 By now I think we’ve discussed the import of an IATE TBX into CAT tools as much as we can without going over old ground again. But if you’re reading this and don’t know what I’m talking about then perhaps review these two articles first:
By now I think we’ve discussed the import of an IATE TBX into CAT tools as much as we can without going over old ground again. But if you’re reading this and don’t know what I’m talking about then perhaps review these two articles first:
What a whopper! – which is all about the difficulties of handling a TBX the size of the one that is available from the IATE download site.
A few bilingual TBX resources – which is a short article sharing a few of the TBX files I extracted for a few users who were having problems dealing with the 2.2Gb, 8 million term whopper we started with.
So why am I bringing this up again? Well I do like to have the last word… don’t we all… but this time I wanted to share the work of Henk Sanderson who has put a lot of time and effort into breaking the IATE TBX into bite sized chunks and at the same time cleaning them up so they can be more useful to a translator. I also wanted to share the successful import of the complete original TBX from IATE directly into MultiTerm Server:
That’s pretty impressive, and this was imported by our Product Manager Luis Lopes after the developer of the Glossary Converter created a new version that can handle the conversion of the full TBX to MultiTerm XML in one go! So if we have this now then why was it necessary for Henk to provide anything else you ask? Well it’s a very good question and Henk has gone into quite some detail on his website to explain what he’s done. But in a nutshell not everyone has MultiTerm, and not everyone has MultiTerm Server… and then there’s the quality of the data! So taking the titles from his website we see why the work he has done is worthwhile for translators using other tools as well as those using MultiTerm.
Contents
Handling of synonyms
 Sometimes the synonyms in the TBX have not been entered correctly. So you might have several synonyms written as one term but separated by a semicolon for example. Henk shows an example on his website in the TBX. I checked this in the TBX import to MultiTerm and sure enough this is exactly what we see.
Sometimes the synonyms in the TBX have not been entered correctly. So you might have several synonyms written as one term but separated by a semicolon for example. Henk shows an example on his website in the TBX. I checked this in the TBX import to MultiTerm and sure enough this is exactly what we see.
The cleaned up TBX you can expect from Henk separates these so they are properly written as synonyms with two terms for the one concept as opposed to what you see here which is not very helpful when you are translating.
Poor recording of context

Sometimes the person who entered the original data added context about the term by adding the context in square brackets after the term. This is also incorrect as there should be an additional field for this kind of information.
I was unable to find the example Henk used but I did come across many other examples like these. The information might be quite useful to know, but if you were using this for AutoSuggest to improve your productivity you’d get pretty fed up having to delete the unwanted information. No doubt you’d clean this up as you went but it would be frustrating, and if you were using the information in a TMX which is something else Henk has provided then this would contribute to some fairly poor matching.
Erroneous tagging within the terms

There are instances of where html code has been used within the term. Here I found the same example Henk used and you can see how the import to MultiTerm without cleaning it up first displays the code as text.
I wouldn’t be surprised if some tools failed to import these at all so MultiTerm has done a fairly good job of this but it is clearly undesirable.
Lack of accurate, or descriptive codes
The IATE TBX contains subject field codes to represent a Domain, but unless you swallowed the book of Domain Field Codes and their Descriptions and memorised some 700 codes then you probably wouldn’t know that 3206 was Education. The image on the left is how the record looks when you import the raw TBX into MultiTerm and the one on the right comes from Henks extraction. So he has gone to a lot of trouble to make the data more meaningful by identifying the codes.

But that’s not all because apparently the raw TBX also contains a lot of codes not listed in the published IATE dictionary so Henk has done some work to fill these gaps too.
Invalid XML

Here I don’t have an example because we had to remove the invalid code from the TBX before we could even start. So the fact Henk has spent time doing this on all the files he prepares will save you a lot of time and frustration when the invalid characters cause the import to fail altogether. I have stolen the image on Henks site so you get an idea of what this is all about.
Large number of unwanted acronyms & 1/2/3 letter words
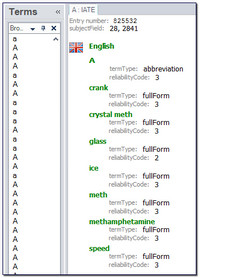
The imported TBX contains huge numbers of single letters, or very short “words” made up of only a few short characters. Whilst MultiTerm will ignore these when you translate it’s still an unnecessary waste of resources to have to deal with them in the first place, especially as so many of them are simply wrong. So the cleaned up TBX from Henk does not contain these at all and the Termbase you create will be far leaner and relevant.
Long text entries
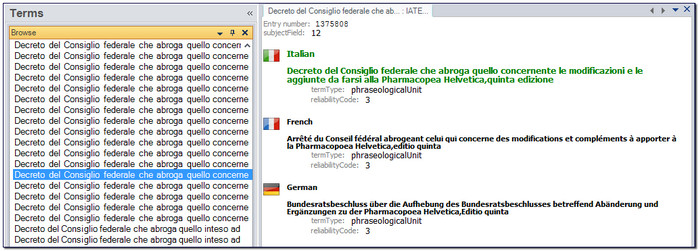
The complete opposite of the previous problem is having to work with entries that probably should not be in a Termbase in the first place. So for example the screenshot above shows hundreds of slightly different translations of complete sentences that should probably be in a Translation Memory as opposed to a Termbase, and that is exactly what Henk has done.
Summary
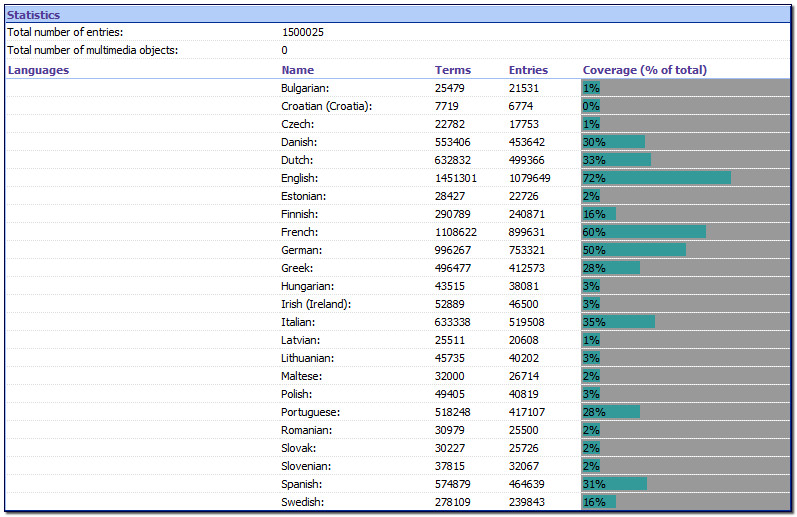
So whilst MultiTerm Server can handle the TBX as it is with 24 languages, 1,500,025 entries (7,966,751 terms) in one termbase I think the practical aspects of this will show that it still needs considerable cleaning up to be useful and not a frustrating and ongoing maintenance project. I think this applies to all Translation Environments since the motto “Garbage In Garbage Out” applies here. There is a lot of good data to be found and used, but it will be an ongoing cleaning exercise for all but the most determined users.
I’d recommend you take a look at the work Henk has done because it could provide you with the means to enjoy a far better experience with this resource from IATE, and it won’t cost the earth! He has also prepared the data in less complex ways for simpler tools to be able to use as well. So if you have been trying to handle the IATE TBX file, or have been thinking about making a start, I’d recommend you pay a visit to Henks website where you’ll find some very clever solutions to improving the quality of the data and making it more usable… no matter what your chosen Translation Environment is!
I think Henk really had the last word!
I use Henks work for my language combinations (PL-NL and EN-NL, sometimes DE-NL annd ES-NL) painlessly in MemoQ. Works like a charm!
FYI, Translated has loaded the TBX as a TMX into MyMemory, doing all the necessary cleaning.
It still lacks context information (rolling it out soon in next version), but it’s free and available to everybody.
Cheers
You can find a 7500 word paper on the numerous issues of IATE and its use by TENT tools. The study is focused on Greek, but similar issues afflict other languages too.