 With all the excitement and interest around ChatGPT these days, and with the numerous interesting projects we’re working on at RWS that involve the use of AI, its hard not to allow the lure of the technology to pull you in. Last month I wrote an article on corrupt translation memories, and in doing this I dabbled a little with SQLite queries… an SDLTM is a SQLite database. They are pretty much new to me as I’ve only used very simple statements… one liner lookups for example… in the past. So I had to read some basics and learn a little when I did that. Nothing new, I like to read this sort of material and learn a little something new anyway. So when I was asked this evening how do you remove translation units from a translation memory that have the same source and same target I immediately started to think SQLite.
With all the excitement and interest around ChatGPT these days, and with the numerous interesting projects we’re working on at RWS that involve the use of AI, its hard not to allow the lure of the technology to pull you in. Last month I wrote an article on corrupt translation memories, and in doing this I dabbled a little with SQLite queries… an SDLTM is a SQLite database. They are pretty much new to me as I’ve only used very simple statements… one liner lookups for example… in the past. So I had to read some basics and learn a little when I did that. Nothing new, I like to read this sort of material and learn a little something new anyway. So when I was asked this evening how do you remove translation units from a translation memory that have the same source and same target I immediately started to think SQLite.
Why SQLite and not the product? Well, surprisingly enough there is no function in Trados Studio to do this. The maintenance features in the Translation Memory view are fairly basic, and even more surprisingly we have never built a small tool to enhance this with the AppStore Team. So back to the SQLite documentation to figure out how to do this.
Safety First
The first step in carrying out any such maintenance directly on an SDLTM is to take a copy of your TM and NEVER EVER do this without safely backing up first!! Once you’re working on a copy you can do whatever you like!
Working with SQLite
To work with SQLite I’m finding that the first thing to do is to make sure you have a sensible SQLite editor to make it easier. I use the excellent DB Browser for SQLite which seems to give me everything I need at the moment. All I need now is a translation memory, so I create a TMX from the DGT collection, English to French, containing around 76794 translation units and upgrade it into Trados Studio. The upgrade cleans out invalid, blank, number only etc. units and this leaves me a translation memory holding 63044 translation units. Perfect for testing with.
I then set about trying to learn how to find translation units that have the same source/target content. After some reading I decided I really needed to use a regular expression to find what I needed since the content I’m looking for is actually wrapped in an XML wrapper within the SQLite table rows. Something like this:

To get at this I figured I could use a regular expression, and came up with this:
(?<=^.+?<Value>).+?(?=</Value>)
That does a pretty good job of extracting only the text I’m interested in:

My problem is figuring out how to use this in a SQL Query. After 15 minutes or so (I am short on patience…) I came up with this:
SELECT source_segment, target_segment
FROM translation_units
WHERE source_segment REGEXP (?<=^.+?<Value>).+?(?=</Value>) = target_segment REGEXP (?<=^.+?<Value>).+?(?=</Value>);
Which duly returned this error in the DB Browser application:

A little more research and I learn there are only limited options for regex in SQLite which I have definitely exceeded here… and to be honest I’m not even confident of my syntax for the rest of the query.
ChatGPT to the rescue!
So I decided to see if I could solve this by asking my new OpenAI friend, ChatGPT. I ask it what’s wrong with my query?

Well… wow! Every time I look at this I’m amazed at how good the answers are. At least they always look good and this can be deceiving. Certainly a lot of the tests we have done at work prove how often it can be eloquently wrong as well as perfectly brilliant! So let’s take a look at this suggested code which I can even conveniently copy with a single click:
SELECT source_segment, target_segment FROM translation_units WHERE substr(source_segment, instr(source_segment, '<Value>') + 7, instr(source_segment, '</Value>') - instr(source_segment, '<Value>') - 7) = substr(target_segment, instr(target_segment, '<Value>') + 7, instr(target_segment, '</Value>') - instr(target_segment, '<Value>') - 7);
I paste it into the DB Browser and execute it:
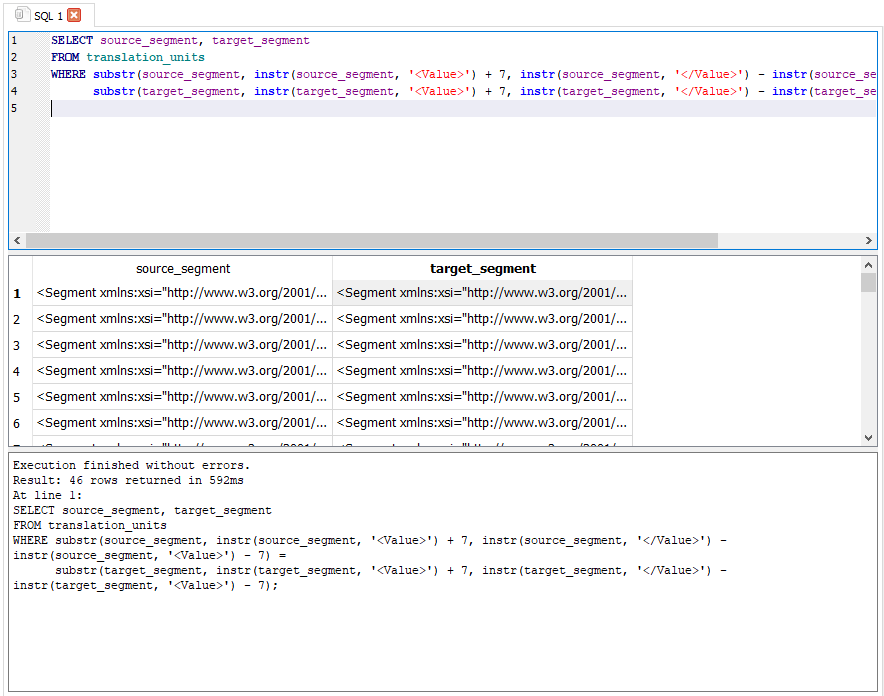
It runs perfectly and finds 46 rows in my 63 thousand TU translation memory that are same source same target, and it finds them in 592ms. I checked them and they’re correct!
So I naturally ask it how I would adapt the previous query to delete each row in the database table:
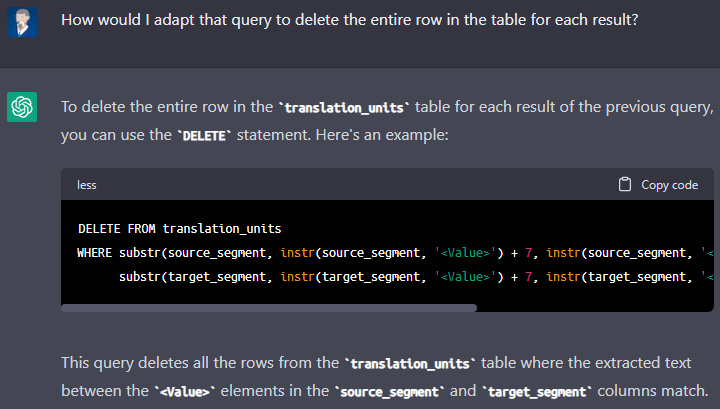
Once again it obliges instantly with the requested statement:
DELETE FROM translation_units
WHERE substr(source_segment, instr(source_segment, ‘<Value>’) + 7, instr(source_segment, ‘</Value>’) – instr(source_segment, ‘<Value>’) – 7) =
substr(target_segment, instr(target_segment, ‘<Value>’) + 7, instr(target_segment, ‘</Value>’) – instr(target_segment, ‘<Value>’) – 7);
Looks simple enough, so I execute that one too!

In 492ms I deleted all 46 rows from my TM. I then open it up in the Translation Memories View of Trados Studio and check it works. Everything looks good, so I check the number of TUs and it’s still 63044 TUs.
So then I ask my AI friend if there is anything I need to do after removing rows in a SQLite database table to ensure it’s properly prepared for use:
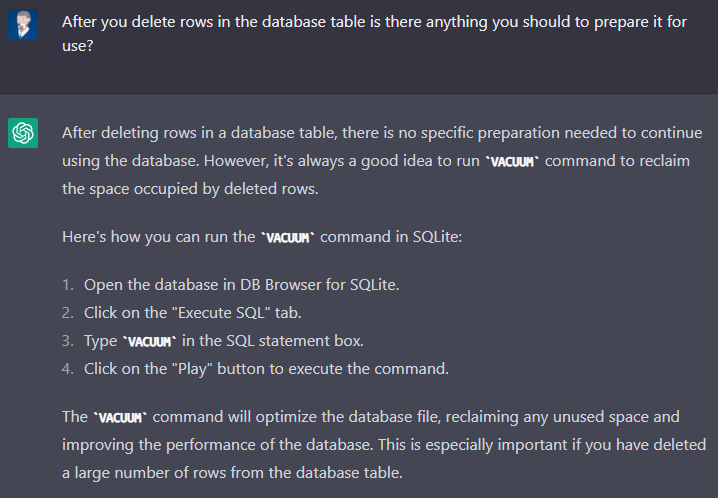
The answer is again pretty good and I execute the VACUUM command which completes in 22853ms:

Certainly I am learning some stuff here and it is very specific to my actual task every time. I now open in Trados Studio again and it’s still showing 63044 TUs. So I do the obvious and recompute the fuzzy index statistics, and reindex the translation memory. This returns exactly what I hoped to see:

And now, after closing the settings window and opening it again the number of translation units correctly show 62998. I’m good to go!
The steps…
I think at this stage a quick recap would be useful of just what the steps for removing same source same target (SSST) translation units (TUs) would be:
- take a backup of your SDLTM
- open the SDLTM in the DB Browser
- optionally check for these SSST TUs by executing this query:
-
SELECT source_segment, target_segment FROM translation_units WHERE substr(source_segment, instr(source_segment, '<Value>') + 7, instr(source_segment, '</Value>') - instr(source_segment, '<Value>') - 7) = substr(target_segment, instr(target_segment, '<Value>') + 7, instr(target_segment, '</Value>') - instr(target_segment, '<Value>') - 7);
-
- if there are any delete them with this statement:
-
DELETE FROM translation_units WHERE substr(source_segment, instr(source_segment, '<Value>') + 7, instr(source_segment, '</Value>') - instr(source_segment, '<Value>') - 7) = substr(target_segment, instr(target_segment, '<Value>') + 7, instr(target_segment, '</Value>') - instr(target_segment, '<Value>') - 7);
-
- execute the VACUUM command to optimize the TM database, reclaim any unused space and improve the performance of the TM
- open the TM in Trados Studio in the Translation Memory View and “Recompute Fuzzy Index Statistics…”, then “Re-index Translation Memory”
- note the correct number of deleted TUs from the DB Browser match the number shown in Trados Studio
Now you know this, the final thing I’d say is you do it at your own risk!! So backup… backup… backup before you try it. Certainly I’m personally encouraged by this exercise to see what else I can learn to do in terms of managing the content in a TM with SQLite… and I’ll also see what we can do in terms of making a robust solution via the appstore!
The takeaway…
Well, there is no denying how useful AI, and this OpenAI tool, ChatGPT, is going to be. I’ve been playing with it for a while and asking it questions around everything I get involved with just to see how it responds.
Tonight I have literally gone from trying to tackle this real question I was asked about deleting translation units in a translation memory , to writing up this article in around 3-hours despite being pretty ignorant of how to run SQLite queries like this. Admittedly I did know how to write the regular expression needed to feed into ChatGPT and I did know how to resolve the problem of recomputing fuzzy indexes etc. But even though I have not checked I’m pretty sure I could have got there without even this rudimentary knowledge just by asking the questions in plain language.
But it is dangerous and should be used with care. I think in the hands of someone who can apply it sensibly and ethically it’s a fantastic tool to have at your disposal. But there’s also a very negative aspect to it ranging from the negative effect this could have on our children’s ability to think for themselves, to massive amounts of misleading and incorrect content appearing in what’s already an overwhelming barrage of information and stimuli, often negative, from multiple social media platforms…. and more!
To finish off I asked ChatGPT about this very question… and its answer was:
AI solutions like ChatGPT can be used ethically and without harming people if they are developed, trained, and deployed with careful consideration for ethical and safety concerns. Some best practices for ethical AI include: ensuring fairness and avoiding discrimination, protecting privacy, being transparent about how AI systems make decisions, and avoiding potential harm to individuals or society. However, the ultimate responsibility for ethical AI usage lies with the people and organizations using these technologies, and they should continuously monitor and assess the impacts of AI systems to ensure they align with ethical principles and values.
So its down to us… I’m going to try and remain optimistic!
Impressive, Paul! Love discovering unexpected new ways to use AI. Thanks for writing it up. I’m surprised there were only 46 TUs with identical source and target. Are you confident you caught them all, in a DGT TM of 63000 TUs?
Well… the only way I have to check other than manually looking through (which I won’t be doing ;-)) is to search. So if the search is correct that’s where my confidence sits. I tested with smaller subsets and it seems to find everything so I think the SQLite search does a good job. It won’t find fuzzy candidates, so they would need to be identical, and I guess that’s a possible improvement to consider. Might have a play with that 🙂
Thank you, Paul! This is a great example of using ChatGPT. I love that it even explains what was wrong with the original query. Imagine how long it would take to research that syntax in the traditional way.
Your post also solves the problem I had of removing duplicates.
Initially the code for DELETE produced a syntax error in SQLiteStudio. The reason was that the single quotation marks in the DELETE code are slanted, whereas the ones for SELECT are straight. It’s virtually impossible to see the difference with the naked eye. Using straight quotes in the DELETE query solved the error.
The quotation marks in the numbered steps are OK, but further up in the article – where the DELETE query is initially mentioned – they are slanted. If anyone else uses these queries, be sure to copy them from the numbered list.