 A few articles ago I spent time explaining how to use the TermInjector OpenExchange application from Tommi Nieminen which allows you to create dynamic variables based on regular expressions.
A few articles ago I spent time explaining how to use the TermInjector OpenExchange application from Tommi Nieminen which allows you to create dynamic variables based on regular expressions.
It is a pretty complex article and I had to reread it a couple of times to get my head around it again, and I needed expert help from Tommi, but it was worth the effort because this tool could prove to be invaluable for users who regularly have to deal with numbers in a document that are not recognised by Studio, or currencies that are not used in a way that Studio can automatically localize them for you.
You can read the other article for all the details and this time I’ll just show you how you could make use of this application to solve the problem of translating a document with numbers like these for example:
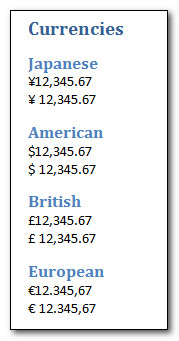
There are four currencies in here, each written in two different ways. So one with a space after the currency symbol and another with no space.
Studio uses the National Language Support (NLS) API Reference as you probably know and often this can result in the document you are translating containing placeables that should be autolocalized … but they are not even recognised.
Often the fastest way to handle them is to copy source to target and then search and replace to correct them afterwards. But if the placeables are in the text instead then this can start to get a little more complicated.
So if your document did contain non recognised placeables amidst text then what is the best way to handle them? You could copy source to target again and translate in-between the numbers, but then you lose all the benefits of the results from your TM.
This is where the TermInjector comes into its own. If I set up the TermInjector with a single rule made up of three regex expressions like this ( —> represents a tab between the groups of regex and is not part of the expression):
((¥|£|€|$))([0-9,. ]+) ---> 12 ---> (¥|£|€|$)[0-9,. ]+
And then do a Translation Memory lookup for each segment after only translating segment #3 I see this:
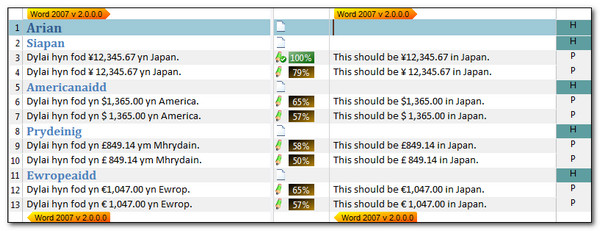
So each number has been automatically transformed according to this rule and inserted into the Translation Memory match by the TermInjector. The simpler number only segments could also be translated using the same rule:
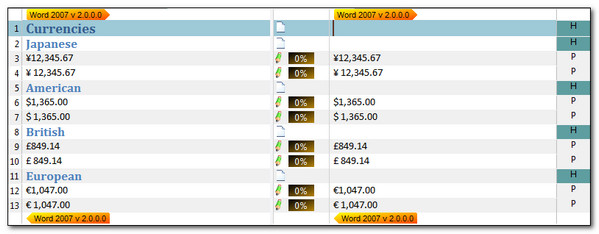
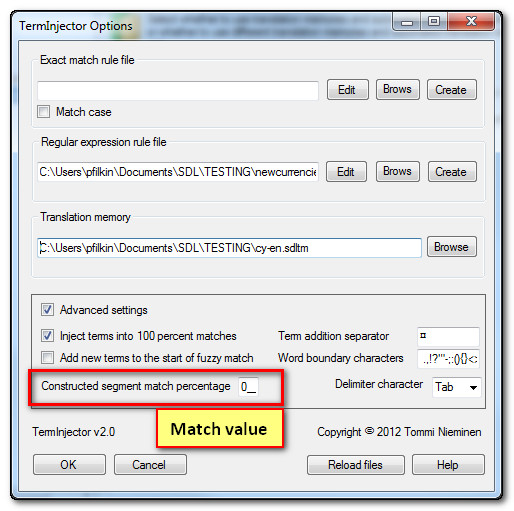
In this case the percentages are all 0% because there was nothing in the TM to compare this to in the first place. But if I wanted to there is a setting in the TermInjector to make these any value I like:
So a useful application from the SDL OpenExchange (now RWS AppStore) and I hope a useful rule you can “bend” to make it apply to your own particular use-cases.
I haven’t had much success getting TermInjector working, and this is a glaring hole in the basic functionality of Studio. This major regression renders Studio excessively cumbersome and effectively useless for me — my work is primarily financial, with scores of TUs that are identical in all respects except for monetary amounts.
Any word on a fix for this in Studio proper?
Hi Erik, maybe you can drop me an email, you have my address, and then I can be sure what I’m commenting on?
Hi Paul, I’ve been looking through the TermInjector documentation and I can’t get my head around it I’m afraid.
I’d like to add two rules for a specific client (es_CO en_US). One, a similar rule as the example you used above, with the only difference that the TT should have no space between the currency symbol and figure, regardless of whether or not the ST uses a space. And for the second rule I’d like switch decimal separators, e.g. $1.500,00 to $1,500.00 (BTW, would such a rule change number lists 1. […] 2. […] 3. […] to 1, […] 2, […] 3, […] ?)
I have no idea how to add expressions to the rules file, much less how to write these expressions, so any help you could offer would be greatly appreciated.
Best regards,
Richard
Hi Richard, I’m on leave for the next two weeks, but the best person to help you is the developer. Tommi is extremely helpful so I suggest you contact him through the support page for his application on the OpenExchange website.