TM fuzzy perspective, I would note that out of the 15 MT characters, 10 were useful — or 10/15 = 67%! And that is actually quite impressive! Because while a 67% TM fuzzy match may be fairly useless (and is usually considered to be so by LSPs and freelance translators alike), such an MT mach may very well mean that out of a target segment totalling (in the end) let’s say 40 words, I may only have to type 13 — which is a big help! (This is not theory — I have many times noticed how useful MT hits are even if I have to do a fair amount of tweaking.)
To sum it up very briefly: While the edit distance tells something (but I agree with Shai — in many cases not very much) about how much editing work was done, it does not tell much about how useful the MT suggestion actually was. And I would like to see this (big) difference taken into account in discussions such as the above.
I’ll not go into the hairy issue of remuneration more than to say that I hope that in (probably a distant) future we translators can charge by the hour then the matter of edit distance will be a matter of theory only — whereas the matter of assessing TM and MT quality in advance of the work will always be important.
(When I first read this blog post years ago, I could not imagine how very relevant it would be years afterwards, when the quality of machine translation — and in particular neural MT — has made its uses much more widespread. Good work by you and Patrick!)
Mats
“But what stumps me is the step from what is above the “distance” row and that row itself”
I’m afraid this stumps me too Mats… I don’t understand what you mean?
“My next question concerns your comparison with TM fuzzy matches, and this I believe is really interesting. There is a world of difference between the TM fuzzy match percentage and the edit distance D-L percentage, and one which I have never seen discussed, which is why I would appreciate your comments.”
I wonder if you are over complicating this? TM fuzzy match represents the difference between the source segment in your TM and the source segment in the document you are translating. Edit distance represents the number of changes the translator had to make in order to correct the target that was automatically inserted into the translation either from your TM or from an MT result. What this does show is how a fuzzy match could easily be a very poor representation of the effort that is actually required and this could mean two things. You do well by getting paid for significantly less effort than expected, or it goes the other way and the effort is a lot more.
“To sum it up very briefly: While the edit distance tells something (but I agree with Shai — in many cases not very much) about how much editing work was done, it does not tell much about how useful the MT suggestion actually was. And I would like to see this (big) difference taken into account in discussions such as the above.”
Do you have a suggestion as to how a calculated number based on an edit of some words could tell you how useful the MT suggestion was? In simple terms if you only have to edit a few chars then the suggestion was probably useful. But this is hardly an infallible approach since people are not fallable either. The same sentence translated by several translators could easily produce different edit distance results.
Sorry — I see I need to amend my posting slightly to make it clearer. The simple example in the fourth paragraph should read: Let’s say the MT suggestion consists of a 5 character and a 10 character word. The last one is perfectly “useful”, but unfortunately the first one is rather off-target and has to be replaced with three words totalling 25 characters.
Thank for your comments, Paul,
In my first question I should have mentioned which image I referred to. It is the fifth one, and the comment concerns the step from (in segment 16 of the example) “words: +10 -5 / chars: +53 -21” to the bottom line “distance: 49 / 74”. I realize an algorithm is at work here, but some sort of indication as to the relationship would be welcome.
Your final comment is correct, of course, as is Shai’s in general. As for “how a calculated number based on an edit of some words could tell you how useful the MT suggestion was”, my point is the opposite: the usefulness would rather be indicated by how much of the MT suggestion is retained — not by how many words/characters have to be edited. If I can use 100 characters of the suggestion unchanged, then I am saved that may keystrokes, no matter how much I have to edit the rest of that suggestion. (On the other hand, this says nothing of the cognitive effort needed for the editing or for the decision to retain part of the MT suggestion.)
Hi Paul!
Thanks for this entry. I have a question though, do you think status need to be the same (both versions with all segments translated instead of draft or approved for example) in order for the modified percentage to be relevant? It seems like if the status is changed in the postedited version the software interprets a change anyway, even if the text is the same. I am having issues with this since Post Edit shows 100% modified AT segments when this is not true, some segments do not have any track changes when analized independently per file below.
Any clarification regarding this issue will be appreciated.
Thanks,
Marta