 Now that we’ve learned enough about regular expressions, and because I get so many requests for custom filetypes I thought it might be useful to take a dip into the world of XPath. So what exactly is XPath?
Now that we’ve learned enough about regular expressions, and because I get so many requests for custom filetypes I thought it might be useful to take a dip into the world of XPath. So what exactly is XPath?
Well as far as most CAT tools go it probably is something completely different… certainly it was not used in the old Trados days. But as a tool it’s nothing new and is simply a language used to find parts of an XML document and what’s more it’s a language that is recommended by the World Wide Web Consortium W3C. So there is nothing proprietary here.
If you did dive in and start to look at this documentation I referred to it may, unless you lean towards the technical side, be a little off putting. But in reality, as far as we are interested for most applications in Studio, the phrases “keep it simple” and “economy of accuracy” apply. To try and illustrate this let’s look at some examples in Studio. Let’s take a simple XML file that contains some translatable text:
<?xml version="1.0" encoding="UTF-8"?> <xpath> <Title>An explanation of XPath in SDL Trados Studio</Title> </xpath>
In this file there is one translatable element called <Title>. If I create a new filetype to extract this text I would import the XML file and the parser rules would look like this:

The <xpath> element is the root element and I don’t need this as a parser rule so I’ll remove it in a minute, but for the time being take a look at the “Rule” column. Here you see two rules; //Title and //xpath. If I edit the //Title rule I see this:

So as expected the first rule is just me importing the file and Studio taking the element <Title> and making the content in it translatable so that when I open the file in Studio all I will see is the text inside the <Title> elements. But what you may not have known is that the //Title in the rule column is actually an XPath expression. Pretty simple huh? It even looks like the syntax you would use for navigating folders in windows explorer. So for example, I can add some more translatable text to my example file like this:
<?xml version="1.0" encoding="UTF-8"?> <xpath> <Book lang="en-US"> <Title>An explanation of XPath in SDL Trados Studio</Title> <Text>XPath helps to <b>navigate</b> through the file.</Text> <Text>It helps you pick out important <bn>brand names</bn></Text> <Notes> <Text>This should not be extracted.</Text> </Notes> </Book> </xpath>
So, if I wanted to create a rule using XPath that picked out the <Text> it could look like this:
//Text
But if I did this I would get all the <Text> inside the <Notes> element as well and I don’t want that. So instead I can be more specific like this:
//Book/Text
This way it will not pick up the <Text> element in here, //Book/Notes/Text, even though they have the same name.
In this example I would add similar rules for the <b> and <bn> elements and I would make them inline tags so the sentence does not break. Then I’m going to add a rule that says do not extract anything at all unless I specifically tell you with one of my rules and I do this by using a wildcard. XPath understands the star symbol to mean select everything… so I add the rule like this and I make it a non-translatable rule where everything else I made “Always translatable”:
//*
This would give me a set of rules like this (I also took a little liberty to apply some simple formatting to some of the rules):

The file, when I open it in Studio looks like this:
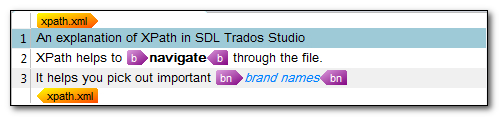
So, all very simple and straightforward. But what happens if the file contains translatable text in an attribute instead of an element? I don’t think this is really good practice, but we all know that in real life this happens all the time. So what if the file looked like this where the title of the document has been moved into an attribute called mytitle?:
<?xml version="1.0" encoding="UTF-8"?> <xpath> <Book lang="en-US"> <Title mytitle="An explanation of XPath in SDL Trados Studio" /> <Text>XPath helps to <b>navigate</b> through the file.</Text> <Text>It helps you pick out important <bn>brand names</bn></Text> <Notes> <Text>This should not be extracted.</Text> </Notes> </Book> </xpath>
If you were to import this file into Studio and then manually add the rule for translating an attribute like this:
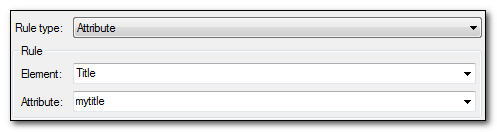
Then you would again see in the “Rule” column that the XPath expression is defined for you like this:
//Title/@mytitle
So again this is pretty simple… but of course an attribute is usually a tag so now you will see the document structure column on the right annotates the translatable content as a tag:

At this stage, because Studio has made this so simple you would be forgiven for wondering why you need to know anything about all of this syntax at all. Hopefully you’ll always receive simple files and never need to. However… sometimes things are not so simple and this is where XPath comes into its own and you can enter an XPath expression as the new rule here by selecting XPath instead of the element or attribute:
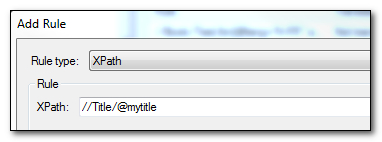
Let’s take a little more complex scenario to see how this works, if our file now contains things that look like this where an attribute value is used to instruct you whether the name should be protected from translation or not:
<Text>Non-translatable <bn lock="y">brand names</bn> are locked</Text> <Text>Translatable <bn lock="n">brand names</bn> are unlocked</Text>
You still want to see the name, but you want to ensure that the translator will know it has to remain exactly the same. So here you use a new “Not translatable” rule to identify this change so that when the attribute lock= has a value of “y” then the content should be protected. The syntax for this uses a reference to the attribute value inside square quotes as follows:
//Book/Text/bn[@lock=”y”]
In Studio when I open the file with this new content I now see this where the protected brand names have little padlocks around them and when the tag is copied to the target you will find the text inside is greyed and cannot be changed at all:

You can even string together attributes. So if the XML file was a multilingual XML file for example, and each part of the file was repeated to allow space for each language like this:
..... <Text>These <bn lang="en-US" lock="y">brand names</bn> are locked</Text> <Text>These <bn lang="en-US" lock="n">brand names</bn> are not</Text> ..... <Text>These <bn lang="de-DE" lock="y">brand names</bn> are locked</Text> <Text>These <bn lang="de-DE" lock="n">brand names</bn> are not</Text> ..... <Text>These <bn lang="fr-FR" lock="y">brand names</bn> are locked</Text> <Text>These <bn lang="fr-FR" lock="n">brand names</bn> are not</Text> .....
Then in order to prepare a multilingual project with filetypes that extracted only the text for the appropriate language codes you could adapt the same rule we just added for the locked content like this… based on extracting the French translatable text only by stringing together the attributes using natural language queries:
//Book/Text/bn[@lang=”fr-FR” and @lock=”y”]
So now Studio would only extract the text you need from the strings that have the lang=“fr-FR” attribute as well as paying attention to the need to lock content if the lock attribute is “y”.
There are so many things you can do with XPath to manipulate the information in the XML file that was quite tricky, if not impossible, with the older versions of the product that I couldn’t possibly cover them all here. So if you want to learn more about XPath I would recommend you take a look at the W3 Schools website where they have many really useful tutorials about web programming and one of these is all about XPATH. You can find the relevant material here : w3schools.com XPath tutorial.
I hope this article was useful and not too geeky… but just to finish off here’s a few examples of things I have used XPath for in the past that might be handy if you come across similar questions when preparing filetypes in Studio for some tricky situations:
//*[@translate=’yes’]
Where you have translatable content in this fashion with any element containing the attribute translate, <BodyText translate=“yes”>, then this expression can be used to extract all translatable text.
//A[@M = ‘8804’]/V
You need the text in <V> but only where M=”8804” in <A>. For example:
<A M=“8804”><V>Beschreibung zum Task</V></A>
//journalItem[@id=’journal1′]/dialog/object/@text
Translating the content of an attribute with an element defined by a different attribute. So the translatable content is in the text attribute but only where the attribute id=‘journal1’
//book[@lang=”fr-FR” and @translate=”y”]/ul/li
A way to check for two matching attributes and then the subsequent elements in the path.
Very nice, Paul. This goes in a direction I have hoped others would take for dealing with other aspects of translation data, but I never thought of this particular approach. Score one for SDL 🙂
Thanks Kevin. Interestingly this is an underused capability that has been in Studio since 2009.
Underused? No doubt. Under-publicized as well, probably. I’m glad you did this post.
Actually, we did use this a lot. Great feature. Nice that one can automatically use the content inside the XML tags as HTML. Is it fixed so it also works for attributes?
Not easily… you still need to handle the attributes for embedded content with regex. An improved solution is on the cards but I’m not sure when it will be ready yet.
Great article, once again! I was just wondering about whether to use single or double quotes for attribute values. The examples are not consistent in this aspect(@lang=”fr-FR” vs. @id=’journal1′). I guess both works, but single quotes is the official recommendation?
Hi Christine, well spotted! Actually the reason I used one or the other was because this is how the attribute values were contained in the XML files I was using. I did have a problem with this on one particular file a long time ago until I realised I was using different types of quotes so ever since then I always copy and paste whatever is in the file to be sure they match. It may be that sometimes different quotes don’t matter… but I prefer to err on the side of caution.
Wooho! I was not alone! I’m working for a translation agency and one of my missions is to create specific file types for our customers. When I began to work with XPath, I was really excited but…not one of my colleagues has understood “the beauty of the thing”, probably too geeky… 😉 Thank you for your good posts! It’s every time a pleasure!
Hi Stéphanie, you certainly are not and I’m glad you enjoy the posts. Sometimes I feel a little too geeky as I write them… but then I remember I’m not clever enough to be a real geek! I think these little details are the things that really are the little known strengths of Studio.
Hi Paul, always a pleasure reading your blog (I’ve been bracing myself to download RegexBuddy, but haven’t gotten to it yet :P)
I came across this post when actually searching a solution for a tricky situation we have using Studio. We have an ongoing software localization project (I’m the PM) from a relatively rare language, and we’re asked to use ttx files created from their original xml. The vendor we have uses Studio, but he’s still a relative newbie to the world of CAT tools and doesn’t work with, and is quite baffled by, Tag Editor.
The issue is in the ttx files themselves. Along with the source and target segments, and the other usual ttx stuff, there’s an additional row. Something like:
(TrU)
(context) [really important instruction related to the segment below]
(source segment with language software stuff)(target segment with localized software stuff)
From what I’ve been reading, here seems to be an element. So my point is: Is there a way that doesn’t require a CS degree to display this info in a non-translatable way in Studio (tooltips, comments, anything)? There are a lot of workarounds, I know, but they all slow our workflow considerably and we usually have tight deadlines for this. Any ideas? Or are we better off asking a computer engineering graduate to write a custom filter for us? (or am I an idiot and it’s the simplest thing there is? :D) Thank you for your help 🙂
Hello João, I’m not sure whether you mean open the TTX in Studio or the native XML? Either way it’s possible. With TTX you create the ini file to set the element containing the comment as non-translatable and then the preview in 2014 for TTX will allow you still see the comment as you would in TagEditor. But if you want a better experience then just create a stylesheet to go with the XML and then use this to preview the comments. It’s not necessarily that hard to do and I did write an article on how to create a simple stylesheet for a custom XML filetype here : Translate with Style. If this doesn’t help you feel free to drop me an email and I can see whether I can help you easily or if we do need to find a rocket scientist 😉
Hello Paul,
I am trying to process a dita file with an element which is not declared- Studio says that the child element is invalid, and then lists a series of elements it is expecting. Where can I add to that list?
Hi Dave, sounds more like a problem being reported on the file itself as opposed to the rules.
Yes- it could be. I’ll go back to the client.
Dear Sir
Thanks for these valuable info; Can you Please help me to prepare this small file (Sample) using Xpath; I need only to translate the elements that have [lang=”en-US”] ONLY.
Thanks in advance
——————————————————————————————–
<?xml version="1.0" encoding="UTF-8"?>
<xpath>
<Book lang="en-US">
<Title mytitle="An explanation of XPath in SDL Trados Studio" />
<Text>This <bn lang="en-US">EN</bn> Text</Text>
<Text>This <bn lang="de-DE">DE</bn> Text</Text>
<Text>This <bn lang="fr-FR">FR</bn> Text</Text>
<Notes>
<Text>This should not be extracted</Text>
</Notes>
</Book>
</xpath>
——————————————————————————————–
Maybe worth you reading this post too… Disappearing forum posts! Having to write with entities in forum posts is a common problem!
On your example, which is a little odd if you you don’t mind me saying so as the parent element for these:
<Text>This <bn lang="en-US">EN</bn> Text</Text>
<Text>This <bn lang="de-DE">DE</bn> Text</Text>
<Text>This <bn lang="fr-FR">FR</bn> Text</Text>
Is this:
<Book lang="en-US">
This makes it a little unclear what you actually want to extract. Also on the Text elements you have the lang attribute for the letters EN, DE and FR only. So what do you wish to see extracted? The expression needed to pick up the entire Text element based on a child attribute will be very different to picking up the bn element.
For example. This will get you the attribute in the Title element which is a child of : <Book lang="en-US">
//Title/@mytitle
This will get you all the Text elements which are also children of <Book lang="en-US">, and I made the bn element inline.
//Text
//bn
If you only want the en-US lang attributes then you could do this:
//bn[@lang=”en-US”]
//bn[not(@lang=”en-US”)]
Make them both inline with the first being translatable and the second being non-translatable and then you’ll keep the sentence structure but lock the DE and FR text as it doesn’t have the lang=”en-US” attribute.
If what you meant was that only text that has a child element with the lang=”en-US” attribute should be extracted even though the parent might be lang=”en-US” for them all then maybe something like this:
//*[bn/@lang=”en-US”]|//bn[@lang=”en-US”]
Hopefully there will be something in here to help you…but I hope you can see how not being clear with your question makes it pretty difficult to answer precisely.
A lot of thanks sir for your help and i’m sorry for the unclear question.
No worries… it was fun playing around with it.
Hi Paul, I am working on setting up a preview in Studio 2014 using an XSLT stylesheet. I only want to show certain elements from the xml that I am translating in the preview (in my case, only index entries). This works fine. What doesn’t work though, is when I want to only show the index entries that are *not* nested in content that is tagged in the XML as locked. Studio does not seem to recognize the “ancestor” xpath function from “http://www.w3.org/2005/xpath-functions”. The error message that I get when I refresh the preview says something like “A script or extension object cannot be found that is allocated to the namespace ‘http://www.w3.org/2005/xpath-functions’ “. Is this because these xpath functions are xpath 2.0? Does Studio not support xpath 2.0? Thanks for your help!
What is the ancestor xpath function? Studio doesn’t support xpath 2.0 but it would be useful to know what you tried to do as it sounds achievable.
Hi Paul,
thanks for your reply.
If studio does not support xpath 2.0, then does that mean that the functions listed here http://www.w3schools.com/xpath/xpath_functions.asp are not supported?
That was what the error message in Studio seemed to suggest, as Studio does not seem to recognize the namespace for these functions:
“A script or extension object cannot be found that is allocated to the namespace ‘http://www.w3.org/2005/xpath-functions’ ”
I don’t think I explained myself clearly in my last post (apologies for that) => the function I was hoping to use in my stylesheet was –fn:not– in combination with the –ancestor– axis, see: http://www.w3schools.com/xpath/xpath_axes.asp.
Here’s the relevant code:
If the fn functions aren’t supported I will have to think of something else 🙂
You can use these: http://www.w3.org/TR/xpath/#section-Function-Calls
Hi again Paul,
I’m looking for an XPath rule to block all nodes in an XML file with cms:tstatus attribute valued “Released”. It can be any element node actually, so I’ve came up with: //*[@cms:tstatus=”Released”] (Any element with attribute cms:tstatus with value “Released”. I’ve specified it’s not translatable but still, Studio reads those segments.
Tried these variants too:
//*/*[@cms:tstatus=’Released’]
//*[@cms:tstatus=’Released’]
//@cms:tstatus=”Released”
None seems to work. Thought that maybe the CMS: is causing the issue, so removed it and changed the rule to only tstatus, but didn’t work either.
Any thoughts of what I’m doing wrong? Here’s a sample of the code:
Namespaces can be tricky… can you share an example of a full file with me?
Just to close this one off… the key was to exclude all other elements first with //* because all elements were being extracted in addition to the rule. So two rules:
//*[not(@cms:tstatus=”Released”)] Always translatable
//* Not translatable
Hi Paul,
I have an issue with the xpath in Studio 2014, and here is the snippet below,
Symbol
Symbol
Name
Name
Description
Description
I only need to translate the elements starting with “valore” and the xpath I wrote is //*[starts-with(name(),’valore’)], but it does not work, but if I delete the namespace declaration in the root element, it works again.
Any ideas? Or how to refine my xpath expression?
ehh, where is my reply? Just in case I re-input here, and a sample file is also uploaded to:
https://drive.google.com/file/d/0ByEfTbr5Wp72WWxtYU1vY25rYmM/view?usp=sharing
I just need a working version of xpath to extract “valore” element.
I’m on leave and you shouldn’t expect a reply either, especially when you don’t use markup for your details and I can’t even read the snippet. I recommend you use this forum to post questions on xpath… it’s specifically for this purpose.
Thank you Paul, will do that.
update:
I tried in Altova XMLSpy, and the xpath works, so I think there must be something wroing with Studio.
Dear Paul,
I have a problem with inline tags and/or parsing with this xml file:
I need to translate “These are old ashes##They are nothing but faint dust.”
I used your instructions for translating, and I got a translatable content.
Rule
Rule type: xpath
XPath: //String/@value
Translate: Always translatable
Tag type: structure
Whitespace: Inherit from parent
Structure Info: Text Area;
In embedded content (legacy) I checked the “Enable embedded content processing”, add “sdl:text-area”, and in the “Tag definiton rules” add an Placholder with ## tag.
The problem is, the ## in doesn’t appear as a tag.
Maybe the best solution will be if the Trados parsing/split “These are old ashes##They are nothing but faint dust.” to two lines.
## appear as a tag is also good and will be useful for further projects.
I tried many variations in parser rules (and of course search in the web), but none of them worked.
Can you help me?
Ehh, the engine removed the xml code.
I shared here the example:
https://drive.google.com/file/d/0By0bUoUAQEsyZlBjLWZLX3cyY0k/view?usp=sharing
ok – I can see the code now and this is an attribute. So you can’t use the embedded content processor for this. I’d need more info to help reproduce the problem though as nothing should be removed in the target file. Please can you post this into the aforementioned forum and we can discuss it more easily in there.
Hi, it would probably be better if you asked this question here, SDL Regex and XPath Forum, it’s easier to show the code without formatting issues and to share images etc.
Based on the rule you’re showing you are trying to extract text from an attribute but this is not clear from your example text. If it is an attribute then you cannot use the embedded content processor for this as this will not work with text within an attribute.
Ok, I asked this on the forum. I understand if in this case the inline tags can’t working. I don’t know which more information would you like, but I wil do my best 🙂
Thank you, Paul; this answers my unspoken question.
With kind regards,
Adam Warren.
Hey Paul,
it’s 2019 and it’s still very useful 🙂
Thank you!
Łukasz