 If you were a user of SDL Trados 2007 or earlier you will probably be familiar with the concept of “Fields and Attributes”… if you are a new user to this kind of technology then you may not be. But in both cases I hope this article will provide a little bit of useful information on how they are used in Studio.
If you were a user of SDL Trados 2007 or earlier you will probably be familiar with the concept of “Fields and Attributes”… if you are a new user to this kind of technology then you may not be. But in both cases I hope this article will provide a little bit of useful information on how they are used in Studio.
I used a picture on the left of a filing system because this is how I see them. They are simply a way to organise the translation units that are saved into a Translation Memory so that you can easily find them as your Translation Memory grows and your biological memory fails 😉
In the olden days of SDL Trados 2007 and earlier these were a necessary requirement if you wanted to avoid having separate Translation Memories for each client. This is because the old technology could only use one Translation Memory at a time… in Studio of course this is not a problem because you can add as many Translation Memories as you like to a Project. So in the past users would typically create “Fields and Attributes” relating to things like Client Name, Project Number or Topic. They would then update their Translation Memory with the values for these things as they worked on a particular translation and this made it possible to do things like export a Translation Memory consisting only of Translation Units for one specific client for example. This same principle can still be used today in Studio and you would do this in the Fields and Settings for your Translation Memory.
To try and explain this a bit better I set up a filing system based on me translating about dogs… Terriers in fact as these are my favourite breed. So I have several clients, each one gives me work based on a project code that changes each time, I like to be able to ensure the relevance of the memories by breed and I also share work from time to time with other translators. Last but not least, even though I could use the created date to ensure I got my recent translations first I also like to save them by year. So my filing system might look a little like this:
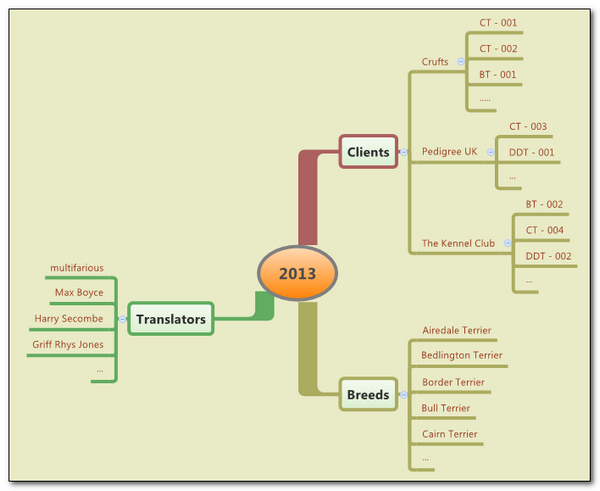
I could have drawn this a number of ways, but it’s actually quite tricky to reflect something like this usefully in a physical filing system because in order to be able to select all the work done for a particular client in a particular year, by a specific translator and about a particular type of Terrier I’d have to be very diligent about filing things away and organising my work carefully. It’s no different when you do it virtually in a computer, you still need to have an idea about how you want to organise your filing and how you might wish to retrieve the information in the future. But the computer can help you considerably with the relationships between the different “Fields and Attributes”.
So how do I reflect this in Studio? Well here’s one I created earlier… as a child I was a Blue Peter fan and if anyone can remember Shep you’ll know how long ago that was 😉 You can find this dialogue by right-clicking on Translation Memory in the Translation Memories View, select Settings and then click on the Fields and Settings node:
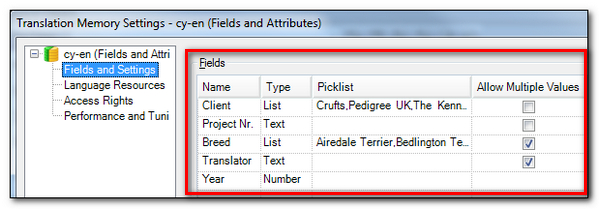
There are four headings across the top: Name, Type, Picklist and Allow Multiple Values. The Type column refers to the type of field, and this can be one of the following:
- Text : This is a free text field allowing you to add whatever you like whenever you update a translation. I’m using this for my Project Codes as these could be anything and it’s easier to maintain when it changes with every job.
- Number : This would be used if you wanted only numbers to be used. So there are controls in place to prevent you entering anything that is not a 0 through to 9. I’m using this for the year the work is being done. Might be particularly useful for numeric product codes for example.
- Date/Time : Provides a calendar like approach to picking a date. I’m not using this but if I was it would be an easy way to add the time and date I was working on a translation as a field value.
- List : This provides the ability to specify one or more field values from a list. I’ve used this for my clients and specific breed of dog because these are pretty much stable fields and having them in a drop down list makes it easier for me to ensure I don’t misspell anything and have duplicates in my Translation Units.
The Attributes are the values in the Picklist column, and they are the values that I enter before I start translating for the Project, Translator and Year Fields.
I also have a column called Allow Multiple Values and using this simply allows me to have several values for the fields I checked against a single Translation Unit… hopefully this will become clear as you read on.
So, I receive some files to translate and I set up my Project in Studio (or I can do them one at a time using Open Document – single file project). Then before I translate a single word I set the update values here in my Project Settings:
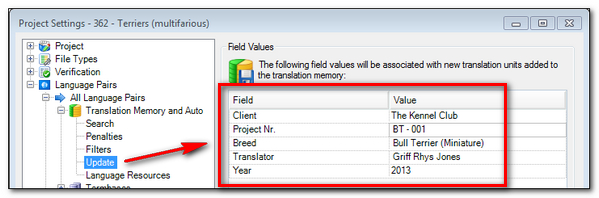
Note this is my Project Settings. If I do this under Tools Options after creating the Project anything I use will have no effect at all.
The Fields that were based on Picklists will contain Attributes I can choose from a selection like this for example:
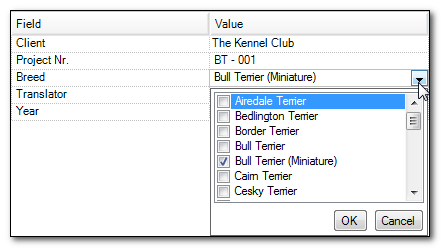
If the Allow Multiple Values was ticked when I set these up then I would also be able to select several types of Terrier too. Which I might do if the text referred to several types. The other Field values not based on Picklists are just typed in.
Now I can start to translate and when I do I see that these values are reflected in the Translation Memory View for each segment I confirm. So I now see this sort of thing where the Fields and Attributes are stored against the Translation Unit in my Translation Memory:
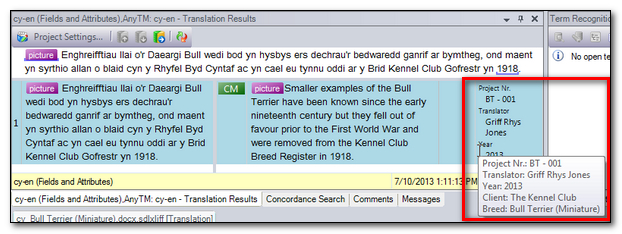
Where I have allowed Multiple Values to be used then these are all stored against the same Translation Unit:

IMPORTANT NOTE : You must be very careful about your choice of Allowing Multiple Values because if a Field does not have this value checked then it will overwrite the previous Translation Unit in your Translation Memory unless you Add as New Translation and this means you making the conscious decision to use Ctrl+Shift+U rather than Ctrl+Enter as you are translating and this is probably going to be something you can easily forget as you work quickly through the file.
So in this example so far the Translation Unit is saved with the latest values for Project Nr., Year and Client. This is also something I really don’t want because in order to be able to extract Translation Units for a specific Project for example I can’t overwrite this value or I will lose the ability to select a different Project Nr. I also don’t want this to be added as a new Translation Unit because I may want to extract all Translation Units for a specific Client and then not have to select every single possible value for the Project that might be associated with it. So I would go back and change the setting for the Project Nr. Field so that it allowed multiple values.

Oh oh! So realising you made a mistake in how you set up the Fields and Attributes later on could have potentially damaging effects. If you’d been working with this for years for example it would be pretty damaging to lose all the careful filing from over the years. So the lesson here is that you must be very careful in engineering your filing system at the start. And another tip would be to not get carried away with what is possible… rather keep it simple and then you are less likely to run into problems and more likely to be able to do useful things with it.
What can you do about it? Well for the rock steady Translators who don’t like to get under the hood the easiest thing to do is to create a new Field and allow multiple values. Then use this one instead going forward. When you set the update just leave the old field blank and this way it won’t be touched… so for example I can do this:
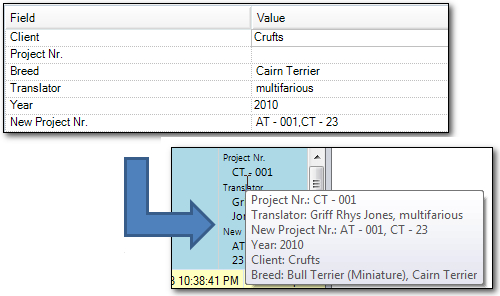
The end result is that when I want to extract by Project Nr. I now have two Fields and Attributes to choose from.
For the daring geeky types out there you can export the entire SDLTM to TMX and work a little magic with search and replace in a text editor… but I’ll leave that for another article if anyone wants to know and doesn’t know where to start!
Contents
So now what?
I’ve now written quite a bit and you may still be wondering what you would do all of this for anyway? Why not just use multiple Translation Memories? Of course, in my opinion this can be the best approach, particularly if you maintain a separate Translation Memory for each client you work for. Furthermore the ability to use a Project Translation Memory in Studio makes it really easy to have a ready made memory to hand over to your client at the end of each project. There are even more applications on the OpenExchange that make it simple to convert your bilingual files into Translation Memories, so there are many ways to handle a simple requirement without using Fields and Attributes at all. But…. if you did then here’s a few examples of what you could do…
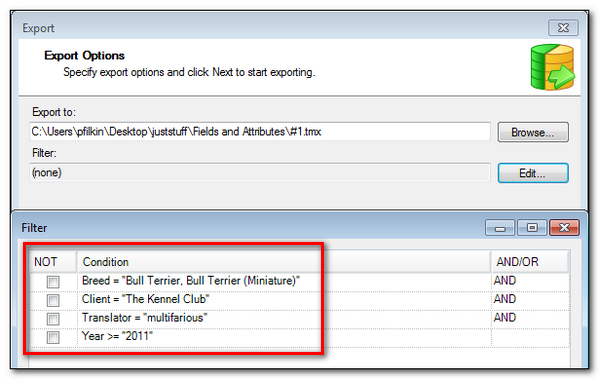
Export part of your Translation Memory
Export to a TMX (Translation Memory eXchange file) all the work you have done since 2011 for “The Kennel Club” about all types of Bull Terriers:
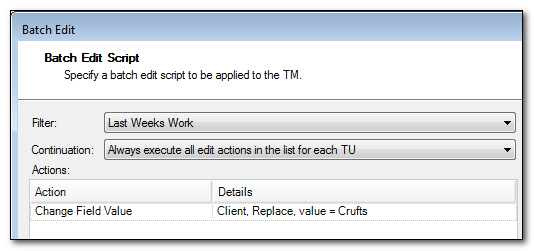
Change many Fields and Attributes in one go
You could create a filter for all work completed in the last week and then use this filter to change all the Field values for your Client Field because you mistakenly used the wrong value! So like this all the values used for the Client Field in the last week will be changed to “Crufts”. You would create and save the filter first in the Translation Memories View with the Translation Memory open, and then close the Translation Memory and right-click to get the Batch Edit menu here:
Delete part of your Translation Memory in a controlled way
You imported a TM provided to you by your colleague Max and updated it against his name. You then discover that whilst the translations were all good, the material was mostly irrelevant so you didn’t want it in there any more. You need to create a filter again as before (this time based on the translator called Max and saved as a filter called Max Translations), but then you can select it here like this:
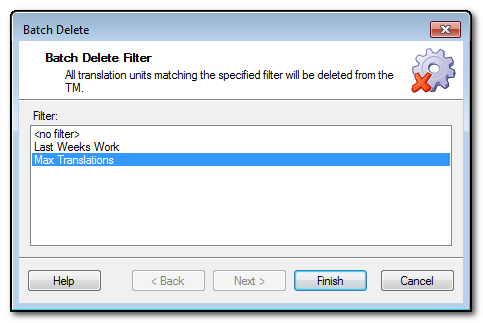
Ensure you only use relevant parts of your Translation Memory
You find that as you are translating a particular job you are getting results from your TM and from a specific Translator in 2008 that are not as relevant as the translations you know you did last week! So you can apply a penalty based on a filter so that results returned from the Translation Memory as you work will be penalised and therefore show up further down the list than the more recent ones you want:
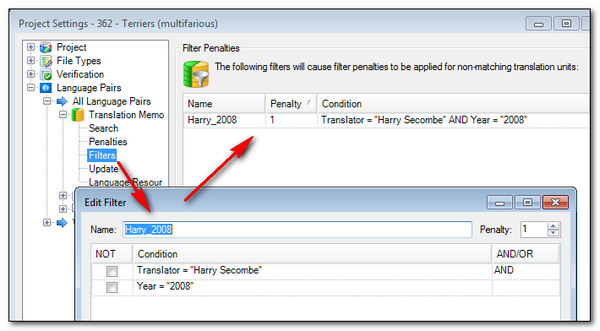
Hopefully you get the idea? This whole area around maximising the use of your Translation Memory resources, and filing away the Translation Units in such a way that they are useful for you is a pretty big subject. But maybe this article has been of interest and given you a few ideas if you haven’t used Fields and Attributes before.
But just to finish off this rather long article I’d like to mention again the principle of keeping it simple. Don’t use these if you don’t have to or can’t see a reason based on the way you work. But if reading this article helps you to see a way to do some things you always wanted to but didn’t know how then remember… simple is best!
Hi Paul,
just a tip concerning the issue with unique or multiple values in a picklist. You can by means of workarounds of course transform a multiple-value attribute field into a unique-value field without losing any information. This is often required after upgrading legacy TMs, since multi-value fields were easier to overwrite/merge in Workbench than in Studio. So if you have, say, a status attribute field from an upgraded Workbench TM it will allow multiple values in Studio, which is not good.
In Translation Memories, you need to create new interim fields, use batch operations to filter and export one attribute value from the multi-value field to the interim field. Repeat this process until all values from the multi-value field have been copied to the interim fields. Then change the setup of the multi-value field to unique value. Next, reverse the process and filter for the interim fields and copy the values to the now unique-value status field. Repeat for each interim field. Then delete the interim fields. Presto. 🙂
Just like that! Great tip Andreas… clearly you’re the man to ask for advice when migrating from legacy TMs! Thank you for posting and sharing your experience here.
Thanks for the explanation about “allow multiple values”. At last I’ve realised why one of the fields I defined ages ago keeps growing and growing. I can put a stop to that now.
PS I was very fond of Shep 😉
Me too! Can you remember the song? Glad this helped you Emma… I like it when there’s something in here even for experienced users like you.
Ironically Paul I was just talking to someone about Fields and Attributes last week in relation to Machine Translation. The client was using BeGlobal Trainer to build a customized engine for automated translation but although he had many different workflows and product lines in his organisation, he had historically bundled all the bilingual content in one massive TM. He wanted to know if there was a way he could now split that back out by product so he could build a Machine Translation engine just for certain product lines. And I recalled my training in how to set Fields and Attributes which dates back oh some 9 years now – back to when I first joined SDL as a translator. We were trained to diligently set Attributes on each job to ensure we could filter the TM at any point in the future so it is interesting to read that 9 years on this is still a valid concept.
Statistical Machine Translation engines can deliver really fluent and consistent results when trained on a corpus of data that closely matches the content you are going to push through in future – so the ability to strip out superfluous entries from your TM and use a tight corpus is key. Of course if you maintain separate TMs from the start it isn’t an issue but great to read that there is more than one way to skin a cat…. or terrier in this case!
This is an excellent comment Mel. I hadn’t considered using these for migration from a legacy TM to a corpus for MT, probably because I think Studio for everything! But the same advice is good for Studio too… nice use case. Thanks.
Hi!
I bought SDL Trados 2011 recently. When I try to use the Software it says no “Translation Memories” open. So I am unable to use this software for translation.
Reading your post above, it is clear that one can create a TM but I would have expected this software to come with basic Translation Memory (dictionary) to assist translation.
Can you pl. help me identify where I am going wrong? Or is it that this Software expects one to re-write a dictionary first before the Software can be on any help?
Thanks in advance
Hi Sumana,
The idea behind all translation tools like Studio is that you create a Translation Memory to suit the language combination you have and then you use that to help you work based on things you have previously translated. You can use Machine Translation to help you with this, but even then you should be checking the quality and only saving into your Translation Memory the corrected translation.
If you think about it, as Studio supports 351 languages (in W7… may vary slightly with other operating systems), this would equate to a possible 61425 language pairs. I think it may be a little excessive to provide Translation memories containing meaningful information for all of these 😉
Regards
Paul
By changing “SinglePickList” to MultiplePickList” in a TMX export, I was able to quickly change a field to allow multiple values without losing any data by using find and replace in a text editor and reimporting the TMX file into the TM.
Thanks,
Daniel
Extremely comprehensive analysis. Here is a tutorial for those olden days…
http://www.translatum.gr/forum/index.php?topic=23306.0
Thanks for sharing that here… nice for the nostalgic amongst us and for people like me who need to learn about the old Trados every time I have to deal with it!
Speaking of which, you may find this app useful if you have to deal with both versions
http://www.translationzone.com/openexchange/app/sdlxlifftolegacyconverter-194.html
http://www.youtube.com/watch?v=2QyhwvDDGz0
Indeed… although this is a conversion of an sdlxliff to legacy rather than the legacy you would get from Trados. Useful if you forgot or just needed to share files though… very useful. SDL LegIt! is another good choice as blogged by Nora Diaz here : Quick and Painless Conversion to Bilingual Doc Format with SDL LegIt!
Or, take a look at this article describing a few more… Life without Trados!
“Fields and Attributes in Studio | multifarious” in
fact causes me think a tiny bit extra. I appreciated each and every individual piece of this post.
I appreciate it ,Lenore
I have trouble with duplicates in Studio. Could that be due to setting fields to “Allow Multiple Field Values”?
Also, is there a way to automatically eliminate duplicates?
Thank you!
Hi Evelyna, I don’t think this is the problem. Allowing multiple values just allows you to have more than one field added to a single TU. If you don’t check this then when you translate with a different field value it will overwrite the previous TU field value rather than just add to it.
Studio normally does not allow true duplicates at all so it’s hard for me to comment on the problem you have without more details. Maybe you can email me? Use pfilkin@sdl.com and I’ll take a look.
Hi Paul, there seems to be an issue with the compatibility of attributes in the tmx produced in Studio and Workbench; i.e., a tmx produced with Studio, when imported to Workbench, will lose its attributes, and vice versa. I wonder why this happens since they both appear to support tmx 1.4.
Try using the Trados compatible export checkbox when you export from Studio. Lot’s of ways to use TMX 1.4, but the Studio TMX holds information Trados cannot use, and also in way Trados can’t know about anyway… it’s too old! So there is a checkbox when you export to create a Trados compatible flavour.
Vice versa should not happen though. email me an example (a small one if possible)
Thanks, Paul! It was right there staring at me 🙂
And the opposite seems to work too, i.e. from Workbench to Studio.
Hi Paul, thank you for the article. I read it carefully, but I did not find what I was looking for. I would like to build one big memory for one client. The point is that I have translated documentation for different products, and I would like to mark the different contexts. I was wondering if you could add fields to an already filled memory. In the TM view you can add fields in every segment, one by one, but I don’t find a way to batch assign fields to all segments at once. Is it possible?
Yep… in the TM View you would use the Batch Edit to do this. So you can add your new field and then replace the empty value with whatever you wish. If you want to restrict which TUs this applies to then create a filter first that picks up the TUs you want and then when you use the Batch Edit you select that filter. To do the entire TM don’t use a filter!
Hi Paul, very useful article. As a new Studio 2014 user, I am encountering some problem with fields. I am currently working with a client-provided TM that already have imported fields from legacy Workbench TM. My problem is that, although I was able to add new fields from [Fields and Settings] as well as assign the new field from [Update], no field seems to be added to my TU’s as I am translating. Also, when I am directly editing a TU, the new field does not appear under [Custom Fields] (the old fields are all there and can be used). What could be the cause of this and is there any fix?
I tried the batch process you suggested to Oliver above, which is able to add the new field to existing TU’s (the new field also now appears under [Custom Field] when I attempt to edit it) but it is not really what I am aiming to do.
(There also seem to be someone with similar problem here – http://www.proz.com/forum/sdl_trados_support/195844-trados_studio_add_text_field_value_to_more_than_one_entries_.html), but there was no solution at the end.
Hi Paul,
Great article. Thank you for posting!
I had a question regarding the section on ‘Delete part of your Translation Memory in a controlled way’.
I have a TM where I would like to remove the most recent instances of each duplicate entry (due to merging 2 TMs). Do you know of a way to filter by the older instances of each duplicate segment? That way I can remove all of the oldest entries at once and unfilter so i only have the newer segments left. I know how to isolate only the duplicates in the TM (by first exporting as an XLIFF with SDLTMConvert and setting the number of Export Frequent Segments to 2) but I’m not sure what the Search Filter query would look like or if there’s an easier way to do this without converting.
This is something that I could conceptualize in an Excel spreadsheet using a Pivot Table but I’m rather new to the world of Trados so I’m not sure how, or if, I could do this in Studio or an Open Exchange App. Let me know your thoughts if you have a moment. Thank you so much!
Luke Hipsher
Dear Paul,
I have a memory with Multiple field settings, consisting many similar segments (actually only field values differ, not content), but sometimes it has the same segment in Source, but different translation in Target.
I want to see first segment which belongs to my specific client, eg., coming only for year 2015 (list field) and belonging to specific customer (text field). Other similar segments I want to come below, not together with my client ones.
Right now it is merging all client codes together. Can I separete by using filters instead of using single values? Multiple one still could be useful and also should make memoery smaller?
Any ideas?
Dzintars
Hi Dzintars, it’ll be tricky to answer this without pictures. Can you post your question into the community and then I can have a go ant answering it? You can also use images in there to explain the problem a little better.
Dear Paul,
I don’t know how to paste picture here. I can send them by mail, perhaps
Dzintars
Not here… in the SDL Community link I provided. When you create your post there is a little toolbar at the top which allows you to add images.
Dear Paul,
I did it here: https://community.sdl.com/products-solutions/language/translationproductivity/f/90/t/3932
Dzintars
Paul,
I have registered in community but still can’t upload a picture or file – perhaps, some restrictions from our side. I have no idea I can show it then
ok – I’ll post a thread in the General section later this evening and explain how to add an image. Make sure you get the notifications and you’ll receive an email when I did it.
Here you go – click me
Dear Paul,
Thanks for your very clear and descriptive video, indeed, but problem is that I simply can’t add the image/media – website doesn’t allow me browse the image (your video at 3:15). Instead of Browse option it says Loading… that was my question concerning the pictures.
Nevertheless, I will try to explain without the pictures:
Our specific is that we have documents recurring over the years – Annual Reports. When we translate them, we have to follow previous years content – the legislative terminology, mentioned in the basic acts and they prevail the “normal” translation. Also it happens that some terms have been translated differently for different policy areas. In practice, to avoid excessive number of segments in memory, we use Multiple Values, but then specific segment attribute information (abbreviation of specific client) is together with others in segment attributes. They are listed alphabetically and we have to look in huge list to see whether this particular segment is for specific translation or we have to look in the next and next.
For example, there are 2 Agencies having the governing Board. Source name is the same for both, but translations are different in Target – one is a Board, another is a Governing Board according to the Foundation Regulation. Differences are caused by time when Regulations were created/translated – one was from 1996, another from 2001. STUIO proposes two segments and we specify correct one from the attributes to see which one to choose. But this way of working may lead to human mistake and I want to find a possibility to filter out by using field value, e.g., abbreviation of the Agency. Hopefully “my” Board will be proposed first, the others – only after. I would rather prefer hard filter instead of using penalty, but do not really know both options. When I tried to make filters myself, I got or no result or penalty for all entries, including “my” Agency.
We use several fields, but I want to filter them according the most relevant ones:
Document Type – List; Year – List and Observations – Text
All fields are set to Allow Multiple Values.
Perhaps the problem is related to the Multiple Values?
Dzintars
P.S. I am not a translator, I am preparing projects, thus, do not judge my English too hard
This is hard for me to answer here. The community is better because then I can use images … even if you can’t!! Can I ask you to simply copy paste your question there and then I can respond and try to mock up what I think you mean so I can have a play? It’s very hard without pictures!!
Dear Paul,
I put it here: https://community.sdl.com/products-solutions/language/translationproductivity/f/90/t/3932
Dzintars
Excellent, I replied 🙂
Dear Paul,
Thanks, indeed, it was exactly I was looking for…only one question now – can I also set a specific filter on one TM attached or it always goes on all? We use separate (empty from a beginning) working TM where Translators translates in and usually it is shared one. Therefore, I want to filter out this one particular TM by translator as well.
Aim is: Translator sees his own results, but doesn’t see input from other Translator, because segment is confirmed in Working TM, but not yet revised.
Cheers
Dzintars
Why ask me here? Much better to ask in the community and then others can see the answer too. This is hard work 😉 It seems to me you should think about using project TMs. This is exactly what they’re for! I think you’re over complicating a fairly simple scenario.
Hi, Paul,
I read this article like 4 or 5 times, but it is today that I think I may have figured something out. What can I say about myself, as a senior translator… However, I indeed have to thank you big time for writing this article. It provides me with some maybe small, but helpful tips, like updating the Project Translation Memory before starting to translate.
I have a question for you. In what circumstances should I use “List” and when should I use “Text” when setting the field type? In your example, you set the “client” field type as “List” and add several candidates in the “Picklist” attribute. Why didn’t you set the field type as “Text”? In my idea, if you set the field type as “Text”,every time you update the Project Translation Memory, the new client name will appear in the TU information place in the Translation Memory view during translation. So that to speak, “Text” and “List” type functions the same.
Please shed some insights on this question. I am really looking forward to hearing them.
Many thanks~
Maggie Zou
Hello Maggie, if you use a list then the names are predefined and you just select them. This removes the potential for errors, in case you spell somoething wrong for example. It also ensures you stick to the system you originally intended. It’s very easy to go wild and end up with all kinds of names that you may never search on again and then your filing system is less useful. So it’s just control really. I think if you’re the only one maintaining the TM then text would probably work fine, but once you are creating projects, as a project manager for example, across many translators then control becomes more important if you wish your TMs to be maintained properly.
Thank you, Paul. I am currently managing the TM myself so I will use “Text” as the Field attribute.