 Machine Translation or not Machine Translation… is this the question? It’s a good question and one that gets discussed at length in many places, but it’s not the question I want to consider today. Machine Translation has its place and it’s a well established part of the translation workflow for many professionals today. The question I want to consider today is whether you should hide the fact you are using Machine Translation or not?
Machine Translation or not Machine Translation… is this the question? It’s a good question and one that gets discussed at length in many places, but it’s not the question I want to consider today. Machine Translation has its place and it’s a well established part of the translation workflow for many professionals today. The question I want to consider today is whether you should hide the fact you are using Machine Translation or not?
This is a question that comes up from time to time and it has consumed my thoughts this evening quite a bit, particularly after a discussion in a ProZ forum this afternoon, that’s still running after three years, so I decided to take a step back and think about my position on this question and whether I’m being unreasonable or not. My position at the start of this article is that you should not hide the fact you are using Machine Translation.
Act 2
I’m starting with Act 2 because Act 1 has several scenarios and I’ll come back to them in a minute. In Act 2 I have run my source document through a pre-translate task using my Translation Memories and a Machine Translation Engine. I have then post-edited my results and have a bilingual document in Studio looking something like the first ten segments below… the translations are irelevant here because I want to focus on the statuses on the right:
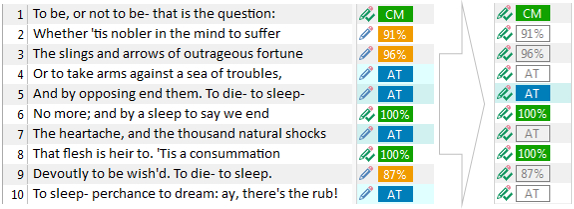
To help explain what’s happened here segments #1, #5, #6 and #8 are all unedited and you can see this because they have retained their original colour in the final status after translation. All the rest have been post-edited and become translucent, so this means I changed the results that came from the Translation Memory or the Automated Translation. In case you didn’t know, the AT status stands for Automated Translation and this means a machine returned the initial translation, and this could be a Machine Translation, but it could also be a feature of Studio for automatic handling of dates and numbers for example. In this case as it’s all text it’s obviously Machine Translation. So when I give my translation back to my customer in its bilingual form they will be able to see what I’ve edited, what I didn’t, and where the original translation came from.
Now I’m going to jump back to Act 1 because this can also change the context of Act 3…
Act 1
Scenario 1: I am working for a private client who doesn’t know anything about translation technology… doesn’t matter whether I use my Translation Memories and/or Machine Translation… my client only wants the translated materials back and pays for everything I have translated. Happy days!
Scenario 2: I am working for a client who knows a little about translation technology but just wants the translated materials back… only stipulation is they don’t want me to use Machine Translation.
Scenario 3: I am working for a client who owns translation tools and wants the bilingual files back, the SDLXLIFF files. They specifically state I should not use Machine Translation for this job.
Scenario 4: I am working for a client who owns translation tools and wants the bilingual files back, the SDLXLIFF files. They don’t mind me using Machine Translation but they might ask for a discount if I use it. They are a good customer of mine and always fair.
Scenario 5: I am working for a client who owns translation tools and wants the bilingual files back, the SDLXLIFF files. They don’t mind me using Machine Translation but they’ll probably ask for a discount if I use it, and in my opinion they have no idea what effort goes into post-editing and we always end up arguing over the rates.
There are of course more scenarios than this, and I haven’t addressed a scenario where I’m being asked to post-edit Machine Translation for a client, but I think this covers enough for the purpose of this discussion. I’m also not interested in why they don’t wish Machine Translation to be used… they just said don’t use it and they are paying for my services on this basis. So now I’m going to leap over to Act 3…
Act 3
I can forget about Scenario 1 as this is exactly the kind of client we all want! But the other four scenarios raise two important questions:
- Do I use Machine Translation anyway, despite being asked not to?
- Do I hide the fact I’ve used it to avoid conflict?
Well… in my black and white world, which I really hope is not me just being self-righteous, the answer to the first question is clear. If I’m asked not to use it then I don’t use it… it’s as simple as that. It doesn’t matter if I think the client is worried about nothing. The client is paying me for a service based on his requirements, so it’s completely unethical for me to use it when asked not to. It’d be like going into a shop and asking for organic vegetables, but being given genetically enhanced ones instead because the shop owner thought it’d be ok as I shouldn’t be worrying in the first place. So for the second and third scenario I would not use it.
The answer to the second question, as I ponder over it this evening is perhaps not so black and white. If my client is happy with me using Machine Translation then do I have to let them know when I used it? Would they ask me for a discount if I use it, or are they likely to if they knew I was? Agreeing the rates for using Machine Translation can be a tricky business because it’s affected by things like the quality of the Machine Translation engine, the type of material being translated and how effective I am as a post-editor for example. I have written about this sort of thing before so I’m not going to go into detail in this article. Perhaps refer to these posts if you’re interested:
But to come back to my second question… do I hide the fact I’ve used it to avoid conflict? This is not black and white at all. If I have a good relationship with my client and have always passed on a share of the savings because it’s good for the long term relationship and business I do with my client then I think being open and educating my client a little in what the use of Machine Translation means in reality is the right thing to do. Demonstrate the effort that goes into post-editing a poor result and agreeing either a flat rate in advance or a post-edit analysis might be the way to keep that good relationship so the client doesn’t even think to look elsewhere. Information is readily available for everything these days so I think it’s better for your business to be the one driving the way forward where possible rather than being the one getting dragged along.
But what if my client is less than reciprocal and is always looking to find ways to reduce my rates. What then… is it ok now to hide the fact I used Machine Translation so we never have these debates? Do I use Machine Translation for my own benefit only because I invested in the technology to support it… why give the savings to this client? Well, I’ve thought about this long and hard this evening and between you and me I’d hide it!!
What would you do?
Act 2a
I’ve added an Act 2a into my play because now I need to talk about how to hide it. This is a subject I’ve been tight lipped about in the past because I was black and white and didn’t approve of changing statuses to hide the fact Machine Translation had been used at all!.. But today we have so many ways to do this and even actively encourage a way to work with Machine Translation that leaves no trace anyway. I’m still going to steer clear of explaining how to edit the SDLXLIFF files directly because I think this is asking for trouble if you don’t know exactly what you’re doing and you could corrupt them. Instead I’ll cover two ways that make a lot of sense and I’m sure many users are doing this already.
MT AutoSuggest
I’ve mentioned this capability in the past in an article called “The ins and outs of AutoSuggest” so I won’t go into a lot of detail other than to say that this is now part of the product in Studio 2015. So if I am using Machine Translation and I have activated Translation Memory and Automated Translation as an AutoSuggest Provider then I can work like this with the Machine Translation results presented to me as I work but under my control so I can use the suggested translation, or part of it, as I type. The translations are suggested based on what I’m typing:
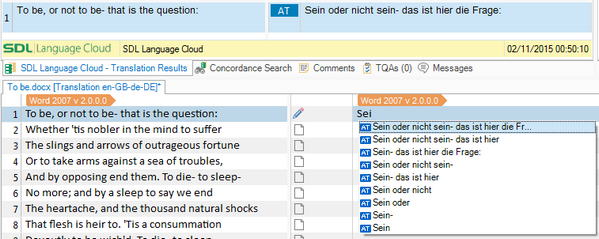
If I work like this there is no AT status in the segments. They will be treated as if it’s a no match and you have translated the segment yourself, which of course you are because it’s very unlikely that every segment will be the perfect translation. It’s just an efficient way of getting an additional lookup.
Convert to Translation Memory
The other way that is used by many translators already, and even by some organisations as a way of distributing Machine Translation results, is to use a conventional Translation Memory. The way to do this is to pretranslate the file using this option:
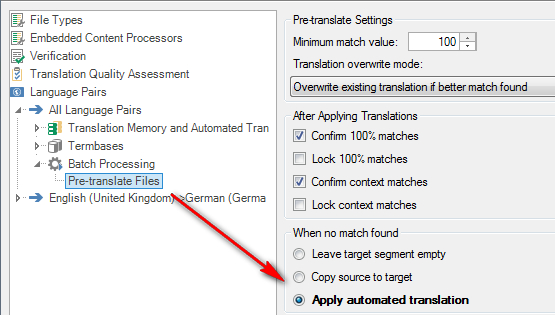
This will fill the bilingual file with a Machine Translated document, all marked up with AT statuses. Now, if you create a new TM and update the file into that TM using the Update Main TM batch task then the results from that TM will still show as AT. However, if you tackle this another way you can avoid this.
Method 1
Use the SDLTmConvert application from the OpenExhange to strip all the metadata from the TM and create a clean TMX. This is my preferred option because you can pretranlsate the entire project in one go, update into one TM and then clean it with this tool:

Once you’ve done this you simply upgrade the TMX, maybe add a field value to make sure you can see the results came from Machine Translation yourself, or even penalise the TM so you never get 100% matches, and you’re done. Here I used a 5% penalty so they are all 95% matches:

Method 2
Use the SDLXliff2Tmx application from the OpenExchange to convert your bilingual files, your SDLXLIFF files, to TMX and then upgrade as for Method 1.
Method 3
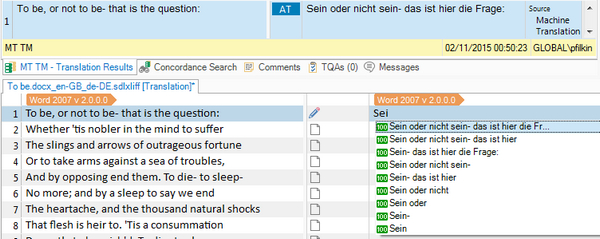
This is a bit of a hybrid but might be handy for working off line. Pretranslate your files using your Machine Translation engine and update it to a new SDLTM. But now, instead of converting to TMX just attach the TM to your Project and use the results of this via the AutoSuggest option that is now available with Studio 2015. The results will look something like this and the AT in the TM results window will not be shown when you confirm the segment:
So, as you can see there are many ways to work with Machine Translation, and the one you use is most likely going to be an ethical choice you make yourself. The decision on whether you tell your client you are using Machine Translation or not isn’t as black and white as I perhaps thought when I first engaged in this discussion in November 2012, but then the options available today make it even more impossible to enforce than it was back then.
So, I’m at the end of the article and I’ve changed my views under some circumstances… what would you do?
This is quite an issue. Thank you for the hints on the use of MT/AT.
I have prime clients and their jobs demand very technical (corporate) language to be translated. I never use MT/AT and it is not related to quality, but with localization or even specific technical uses which might make their jobs safer or successful. One interesting thing is that they never asked me if I used MT/AT or if I should or should not use it.
I find MT/AT post editing really tiring and would use it for general purposes only, but under client’s’ authorization; as said in your article: if clients’ demand no use of MT/AT, I should work under our agreement.
Cheers.
Thanks Paulinho, in your situation it might be interesting to try MT using AutoSuggest perhaps… it might just be a useful aid without getting in your way. Many translators have been surprised how helpful this can be as a typing aid, or just an additional lookup when you get no results from your more traditional resources. This way you wouldn’t be post-editing as you’d have the control over what is placed into the target segment as you type. I think it’s worth a look anyway…
Hi Paul,
Thanks for the article.
The statuses like AT, CM are showed only in the sdlxliff files or also in the TMs (tmx files)?
Sometimes clients just ask for the target doc and the TM.
Thanks
Hi Anna, if you send a TMX from Studio then it depends which option you use for the export. If you use the export to TMX and check the 2007 format option then there is nothing in the TMX to indicate the origin of the translation. If you use the Studio TMX export without checking the 2007 format then the export is much richer and this carries the x-origin property which makes it clear that the translation came from Machine Translation.
It is actually very easy to “hide” the use of MT by using MT autosuggest.
And if the sentence from MT is actually OK, why shouldnt’t I use it to translate faster.
Sometime the whole MT suggestion is jibberish, but with MT Autsuggest you can still pick single words or phrases from it with MT Autosuggest.
But with MT you also need to be careful, because all MT engines I’ve seen sometimes get negation wrong.
And finally, when they really mangle up a sentence, they can be a source of entertainment on the job. 😉
In Act 2a, instead of using AutoSuggest you can — if the whole suggested translation is usable as a starting point for editing — simply select that whole suggestion, copy it and paste it into the target segment. (If the segment is not a very short one, that’s quicker than selecting several AutoSuggested fragments one after the other.)
Thanks Mats, I guess there are always more than one way to tackle a problem. But AutoSuggest could suggest the entire segment so you don’t have to do it in fragments.
Hi Paul, not sure if you’re still active here, but I’ve tried everything to the best of my abilities.
i.e. I have converted to tmx as in your 1st method. But the status always claims NMT (Neural Machine Translation… I’m using Deepl). … Then I thought if I disable the MT, and with the new tm from my imported tmx it will overwrite NMT with 100% (as your Method 1 suggests to me)… finally I even re-imported the SDL file and thereby replaced the old one, now hoping that my new TM will show… Still NMT is all that shows.
Can you tell me what I’m doing wrong? Is it to do that I’m using Trados 2021?
Hello Ron… well, it is my blog 😉
This article is over 5-yrs old so why don’t you take a fresher approach. There are two apps on the appstore that will help you:
SDLXLIFF Anoynmizer
SDL Batch Anonymizer
ps: or do I have to delete the original Trados project entirely from my computer, redownload the project and then apply my new TMX?