 When I used to study maths as a boy my Father, who was an engineer and very straightforward in his views, always used to say 100% was the best you could give. It meant everything, so there was no more. Any talk of giving 101% for example wouldn’t be entertained for a second because you clearly hadn’t given 100% in the first place. It wasn’t possible and anyone who said otherwise was probably in marketing or sales!
When I used to study maths as a boy my Father, who was an engineer and very straightforward in his views, always used to say 100% was the best you could give. It meant everything, so there was no more. Any talk of giving 101% for example wouldn’t be entertained for a second because you clearly hadn’t given 100% in the first place. It wasn’t possible and anyone who said otherwise was probably in marketing or sales!
Whilst much of his influence lives on in me today I am a little more accepting of many things, and in particular why 100% isn’t enough, or at least why there’s a need for more. At least in terms of translation matching! So this article is a discussion around matching and I hope at the end of this you’ll understand some of the terminology we use when working with SDL Trados Studio and the effect it can have as you work.
BE WARNED… IT’S A LONG POST!
So let’s start off with matching in general and to do this we can take the following simple sentence:
The Project Manager works on location 3-days a week.
If this was translated into German it might be written like this:
Der Projektmanager arbeitet 3 Tage pro Woche vor Ort.
If I store that translation into my Translation Memory and later on I come across a sentence like this:
The Project Manager works 3-days a week.
Then I might expect to get what we call a fuzzy match. This means a match that is less than 100% but more than 0% because there is something similar about the sentence when compared to something you translated before. The measure of similarity is the match value. In practice Studio will only go down as far as 30% because anything less is generally unusable in practice. In Studio it would look like this and you can see I get an 84% fuzzy match because the translation should be “Der Projektmanager arbeitet 3 Tage pro Woche.” without the “vor Ort”

If I confirm the correct translation, so add “Der Projektmanager arbeitet 3 Tage pro Woche.” into the translation memory, then you’ll see that I now get two matches for these sentences when I come across them again in a document:

Now, if my text actually said this:
Rules for James: PROJECT MANAGER The Project Manager works on location 3-days a week.
Then I would expect to see a 100% match for the third segment and it would be correct. But if my text said this:
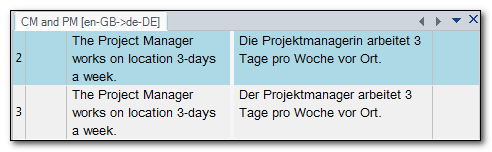
Rules for Sally: PROJECT MANAGER The Project Manager works on location 3-days a week.
Then the 100% translation would be incorrect because here the gender changes and the translation should be:
Die Projektmanagerin arbeitet 3 Tage pro Woche vor Ort.
This is a different translation because of the context which means all of a sudden 100% is not enough! So in order to allow for some disambiguation our development team (who must have known my Father and his views on a 101% match) decided to call this a Context Match when you know the context of the translation. A very important point however is that in order to ensure you can do this without adding the segment as a new translation, so relying on the context alone, you must be quite specific about your settings. So this is what I used:
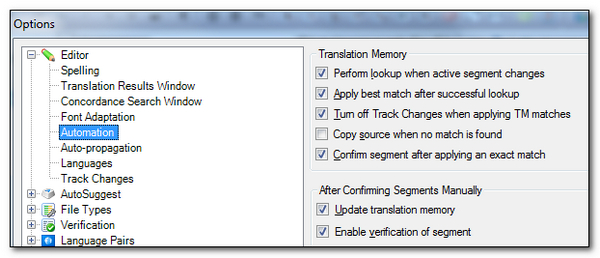
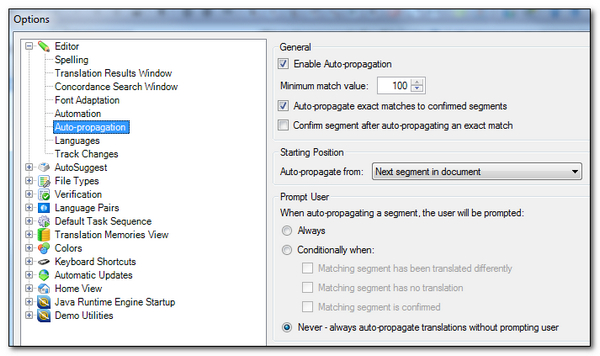
So if I translate the three segments when James is the Project Manager and add this information to my Translation Memory then I might get this effect as I translate:
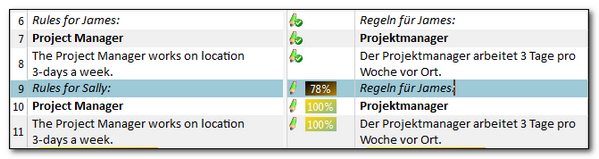
You can see that segments #10 and #11 are autopropagated 100% matches because they have a different context to segments #7 and #8. You know they are autopropagated because of the colour of the 100% match (this is configurable so you might see a different colour).
If I activate segment #7 (and apply the translation from the TM so the match value is added to the centre column) we have a 100% match as we’ve translated “PROJECT MANAGER” before and then we also have the same preceding segment (#6) for the source and the target. So the highlighted cells shown below match, making “PROJEKTMANAGER” a CM, or Context Match:

Similarly if we look at segment #8 we see the same pattern making this a CM as well:

If we look at segments #10 and #11 these are both 100% matches because they don’t match the criteria of having the same translation in the preceding segment. Typically in most other CAT tools segment #11 might still be considered their equivalent of a CM match (sometimes referred to as a 101% Match) because the target translation is not taken into consideration. So to correctly handle these segments for Sally we correct the translations and save them again by confirming the segments (Note: I did not add as a new translation) so that we now see this:

Note that we see both possible translations in the Translation Memory Results window at the top but that the correct context is recognised and inserted automatically into the document. Similarly if I activate segment #11 I see this:
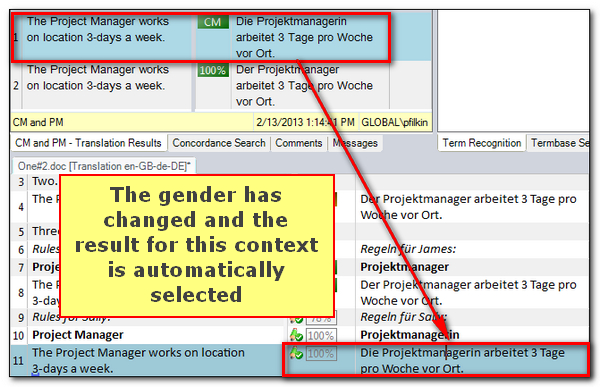
This concept of disambiguation is further enhanced between 100% matches too by using the Document Structure Information in the right hand column of Studio… so this one:
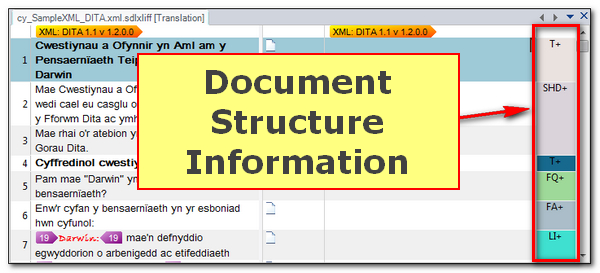
The basic idea is that when you have multiple 100% matches the Document Structure Information can be used to automatically ensure the correct 100% match value is presented first. This is far easier to explain with a video so Daniel Brockman kindly provided one for me with a very clear example of what this means:
I do have one more interesting thing to note after receiving a question from one of our resellers about why a TU is sometimes added to your TM when you work and why it is sometimes not. The reason is linked to the Context Match again but I better explain the situation first.
Let’s take the following example:

If I confirm segment #1 and look in my TM I see one translation at TU number #1.

If I then edit this same segment with a different translation and confirm it again I still only have one TU, but now it’s numbered TU number #2 because the database recognises this is an edited TU in the same context and replaces the first one with a completely new addition to the TM:

If I then translate segment #2 which is the same source as segment #1, but a different context, with a different translation and confirm it like this:

I will actually get a new TU like this, rather than simply overwriting the original:
So the context of your translation is very important for a number of ways to help improve the surety of your Translation Memory leverage when working and also to minimise the amount of unnecessary TUs added to your TM as you work. You may also have just found an explanation for the numbering of your TM not always being consecutive throughout the file when viewed in the TM Maintenance window.
The next part of this matching discussion should cover Perfect Match… but I think I’ll leave that for a separate article in the future… and also take it as a reminder it’s Valentines Day tomorrow and I’m in big trouble!
Thanks Paul, this is really interesting. I seem to remember that you mentioned a source file checker a while back but I haven’t been able to find it on the open exchange. Have I remembered this correctly? I’ve been asked to translate some very heavily formatted MS Word files in Studio and would like to run the check as I am worried that I might have problems cleaning the files at the end and would like to be prepared! Many thanks in advance, J.
Hi Jane, I may have mentioned a couple of tools for this. We have secureSDLXLIFF on the OpenExchange, but I think I may have also mentioned http://asap-traduction.com/CodeZapper at some point. Both are useful tools. secureSDLXLIFF does a lot more than CodeZapper as it’s designed for more things, and neither are free… but not expensive either.
Regards
Paul
Many thanks for your help Paul! I’ll look into these two.
Best wishes, Jane
Hello Paul,
Is there a way to batch delete translations from a batch of the SDLXLIFF files? I know I can delete all target segments by opening each file and running the respective command. But I’d really like to use a batch command this time on a batch of files.
Thank you in advance,
Best wishes,
Roman
http://www.velior.ru/blog/en
twitter.com/veliortrans
Good question… but no. You could do a complete file in one go with a shortcut but not a batch. Probably easier to recreate the project with the source files and an empty TM… or the source language sdlxliff files. It’s a good idea though… I have some thoughts around an app to do many things with an sdlxliff so I’ll steal your idea and it to the functionality I’d like 😉
Hi Roman, just thought I’d update this as I was reminded of your comment just now. The app I referred to has been released with Studio 2014… The SDLXLIFF Toolkit.
Dear Paul,
I have encountered a bug in Studio 2014 when a segment with locked content doesn’t get propagated properly. For some reason, tag content gets propagated as a plain text. I translate a segment, confirm it, but then, when I move to the next segment (which is completely identical to the one before), instead of tags I get tag content as normal text. Any clues on this?
If I run the same project in Studio 2011, propagation works properly.
Dear Dace… not something I’ve come across, but if you can send me a small example I’ll happily take a look? mailme.
Interesting Paul. There are 2 things I wonder about:
Does your method on having different translations without specifically choosing to Add as new TU lead to the same storage in the TM than if you had chosen the Add as new TU?
I also wonder if your explanation of using Document Structure Information only works if the Purpose of the Doc Structure is set to “Match” or “Information” in the advanced properties of the XML filetype.
Hi Paul, I’m about to ask support that question again. Could you please answer if you see it here? Thanks!
Thank you for this post. My question is: why can’t I see all 100 % matches? I often get a TM from the client which partly overlaps with my own TM. However, my own TM contains some extra information in the form of a note (e.g. an EU Celex number). I noticed that if the source and target segment of the TU are identical, the Translation Results Pane shows only one 100 % match. Preferably I’d like to see all of them, so I can see the info I put in the note. Is that possible?
Hi Mark, have you tried changing the setting under File -> Options -> All Language pairs -> Translation Memory and Automated Translation -> Search, and then check the box “Search for fuzzy matches even if exact match found”? Alternatively prioritise your TM by putting your own TM at the top of the list.
Great post, I often refer people to it.
One comment: this would be so much easier in Trados if there was an advanced setting to actually view the metadata that Trados stores to decide what is a 100% vs a CM. Right now, the only way to find that out is to look at a TMX export! Hide it by default if you think it will confuse newbies, but please give advanced users a way to see it, and perhaps even to control/modify it inside Studio.
And last question: Is SDL ever considering using something else than the previous sement+translation as context for the ContextMatch. In SW, the context is often a key, not the previous segment which can vary. I wish SDL would come up with this, it would be such an improvement for SW localization. Only Passolo does this, but I really dont want Passolo in my toolchain.
Thanks Michel… pretty old now but hopefully most of it is still helpful.
On the idea of exposing the context values. We discussed this a little today and didn’t see a lot of value in exposing it, or how we would do this in a useful way. There could be multiple context values stored against a TU and information is often just a hash value as opposed to anything readable. The best we could come up with was that under the TM Maintenance window you might be able to remove entries that you don’t wish to be used as context anymore… or something like that.
I think the best approach would be for you to suggest this in the ideas site and also explain where you see the value is for you as this would help provide more context to base a decision upon.
On the question of id-based matching. This has been discussed in the past and is still a work in progress that hasn’t taken any serious priority over other work. I think your best bet here is too raise this as an idea as well. There may even be an existing one since WorldServer also does something similar and this was possibly the driver to do this in Studio.
In addition Paul, I dont know if things have changed in Studio since you wrote this in 2013, but I can absolutely NOT reproduce what you say about creating a new TU without using “Add as new TU”.
The fact that the context is different seems to be irrelevant to Trados, which simply overwrites the TU with the new translation (the feminine form for Sally) and I lose the masculine form for James.
I would really like to clarify this, this seems to be a very important point in your blog, but it doesnt work like that for me.
Hi Michel, apologies for the delay in responding. When I tested quickly with Trados Studio 2021 I had the same experience and could not figure out why. So I raised this with the product manager and he managed to achieve it by disabling auto-propagation altogether. It looks like applying any kind of result takes place “too fast” for the disambiguation to take place and you lose the ability to add as a new TU without explicitly “Adding as new TU”. If you disable the auto-propagation then it works as noted in the article.
This is clearly not ideal as this is a great feature and most users won’t want to lose the auto-propagation. So for the time being, until this gets resolved you need to be diligent and use “Add as new TU” and then you at least get the advantage of disambiguation and improved leveraging for future translations.
Thanks for coming back to this one. I think we all get so engrossed in everything new we often forget the bread and butter stuff and it is so important.