 Ever since the release of Studio 2009 we have had the concept of Language Resource Templates, and ever since the release of Studio 2009 I’d risk a bet that most users don’t know what they’re for or how to use them. To be fair this is hardly a surprise since their use is actually quite limited out of the box and access to the goodies inside is pretty hard to get at. It’s been something I used to see users complain about a long time ago but for some years now I rarely see them mentioned anymore. This article, I hope, might change that.
Ever since the release of Studio 2009 we have had the concept of Language Resource Templates, and ever since the release of Studio 2009 I’d risk a bet that most users don’t know what they’re for or how to use them. To be fair this is hardly a surprise since their use is actually quite limited out of the box and access to the goodies inside is pretty hard to get at. It’s been something I used to see users complain about a long time ago but for some years now I rarely see them mentioned anymore. This article, I hope, might change that.
Tag: segmentation
Slicing fruit!
 If there’s one thing I firmly believe it’s that I think all translators should learn a little bit of regex, or regular expressions. In fact it probably wouldn’t hurt anyone to know how to use them a little bit simply because they are so useful for manipulating text, especially when it comes to working in and out of spreadsheets. When I started to think about this article today I was thinking about how to slice up text so that it’s better segmented for translation; and I was thinking about what data to use. I settled on lists of data as this sort of question comes up quite often in the community and to create some sample files I used this wikipedia page. It’s a good list, so I copied it as plain text straight into Excel which got me a column of fruit formatted exactly as I would like to see it if I was translating it, one fruit per segment. But as I wanted to replcate the sort of lists we see translators getting from their customers I copied the list into a text editor and used regex to replace the hard returns (
If there’s one thing I firmly believe it’s that I think all translators should learn a little bit of regex, or regular expressions. In fact it probably wouldn’t hurt anyone to know how to use them a little bit simply because they are so useful for manipulating text, especially when it comes to working in and out of spreadsheets. When I started to think about this article today I was thinking about how to slice up text so that it’s better segmented for translation; and I was thinking about what data to use. I settled on lists of data as this sort of question comes up quite often in the community and to create some sample files I used this wikipedia page. It’s a good list, so I copied it as plain text straight into Excel which got me a column of fruit formatted exactly as I would like to see it if I was translating it, one fruit per segment. But as I wanted to replcate the sort of lists we see translators getting from their customers I copied the list into a text editor and used regex to replace the hard returns (
) with a comma and a space, then broke the file up alphabetically… took me around a minute to do. I’m pretty sure that kind of simple manipulation would be useful for many people in all walks of life. But I digress….
Segacious segmentation…
 Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Working with Studio Alignment
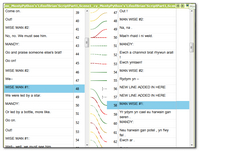 Note to the wise: This article is quite some years old now and the alignment tool has improved a lot with many more useful capabilities since Trados Studio 2021. But there may still be some value in this one so I’m leaving it here for posterity!
Note to the wise: This article is quite some years old now and the alignment tool has improved a lot with many more useful capabilities since Trados Studio 2021. But there may still be some value in this one so I’m leaving it here for posterity!
The new alignment tool in Studio SP1 has certainly attracted a lot of attention, some good, some not so good… and some where learning a few little tricks might go a long way towards improving the experience of working with it. As with all software releases, the features around this tool will be continually enhanced and I expect to see more improvements later this year. But I thought it would be useful to step back a bit because I don’t think it’s that bad!
When Studio 2009 was first launched one of the first things that many users asked for was a replacement alignment tool for WinAlign. WinAlign has been around since I don’t know when, but it no longer supports the modern file formats that are supported in Studio so it has been overdue for an update for a long time.
Translating Literature…
 As I’m writing this I can hear the cry of “Use a CAT tool for translating literature, or prose… no way!” This is a discussion I see from time to time and there are some pretty strong feelings on this subject for a number of reasons. One of the reasons given is that you cannot take this type of material sentence by sentence and just do a literal translation. Other reasons may be more detail around this same point, and also touch on the need for a creative flow because this type of translation requires a very creative writing style rather than literally translating the words.
As I’m writing this I can hear the cry of “Use a CAT tool for translating literature, or prose… no way!” This is a discussion I see from time to time and there are some pretty strong feelings on this subject for a number of reasons. One of the reasons given is that you cannot take this type of material sentence by sentence and just do a literal translation. Other reasons may be more detail around this same point, and also touch on the need for a creative flow because this type of translation requires a very creative writing style rather than literally translating the words.
Continue reading “Translating Literature…”