 I’m onto the subject of leverage from upgraded Translation Memories with this post, encouraged by the release of a new (and free) application on the SDL OpenExchange (now RWS AppStore) called the TM Optimizer. Before we get into the geeky stuff I want to elaborate on what I mean by the word “leverage” because I’m not sure everyone reading this will know.
I’m onto the subject of leverage from upgraded Translation Memories with this post, encouraged by the release of a new (and free) application on the SDL OpenExchange (now RWS AppStore) called the TM Optimizer. Before we get into the geeky stuff I want to elaborate on what I mean by the word “leverage” because I’m not sure everyone reading this will know.
Let’s assume you have been a translator for years (English to Chinese), and you always worked with Microsoft Word and Translators Workbench. TagEditor came along, but you didn’t like that too much so you kept working with Word and Workbench. It had its problems, but until Studio came along and in particular Studio 2014, you were still quite happy to work the same way you had for years. But now you wanted to buy a new computer, and you really liked the things you’ve been reading about Studio 2014 so you took a leap and purchased a license of Studio. The first thing you want to do is upgrade your old Workbench Translation Memories so they could be reused in Studio. You’ve got around 60,000 Translation Units in one specialised Translation Memory and you really need to be able to have this available as soon as possible to help with a job you know is just around the corner. You upgrade the Translation Memory and this worked perfectly!

There were 182 errors reported, but when you looked into the details this was just some segments that only contained source and no target, some number only segments and some duplicates. You knew that of course Studio doesn’t need these things and so expected a slight reduction… actually you were ready for more than this so everything looks great so far. You did have one other error reported in the details and this was “TagCountLimitExceeded”. I cut this screenshot down to fit it in but the number of lines in the target compared to the source has increased some 20x for all the errors reported this way (the sea of blue and red text are all tags):

In fact the number of lines for the target segments compared to the source in the Workbench TMX I exported for upgrade seems to be pretty consistently expanded like this. So I guess only the really long ones have exceeded the number of tags Studio can handle in a single segment. This one had over 1800 tags in one segment so I don’t really expect to see this too often! I am wondering how Studio will handle this if I do though!
I put this to the back of my mind as my Project arrives. It’s an update to a document I translated last year so I know I can expect some good “leverage” from this. What do I mean by this? Well, I mean that many of the segments should be providing me with 100% matches from my Translation Memory because I’ve done this text before. So good “leverage” is 100%, bad “leverage” for me is going to be less than 85% for this text because my experience with this specialist material from the past, translating with Microsoft Word and Workbench, was that “leverage” less than 85% didn’t help me a lot and I preferred to use the concordance feature.
I start work, and then I notice something strange. A segment I know that provides me with a 100% match in Workbench is giving me a 99% match in Studio 2014. In the screenshot below, the top pane is my segment in the translation editor, and the bottom pane is showing the Translation Memory results:
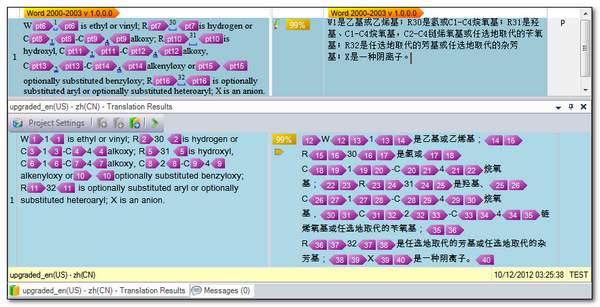
The reason for this 99% match appears to be a missing formatting penalty but it seems to have the same number of tags in the source so I’m confused. But the other confusing things about this screenshot are that the target segment has not got any tags in it at all, despite them being shown in the Translation Memory results window; and since I am displaying the tags in TagID mode I can also see that the numbering is different and the source and target tags in the Translation memory do not have matching number sequences; and there are significantly more tags in the target than in the source. So quite a few things appear to be wrong here.
Out of interest I test this in TagEditor, and here things are even worse as I get no match at all even with my settings reduced to 30%. The problem here is that TagEditor finds more tags in the source than are in the Workbench Translation Memory… and of course this is one reason TagEditor was unpopular for users migrating from Microsoft Word when it was first launched:

But at least Studio does a better job of providing leverage with the upgraded Translation Memory, but it’s still not good enough for me as I want and expect 100% matches for work I have done before! If I translate this sentence in TagEditor and confirm it to the Translation memory, and then upgrade this Translation Memory then the match in Studio is 100%. But this doesn’t help me at all because I need to get from Microsoft Word to Studio. It’s all very confusing!
Why is this happening?
The clue was in the earlier error messages when I upgraded the Translation Memory. Too many tags! The Translation Memories that were created by using the Microsoft Word interface with Trados 2007 and earlier add a huge amount of additional formatting information. To make matters worse, the tag definitions in the Translation Memory don’t even match between source and target. Studio tries to match the tags between source and target but fails because the content is different. Take this small example made up to demonstrate the point:

In the example above you can see that the source only holds one tag definition and in the target you have three tag definitions where none of them fully match the source. Both of the tag definitions with f46 can be removed as they don’t hold any important formatting, and this will leave you with only the subf2 tag definition. You could then sync up the content of the tag and the tag ID from the source so they matched. This doesn’t sound too tricky and I’m already reaching for regex buddy to have a go (based on the real TMX and not the example above):
Search for this:
(<bpt i="d+">){\w+ </bpt>(p{IsCJKUnifiedIdeographs}+)(<ept i="d+">)}</ept>
<bpt i="d+">{\(sub|super)\w+ (</bpt>)(d+)<ept i="d+">}</ept><bpt i="d+">
{\w+ </bpt>。<ept i="d+">}(</ept>)
Replace with this:
$2$1<cf $4script="on">$5$6$3</cf>$7
But then I realise this is just one example and once I’ve got to here with my regular expression, upgrade the TMX and it looks fine, I realise this doesn’t work for another more complex scenario. It’s also incredibly tedious and not for anyone who doesn’t like playing around with this stuff.
Fortunately help is at hand in the shape of the TM Optimizer which is a free application written by a far more capable developer than I am a regex creator! All I needed to do was start the application, select my TMX, and run it. A short while later I see this:

Wow… 731,546 unnecessary tags removed. That’s nearly a million superfluous tags created by the Microsoft Word and Workbench combination. Furthermore an additional 205 thousand tags were updated to make sure they had the appropriate matching TagIDs. I think I would have been there a while playing with regex buddy! If I open my file in Studio using this “Optimised” Translation memory I see this:

Much better!
If you have already upgraded your old legacy Translation Memories (the ones created with Microsoft Word and Workbench as this was not a problem if you used TagEditor) then the good news is that as long as you still have the original TMX you can “optimise” your Studio Translation memory with this application too.
 So a bit of a geeky post this week, but I thought it would be worth trying to explain what the problem is with upgrading these old Translation Memories because the question does come up from time to time. You can import your TMX as text only and this of course won’t have the unnecessary tags; but it will also be missing the necessary ones and you still won’t get the best leverage. You can also use Olifant and remove only internal tags, but even here it’s not selective enough to do the job that the TM Optimizer is capable of.
So a bit of a geeky post this week, but I thought it would be worth trying to explain what the problem is with upgrading these old Translation Memories because the question does come up from time to time. You can import your TMX as text only and this of course won’t have the unnecessary tags; but it will also be missing the necessary ones and you still won’t get the best leverage. You can also use Olifant and remove only internal tags, but even here it’s not selective enough to do the job that the TM Optimizer is capable of.
I hope that was a useful post as I’m having second thoughts about posting it as I come to the end, mainly because it’s such a geeky topic. But hopefully the easy solution will be of interest for anyone who has encountered this problem when expecting better leverage from their upgraded legacy Translation memories.
So it’s posted!
Thanks, Paul! How does this compare with the built-in remove tags command of Trados 2014?
Hi Mina. Well, as I mentioned in the article if you remove all tags you will lose leverage because it’s all or nothing. This tool removes the superfluous tags placed there by Word and Workbench, and it corrects mismatched tag IDs. So no comparison really.
Many thanks, Paul!
Nice one Paul – What I like most is your very accurate description of us – the translators that hung on to Workbench until now! Cheers, Giles / Austria
“as long as you still have the original TMX you can “optimise” your Studio Translation memory with this application too”
That means that exporting the tmx from Studio will not help much?
It won’t help at all as it’s a different TMX by this time.
Very timely for my purposes, Paul, so thanks for posting this.
I know this is an old article, but I wonder if you can help with a related problem we are struggling with. We have some 2007 TMs in which the characters are represented with tags. We would like to upgrade these to 2014 TMs while getting Trados to understand that these tags are actually , and to show them as such in the new TM (so that a source text like “” would be a 100% match and not a fuzzy match).
If you have any advice, we’d be delighted. Many thanks.
Hello Nadya, have you tried using the app I talk about in this article? If this doesn’t get you there, and it sounds as though it won’t (I can’t see your examples?), then perhaps you need to do some manual work on an intermediary format like TMX. Can you recognise the letters from the tag content?
One question though… if they are tags why are they? Would they be represented by tags in Studio too? Surely this depends mostly on the format of the files they are coming from?
Hello Paul, thanks for your kind comment! I’m sorry the examples didn’t show up; that makes my comment considerably less clear, I see. The characters represented by tags are angle brackets. (Not as in tags: as in component names like “Lever 1” and so on, with brackets surrounding the “Lever 1” text.)
I did try using TM Optimizer, but while it removed some tags it didn’t help with these; my guess is that it considers them necessary tags and doesn’t realize that they started out as angle brackets. So in the 2014 TM they remain the same tags as in the 2007 TM.
I have no idea how they got that way in the first place; these TMs predate me at the company by a good few years. My best guess is an unhealthy collaboration between Trados 2007, Prosperas, S-Tagger to convert mifs to ttx, and anybody’s guess what else….
We know what they are, but short of going through the whole TM to replace them manually, we can’t come up with a good way to get the TM to notice, hey, these are actually supposed to be brackets, not tags! I’m not sure this can be solved other than by time travel at this point; if you have any ideas that would be great, but I don’t want to take too much of your time. In any case, many thanks.
Hi Nadya, tricky indeed. I think your only option would be to export to TMX and search replace to get the formatting you want. It may not be too difficult if you can use regular expressions to identify exactly what you need and not break something else.
Hello Paul, thanks very much for thinking it over. It looks like my boss has been able to handle some of it with regular expressions. As for the rest of it, well, we will start working on time travel. 😉
I appreciate your help.
When you figure out the time travel bit please let me know!!