 This is a topic that probably occurred a lot more in the old days of Trados and Translators Workbench where it was relatively easy to corrupt a translation memory. In those days the translation memory consisted of five file types with the extensions .tmw, .mwf, .mtf, .mdf and .iix and when problems did occur it was probably related to the files that supported indexing and lookup speeds for example. The .tmw file itself that contained the translation units was less likely to be the source of the problem. So fixing it could often be achieved by creating a new translation memory with the same settings, and then simply replacing the .tmw in the new translation memory with the old one… finally reorganising. This didn’t always help, but if often did!
This is a topic that probably occurred a lot more in the old days of Trados and Translators Workbench where it was relatively easy to corrupt a translation memory. In those days the translation memory consisted of five file types with the extensions .tmw, .mwf, .mtf, .mdf and .iix and when problems did occur it was probably related to the files that supported indexing and lookup speeds for example. The .tmw file itself that contained the translation units was less likely to be the source of the problem. So fixing it could often be achieved by creating a new translation memory with the same settings, and then simply replacing the .tmw in the new translation memory with the old one… finally reorganising. This didn’t always help, but if often did!
Today in Trados Studio the translation memory is actually a SQLite Database File. It’s just one file consisting of tables (a collection of data held in rows and columns), indexes (a kind of table of contents to speed up searching), triggers (stored procedures that carry out an action), and views (a virtual table often made up by combining tables). But still all held in one file. The reason I mention this is because when a SQLite database, or an SDLTM, gets corrupted it’s no longer as simple as just recreating and replacing a file.
You may well be thinking now that this seems as if we’ve gone backwards, so it’s important to note that SQLite databases are far more robust and less likely to become corrupt in the first place! But it is still possible to corrupt them and if you want to know the many ways in which this can happen just spend a little time reviewing this helpful webpage “How To Corrupt An SQLite Database File“. In the context of Trados Studio this often translates into these sort of things:
- sharing your translation memory with others so you all access it at the same time
- keeping your translation memory on a network drive that regularly synchs the data between the drive and your computer… yes this does include OneDrive that pretty much comes set up by default with every PC you buy these days!
These two things are probably responsible for the majority of the few times I’ve seen this problem and if you take the time to review the link I mentioned earlier I think it’s pretty clear how this can happen. Trados Studio file-based translation memories are designed to support you as an individual user and not for concurrent sharing. If you want to share them there are safe ways to do it:
- provide a copy to your colleague so they work on their own version of your translation memory. You can update later in many ways.
- In fact one of the benefits of working with a “Project Translation Memory” is to support this kind of workflow… you just share the most appropriate part of your translation memory and your main one remains safely intact.
- practice “safe sharing” with “a little help from your friends“, something I’ve explained in detail many times in the past.
- consider working with “Trados Team” which is designed to support sharing everything on a translation project by working safely in the cloud.
Ideally cloud working is the way to go, but lets be realistic… for most freelance translators who only do this occasionally the fact it’s possible to so easily attempt to share a translation memory in Trados Studio via OneDrive, Dropbox or a host of other solutions you probably already use, something that’s not so easy to do in other tools, means you just need to practice “safe sharing“. At least until there’s a smart solution in the Trados cloud environment for this very purpose.
Contents
Recovering from a Corrupt translation memory
IMPORTANT UPDATE 4 February 2023
The week after going through this exercise with the limited knowledge I had at the time I wrote an article looking at the use of ChatGPT to help when working with SQLite statements and queries. In fact I published it last night and woke up this morning rethinking this article. So please make sure you also read the very end of the article to find the most optimal solution I have so far for recovering the content of a corrupted TM.
Back to business
But let’s get back on track a little…although before I do let’s say a few words about “safe business”.
Backup routines
I cannot recommend enough that you backup your translation memories (and other important resources such as termbases) regularly. By regularly I mean at least once a week. I’d also recommend you not only take a copy of your SDLTM but you also export to TMX and save that. A TMX a simple text file, much less likely to corrupt and very easy to recover your SDLTM from. The reason I’d suggest at least once a week is partly because it’s my finger in the air and partly because if the worst comes to the worst you can rebuild your translation memory from the TMX and an import of whatever projects you were working on that week. So it’s not a difficult task remembering to backup and should always be done when you are not working in Studio. So using OneDrive that synchs in real-time because you think it’s always got your back is once again, not the right approach with your translation memory!
Most backup tools have the ability to schedule a back up for you so you’d only need to remember to do the TMX exports. And if you’ve never purchased a backup tool before I can recommend Bvckup 2 which is the best backup tool I’ve ever purchased… not too expensive either and well worth the peace of mind.
Back to recovery!
SDLTM Repair
I have to start with the little plugin from the RWS AppStore called “SDLTM Repair“. This plugin adds an icon to your ribbon under the Add-Ins tab:

Click it and you’ll be presented with a simple view like this:
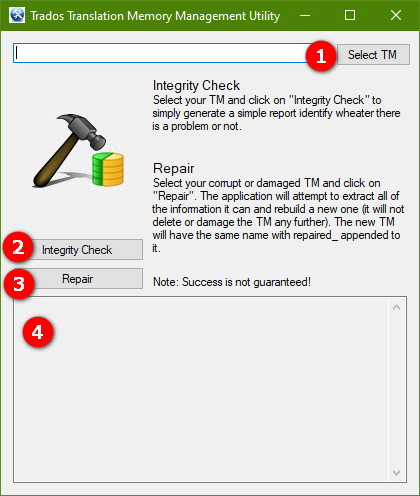
- select your translation memory
- optionally run an Integrity Check
- a nice definition of what this is comes from O’Reilly:
“The integrity_check pragma runs a self-check on the database structure. The check runs through a battery of tests that verify the integrity of the database file, its structure, and its contents. Errors are returned as text descriptions in a single-column table. At most, max_errors are reported before the integrity check aborts. By default, max_errors is 100. If no errors are found, a single row consisting of the text value ok will be returned. Unfortunately, if an error is found, there is typically very little that can be done to fix it. Although you may be able to extract some of the data, it is best to have regular dumps or backups.”
- a nice definition of what this is comes from O’Reilly:
- run the Repair
- after reading the O’Reilly explanation above you can see why the plugin also has the note “Success is not guaranteed!“
- the results of the integrity check or the repair will be displayed in this pane.
Unfortunately, when the database fails an integrity check the Repair can still report that it successfully completed, only for you find the file size is zero! This is because the Repair operation successfully completed, but that isn’t the same as the actual repair of the database being successful!
What is the repair tool doing?
I thought it might be interesting for you to know what this tool is actually doing, especially since it’s so simple. You can actually do this yourself in a windows command line. All you need is the sqlite3.exe file, (command-line shell program) which you can download from the SQLite website.
Once you have this file, to run the Repair just put a copy of the SDLTM and the sqlite3.exe file into a folder like this:

Then open a command line prompt from this folder and run this command to dump the contents of the translation memory into a sql file:
echo .dump | sqlite3.exe corrupt.sdltm > dumped.sql
Followed by this command to create a new translation memory and import the sql back into it:
sqlite3.exe -init dumped.sql repaired_corrupt.sdltm
In the command prompt it’ll look something like this when you’re done:
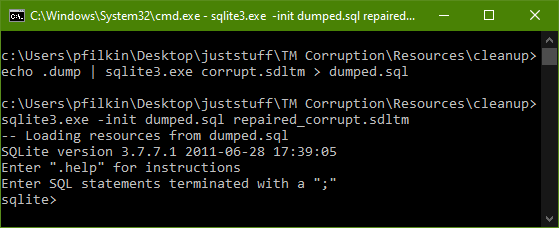
This process “may” recreate the translation memory without the errors you had before, This is exactly what SDLTM Repair is doing. The end result being you’ll now find these files in your folder:
When “Repair” doesn’t help?
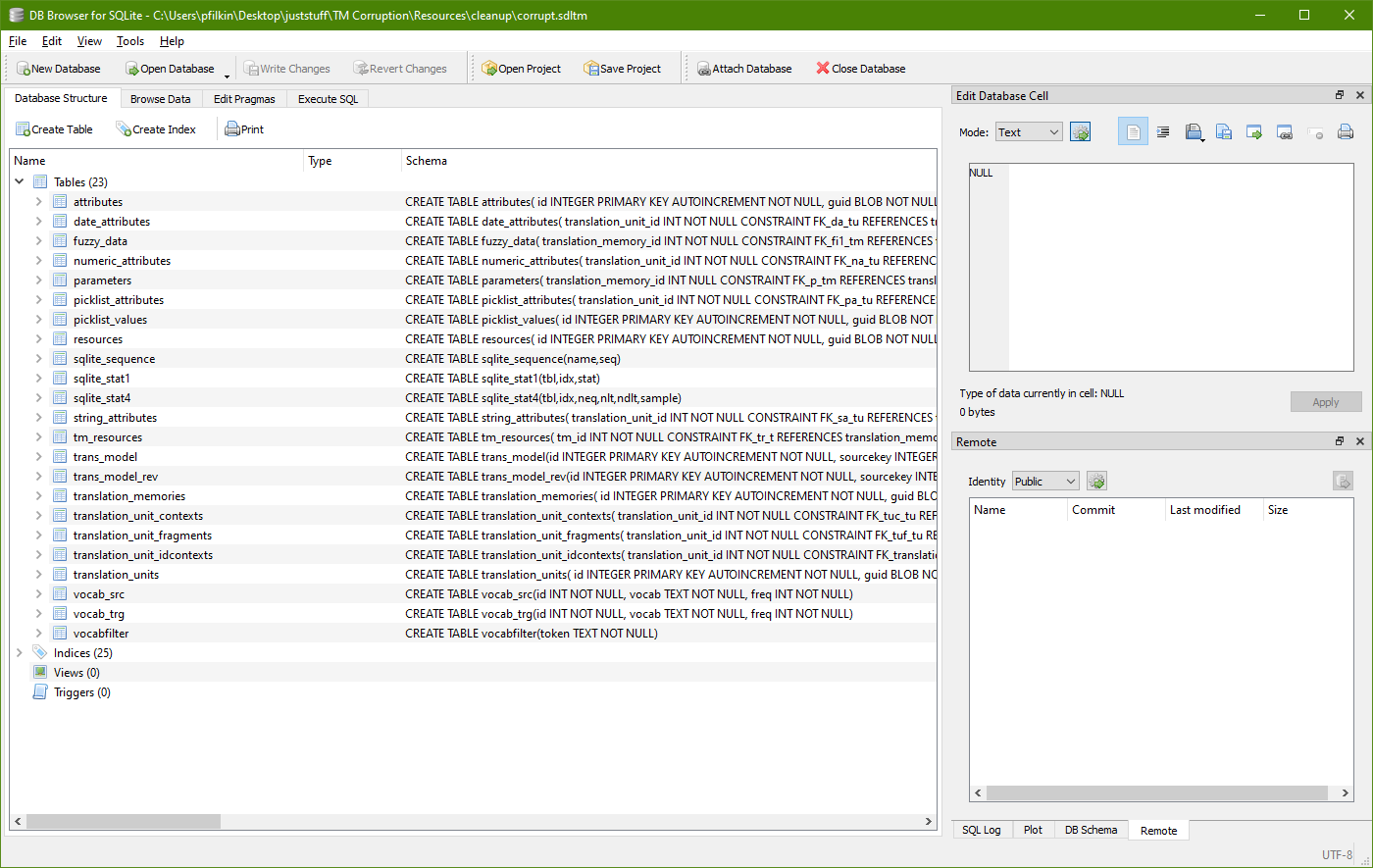
This is where it gets tricky. I’m by no means an expert on this and have tried several times to recover the years of work lost due to a translation memory becoming corrupt and the hapless user not having backed up at all. So where do we start? Well the first thing is to see where the translation units are stored. To do this the easiest way is to use a browser for SQLite. The best one, as it’s free and seems very capable, is probably DB Browser for SQLite.
Using this tool you can open an SDLTM (put the whole path in because the tool won’t even show *.sdltm files when you use open file) and see the tables, indexes, triggers and views like this:
If you open the translation_units table you’ll see something like this, and in here you’ll also see the columns in the table and importantly where the source and target data is:
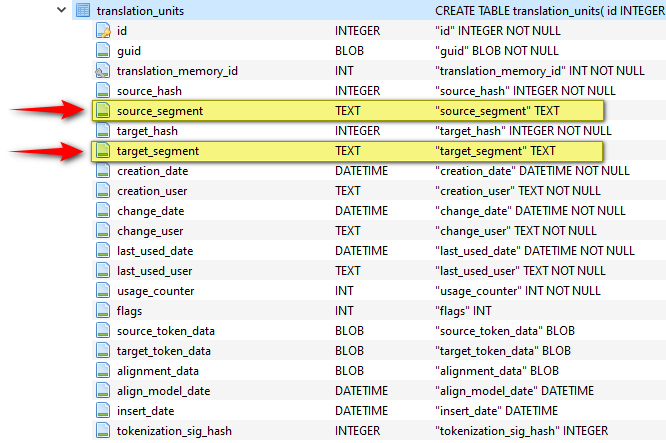
If the translation memory was not corrupt, or perhaps not too badly corrupted, then you could use SQLite3 again like this:
sqlite3 corrupt.sdltm sqlite> .headers on sqlite> .mode csv sqlite> .output recoverTUs.csv sqlite> SELECT source_segment, ...> target_segment ...> FROM translation_units; sqlite> .quit
This can very neatly get you a csv file similar to this which you could probably use quite neatly to extract the source and target text using a bit of regex. You need this because Trados Studio stores the data as xml since it also needs to ensure tags are properly handled:

However, if the translation memory is damaged this may not work and you could see a result like this with no data extracted at all:

The database disk image is malformed and this prevents an export from SQLite directly, as well as Trados Studio, from working. So, in the absence of me knowing any better (all help from SQL experts welcomed!) I think a more basic method is needed and so I attempt to .dump the contents of the entire table instead.
To do this I’ve tried dumping through the command shell to txt or csv like this:
sqlite3 corrupt.sdltm sqlite> .output dumped.txt sqlite> .dump translation_units sqlite> .quit sqlite3 corrupt.sdltm sqlite> .output dumped.csv sqlite> .dump translation_units sqlite> .quit
Neither of these methods produce data that is very easy to correct. The source and target text is in here but it’s very difficult to get at and even more difficult to align the source and target:
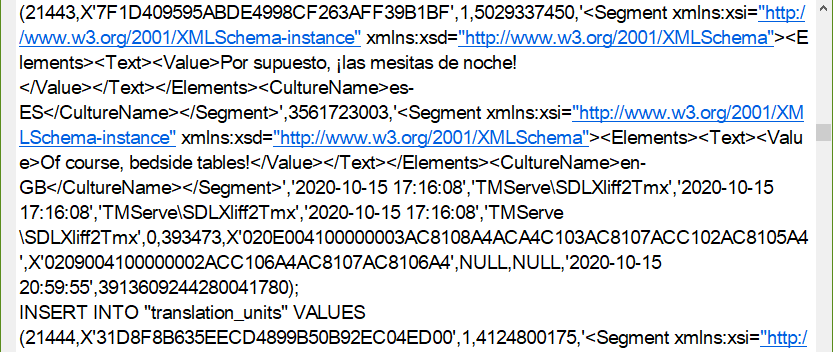
I also tried a similar exercise exporting the table directly through the DB Browser for SQLite. This gave me a similar file, and in fact one that was harder to read as many more of the characters were corrupt. I have had some success with this approach though and documented it here in the RWS Community the last time I tried it (just a week ago, hence my renewed interest in the topic this weekend!). The regular expression I used may not be suitable for all corrupt translation memories since I wrote it as I worked through this particular file based on trial and error… it was a pretty painstaking process into the middle of the night. Since the memory was corrupt the content also had many problems to deal with:
- source and target content sometimes the wrong way around;
- additional hard breaks in the middle of sentences making hard to capture “wholesome” translation units;
- missing source and/or target segments
- invalid xml causing the regex to behave in a way I didn’t want;
- additional quotation marks causing lazy matches to end prematurely;
- misaligned source and target segments;
- etc.
For ease of reference the process was this:
- Opened the SDLTM in the DB Browser for SQLITE
- Export the “Translation Units” table to a csv
- Added a BOM to the csv (very important if you don’t want to corrupt characters using diacritics when you import to Excel… I had to do this exercise twice because I didn’t realise this would be a problem the first time)
- Imported the csv to Excel
- Deleted all the columns I didn’t want… in this case I just kept the source and target content. So I have this sort of stuff that we saw before:
- I deleted all the ones that were obviously missing target and copied the content of both source and target into a text editor so I could clean them up. I used this expression (Note: this expression is not a catch all for all translation memory recovery exercises!)…
Search for:(?:"?<Segment.+?<Value>(.+?)</Value>.+?</Segment>"?(\t)"?<Segment.+?<Value>(.+?)</Value>.+?</Segment>"?)
Replace with:
$1$2$3
- This got me a clean tab delimited text for source and target (for example… )

- I pasted that back into Excel as it’s easier to clean up in there
Creating the SDLTM from this was straightforward… just used the Glossary Converter to go to TMX, then upgraded that to an SDLTM in Trados Studio.
So to really make a thorough job of this task you’d need a lot of time on your hands and real will to extract as much as you can. In that exercise I think I probably recovered around 50% of the original translation memory and I certainly didn’t deal with any of the inline markup that would now appear as text. But the user seemed very happy to at least have that much recovered from a reasonably large translation memory.
One other approach that might be worth a try is to export as JSON. When I looked at it the structure of the file was also corrupt and I found it easier to tackle the file the way I did. But potentially, using the SuperText version of the JSON filetype (if they submit it to the appstore again) this could be a neat way to handle things. That filetype is actually bilingual compared to the out of the box version that is only monolingual. So you could split up the exported JSON into multiple files and then bring them into Studio as a bilingual file by just extracting these parts:
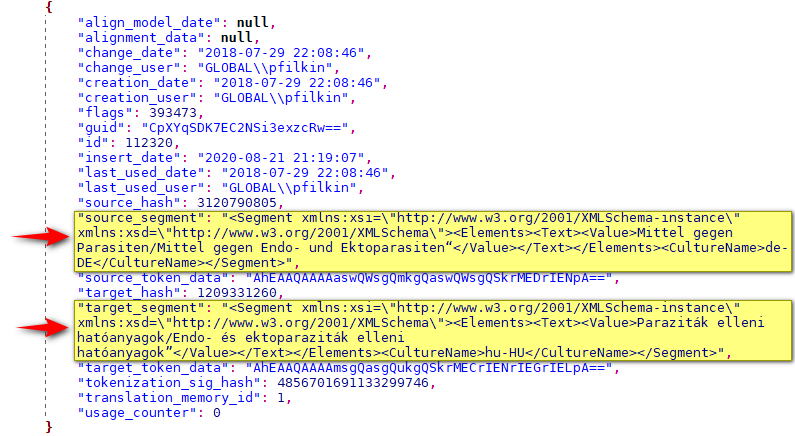
I think it could be a better solution since you’d have better alignment for the chunks that weren’t damaged. But given you can only handle small files at a time in Trados Studio you really really would need the patience of a saint!
IMPORTANT UPDATE 4 February 2023
The week after going through this exercise with the limited knowledge I had at the time I wrote an article looking at the use of ChatGPT to help when working with SQLite statements and queries. In fact I published it last night and woke up this morning rethinking this article.
In the absence of any SQLite experts sharing their skillsets I used ChatGPT to find a better solution t this problem and it obliged! It took a few questions and me refining the questions to get what I needed but with the conversational nature of this tool I got there in a few minutes and again it worked brilliantly. So here is a set of refined steps (edited slightly from the ChatGPT result) that might be good using the DB Browser for SQLite:
- Open the database in the DB Browser for SQLite.
- Go to the “Execute SQL” tab.
- Enter the following query in the SQL Editor:
SELECT substr(source_segment, instr(source_segment, '<Value>') + 7, instr(source_segment, '</Value>') - instr(source_segment, '<Value>') - 7) AS source, substr(target_segment, instr(target_segment, '<Value>') + 7, instr(target_segment, '</Value>') - instr(target_segment, '<Value>') - 7) AS target FROM translation_units; - Click the “Execute” button.
- Go to the “Export” tab.
- I couldn’t actually find an “Export tab” but there is this icon:

- I couldn’t actually find an “Export tab” but there is this icon:
- Select “Export to CSV”.
- This window will appear:

- I used the tilde character as the field separator because when testing I found the corrupt data often cause the export to contain multiple columns and made the work difficult to handle (as you can see from the original article).
- Click on “Save”
- Name your file and choose the path to save it.
- The data from the query will be saved in a .csv file with the specified name.
- Make sure you add a BOM to the csv before importing into Excel (if you decide to do this) to avoid character corruption due to encoding issues.
And then convert to TMX with the Glossary Converter and upgrade or import into a TM. This process recovered far more data than the cobbled trial and error approach I worked through in the article.
I will also look at getting the SDLTM Repair tool enhanced with this option. It may not work for every TM as the corruption could be so bad it’s irrecoverable, but given I managed to recover what looks like pretty much the entire TM using this method I think it’s worth having as an option!
So what’s your favorite way to deal with mojibake from bad encoding? Lots of that from old Trados Workbench and Wordfast TMs.
Good question… can’t say I come across this a lot in production these days. In the past I’ve dealt with two of the main reasons for causing this, and there are more, which are incorrect encoding and non printable characters. For the encoding problems I find the File Encoding Converter to be an invaluable tool, especially if a lot of files are involved. But for the non printable characters, which I see more often in old TMX files downloaded for testing more than anything else, I simply use a regex to find them and replace with nothing. I built the regex up to try and catch them all and it seems to work pretty well… here in case it’s helpful:
\u0000|\u0001|\u0002|\u0003|\u0004|\u0005|\u0006|\u0007|\u0008|\u0009|\u0010|\u0011|\u0012|\u0013|\u0014|\u0015|\u0016|\u0017|\u0018|\u0019|\u001A|\u001B|\u001C|\u001D|\u001E|\u001F|\u007F|\u000B|\u000C|\u000E|\u000F|\uFFFE|\uFFFC|\uFFFFHow do you deal with the problem?
Yesterday, I thought I’d try out the “RecordSource TU” plugin, because it offered a functionality that bewilderingly was deleted or maybe never implemented in Studio. Somehow the plugin killed my TM completely and I came to this page only to be confronted by a seemingly bewildering array of solutions that require the kind of computer competence that any software developer cannot reasonably expect a standard user to have.
Anyway, I battled through various options and nothing worked. The first and most obvious line of attack was to try out “SDLTM Repair”. This did absolutely nothing. And if, as you describe it above, it is based on a dump and reimport process using sqlite, this is no great surprise. I also fannied around using your various options in the command shell, but none of them were able to read or process the file.
Basically, as mentioned above, the error is “database disk image is malformed” meaning it must be fixed first. Somewhat disheartened, I thought I’d try your DB Browser approach. But because “the database disk image is malformed” it wouldn’t even entertain opening the file. So that option was strangled at birth. (Tip: If you use the “All files (*)” option you can see and open .sdltm files directly)
Somewhat belatedly, I came up with the idea to ask a colleague in IT if he had any ideas how to solve the problem. After quickly explaining what an .sdltm file and its relationship to sqlite3, he managed to fix it in about 10 minutes flat.
Here was the solution (using sqlite3.exe):
sqlite3 translationmemory.sdltm “.recover” | sqlite3 new.db
The newly created file, new.db, was then simply renamed as a .sdltm file and everything worked. I thought this might be of interest to you and maybe the SDL plugin can integrate this to improve its functionality.
Thanks for sharing that. I noted you resolved the problem with your TM. Glad about that.
Yes, we also figured out what the problem was with the plugin. So all’s well they end well.