Handling number only segments is a question that comes up a fair bit, and for a number of reasons. Mostly it’s the more simple question of how to handle them at all; sometimes they are recognised and Studio can auto-localize them; sometimes they aren’t recognised and you need to work around this a little. This question I’ve addressed a few times, so here’s a few links as a reminder.
A question that comes up less often, but still requires a little thought with regard to how to handle it is how do you determine the count? What I mean by this is if you, as a Project Manager for example, are preparing files for a translator and wish to exclude the number only segments from the analysis because you have handled them first then how do you do this? We know from this article, “So how many words do you think it is?”, that Studio separates tags and placeables in the analysis… but we also know that placeables consist of numbers, dates and other variables. So doing the maths from the analysis alone is not enough. We also know that if the numbers were not actually recognised as numbers by Studio then they will be mixed into the word count anyway. Tricky? Certainly it was worth a little investigation…
So, here’s a suggested workaround based on the premise that you have prepared the Project and had already analysed it. I’ve used an empty TM for this example and get this analysis… it doesn’t have to be empty but it’s easier to see what’s happening like this:
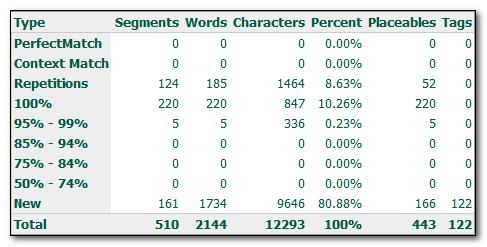
I used an empty TM in this example so that the analysis would show all the things that Studio considers an auto-localizable through recognition. You can see we have 220 100% matches. In the document a quick inspection reveals it contains these sort of numbers:
1
160
5.61
2,000
3.64%
So you’d think that perhaps this also means 220 numbers? Maybe not… so first of all I want to select all the segments that do not have number only segments in them and lock them. The easiest way to do this is first filter on something that won’t match any of the numbers above using a regular expression. I covered how to do this in the articles mentioned above but as a quick reminder you can use something like this that will find anything that has letters in it, uppercase or lowercase:
[a-zA-Z]
I can then lock these segments and filter on unlocked segments to see what’s left. If there is more left then either manually lock the odd one or two, or run another search to find the stragglers. Once you have only the numbers left, and I was lucky in my example as the first expression got them all, you can either allow Studio to auto-localize them if appropriate, or copy source to target and search and replace as needed (for a file with a lot of numbers search and replace may be faster). I would then select them all and change the segment status to “Confirmed” so they don’t get changed in error.
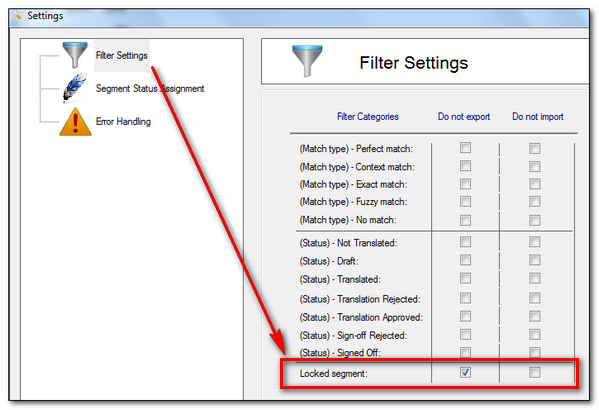
Now the fun part. You need to download if you haven’t already, the SDLXLIFF to Legacy Converter, and use this to convert all your files to TTX. But when you do this you use the option that excludes locked segments:
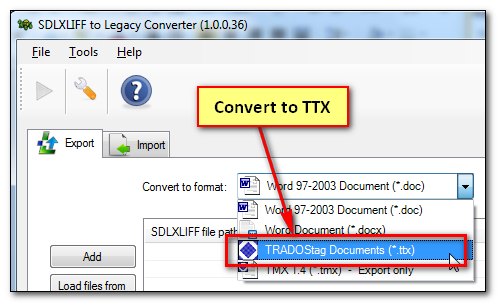
Now run the application and save all the files that are exported as TTX:
The file you will now have is a TTX that matches the segmentation of the Studio SDLXLIFF but contains only the number only segments. So now you only need to know how many segments there are and you’ll know how many numbers there are. How do you do that? The quickest way is to read the log-file generated by the converter:

But you could also add the TTX file to your project in Studio and read the quick analysis here underneath the file:
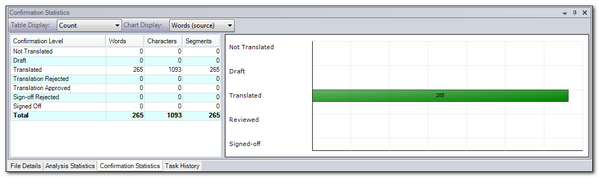
So going back the original analysis where we see 443 placeables it looks as though I can remove 265 numbers from this count so that my analysis for the translator would be based on something like this… and I do have to guess a little at where they are in the analysis if I do this:
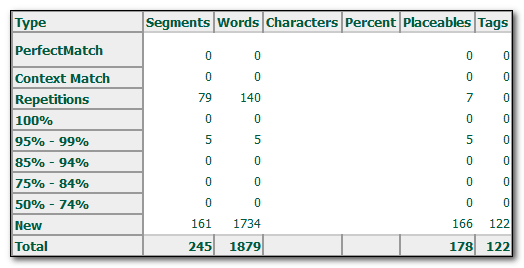
In my example the guessing was simple because each number only segment was handled as a single placeable and hence a single word, but it could be more complex. So I took this idea a little further and this time created a new TTX by locking all the numbers and exporting all the non number only segments… I used this expression (to suit my document):
^[0-9.,%]*
I then added this TTX back into my project and analysed both TTX files together… the theory being that they would add up to the original file… and they did:

The top analysis is the TTX containing the number only segments, and the bottom one is the TTX containing only the text for the translator. This verifies that each number only segment is a single word in this case, but if not then you’d have the information here to make the necessary adjustment. The summaries are exactly the same, but you can see a few small differences in the details that are probably related to the analysis of a TTX instead of a PDF (yes I actually used a PDF report that I found on the internet because it had lot’s of numbers in it, and the results were actually good… despite me not recommending PDF as the way to go most of the time).
But in general, I think if you are interested in the total wordcount so you can agree a sensible mechanism for paying the translator after you have locked down all the numbers in the original SDLXLIFF then it’s possible. I think a quick and simple reminder of the process would be good at this point, so this is what I did (a picture paints a thousand words):

Hope you found that useful… or at least interesting. I always find trying to answer these kinds of questions adds to my understanding of how Studio works… and sometimes helps to find useful ways of improving the product in the future… at least I hope it does.
Hi Paul, interesting idea, but how do you add your ttx-files to your original project, if you work in more than one language?
Good question! If you do this you will only be able to add the file to the relevant language pair in your project. So if you wanted one for all languages then you’d need a TTX for each language. The application in question can do this for each one in one go but it would be a lot of additional work.
A better solution is available in Studio 2014. You just lock all the number only segments and analyse the files again excluding locked segments!
Hi Paul,
I’m trying to use the regex ^[0-9.,%] to filter for segments that do not contain any letters, but does contain numbers or any other characters, (such as -, % and so on). It does seem to find what I need, but it also finds some segments with words. How can I exclude any alphabet characters from this expression?
As an example, it it does find a segment with “0.8 or less”, which I’d like to be out of the search range.
Thanks a lot!
Hi Dace, great question for the community again, we have a good forum for regex and xpath here.
I reckon you just need to add an assertion for the end of the line too, so maybe something like this:
^[0-9-,.%]+$
or maybe this:
^[^a-zA-Z]+$
Regards
Paul
Thanks a lot Paul, the version ^[^a-zA-Z]+$ seems to do the trick! If anything more comes up, I’ll ask in the community.
Regards,
Dace
Hi Paul,
Is there a better way to identify numbers only in the new versions of Studio? This here is great but involves too many steps and this can be done when working with just one or two files but not when you are a Project Manager preparing different projects with several files each every day 🙁
Thanks!
Yes. Today, if you handle the numbers first then just lock them in the Project and then exclude locked segments from the analysis. If this doesn’t answer your question (as I only suggested an easier alternate to the process in the article) then it would be helpful to understand what you are trying to achieve.
Thanks Paul!
I was expecting that answer. However, we are looking for a way to try and find out the number of placeables (especially numbers only segments) from a normal analysis without involving any manual/automatic tasks (without pretranslation and locking), in a way that we could analyse the files and check, for example, that the number of “recognized tokens” belong to segments that we don’t really need to touch, such as numbers only.
To sum up, we are looking for a way to remove the numbers only from the analysis without having to involve any additional tasks, but don’t know if the “recognized tokens” always refer to numbers only, or also dates only, or dates or numbers inside a segment with text… (which would be translatable) so not sure if removing the “recognized tokens” from the total is a good way to calculate the real wordcount without numbers and other placeables not needing edition (not sure if it’s clear…).
Thanks very much for your help!
The problem you have Elisa is that numbers are not reported separately from other placeables (excluding tags). This article explains. So if you want to exclude only these then you do need to do a little work across the project first. The SDLXLIFF Toolkit will make this reasonably easy as you can lock all the number only in one go based on an appropriate regex, and then when you run the analysis you exclude the locked segments. There is no way around this because things like numbers, dates, variables are all reported as recognised tokens in one big bucket.
Thanks very much, Paul, that’s very helpful! However, I tried with the sdlxliff files of a new project and it doesn’t work. It works only when I create the sdlxliff directly in the Editor View, opening the source file and saving right there. Do you know the reason for that?
I have tried different things, I have made sure the files were selected before locking the figures with the regular expression, I have worked with all files from the project together but also with individual files from the source and the target folder… Nothing works when using the files from the project, only with the files created individually in the Editor View, which is not very convenient :-/
Any ideas? Thanks again!
My guess if you are not using the right files… if you send me the project I can check and show you if you’re doing it wrong. email pfilkin@sdl.com
Thanks Paul, I just sent you an email.