 Chapter One
Chapter One
“Gabriela descended from the train, cautiously looking around for signs that she may have been followed. Earlier in the week she’d left arrangements to meet László at the Hannover end of Platform 7, and after three hours travelling in a crowded train to get there was in no mood to find he hadn’t got her message. She walked up the platform and as she got closer could recognise his silhouette even though he was facing the opposite direction. It looked safe, so she continued to make her way towards him, close enough to slip a document into the open bag by his side. She whispered ‘Read this and I may have to shoot you!’ László left without even a glance in her direction, only a quick look down to make sure there was no BOM.”
László needn’t have worried, because the document was encoded, there was no BOM… so if he had attempted to read it in any of the languages provided apart from English he’d see something like this:

Unfortunately the end user he was delivering the file to couldn’t read it either! The problem I’m introducing with a very loose link indeed is one of encoding, but not the secret kind! Every now and again we see the subject of “character corruption” coming up on the forums, and I get the occasional email on the same topic, so I thought it would be useful to explore this a little and look at the reasons for it happenning. But first let’s take a look at the original file, in this case an html file:
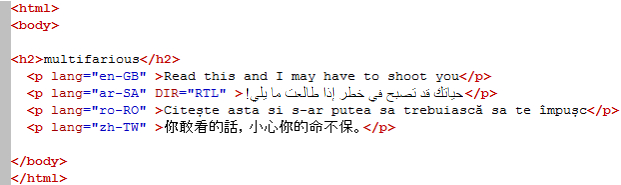
There’s not much wrong with this (thank you Sameh, Romulus and Chun-yi for the transcreations… I know who to send Mats to if he ever gets around to writing that novel!) and it displays perfectly in my editor. So why do the characters become completely illegible for Arabic and Chinese, and partially illegible in Romanian when I open this file in my browser? More importantly how do I explain it when I barely understand it myself! Let’s start with an explanation adapted from the W3C writings on this topic.
Written characters whether they are letters, Chinese ideographs or Arabic characters are assigned a number by your computer. This number is called a code point. You’ve probably heard the phrase “bits and bytes” before which are units of your computers memory, well each code point is represented by one or more bytes. Eight bits make up a Byte, 1000 Bytes make up a Kilobyte (KB), 1000 KB make up a Megabyte (MB) etc… and I’m sure you recognise these terms, which are all just units taking up space in your computers memory. The encoding I mentioned earlier, properly referred to as character encoding, is a key that maps code point to bytes in the computer memory. This graphic adapted from one shown on the W3C webpages explains this quite nicely.
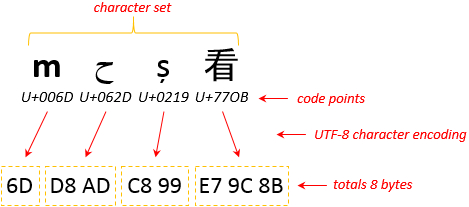
The key, or character encoding, I used here was Unicode UTF-8. The bytes are represented by a two digit hexadecimal number (sometimes a useful way to view files as we’ll see later) and you can see how the simple letter “m” is represented by a single byte, whereas the more complex ideograph “看” requires three bytes. If I used a different character encoding for this, say ISO-8859-6 you can see that only the “m” and the Arabic “ح” are displayed correctly:
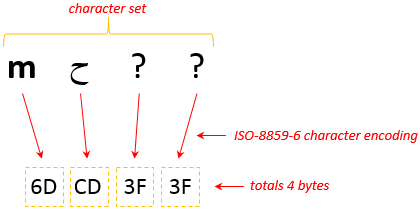
The Romanian letter “ș” and Chinese ideograph “看” cannot be displayed and this is because the character set supported by ISO-8859-6 does not extend to these characters and they are replaced by a question mark in my editor. The same Arabic “ح” character only takes a single byte when using this character encoding. So in simple terms if you have the wrong key then you can’t decode the characters and as a result they are displayed incorrectly. This of course begs the question how many keys are there? Well, there are a lot and most are the result of legacy systems which were developed to allow a computer to correctly represent different types of fonts supporting different languages at the time. So the ASCII character set (a character set is simply a collection of more than one character) covers letters and symbols used in the English language; the ISO-8859-6 character set covers letters and symbols needed for many languages based on the Arabic script. My text editor offers 125 different character sets. All of this can be further complicated by the type of browser you use because not all browsers are equal and even versions of the same kind of browser can display things differently.
If you had to display characters on the same page that required different character sets it was a very complex scenario because you cannot mix more than one character set per page, or file. Fortunately today the recommended character set to use almost all the time is Unicode UTF-8 which I used for first example above. Unicode UTF-8 is also a W3C recommendation because it contains all the characters most people will ever use in a single character set and it’s supported well by all modern browsers.
.
The BOM!
So, if UTF-8 solves all the problems then why do we still see problems when UTF-8 has apparently been used? Continuing along the same espionage theme we have the BOM. Not a misspelling, although in some ways it can act like a BOMB when all the characters appear to be corrupted and you can’t read the text! The BOM (Byte Order Mark) is a series of bytes that can be placed at the beginning of a page to instruct the tool reading it (such as a browser) on two things:
1. That the content is Unicode UTF-8
2. What order the bytes should be read if the file is encoded as Unicode UTF-16
The latter, UTF-16, is something you will hopefully not come across today because it was used around 1993 prior to UTF-8 and as interesting as it is I’m going to refer you to this page if you’re interested to learn more on that. I also read on the W3C pages that according to the results of a Google sample of several billion pages, less than 0.01% of pages on the Web are encoded in UTF-16. So for today’s use let’s stick to UTF-8 and take a look at how this tells the browser that the content is UTF-8 encoded. The first thing to note is that in keeping with our espionage theme the BOM is invisible to a simple editor, so if you open it up with Notepad you won’t see anything more than the content you wish to display. This is important because if you don’t know about this then the reason for the display issues we see at the start of this article could remain a mystery that a project manager could blame the translator for and neither know enough to explain why… often this means the translation tool unfairly gets the blame.
The way to see it is to look at the file in an editor that supports Hexadecimal editing, so one that allows you to see the content at the low level bytes. I use EditPadPro for this, but UltraEdit has a Hex Editor and I believe NotePad++ has one too. If I open the file László received at the start and view it as hexadecimal the start of the page looks like the top image:
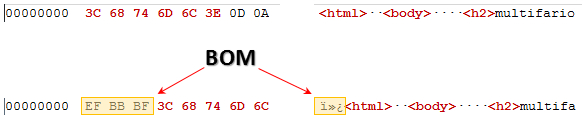
The bottom image is what it would look like with a BOM. These three bytes EF BB BF also represent a “zero width no break space” which is why you can’t see it, but today its use as a “zero width no break space” is virtually redundant so its primary use is as a BOM. The reason the BOM is so important is because its prescence tells the application reading the file that it is UTF-8. So in the html I showed you at the start of the file the bit you were unable to see was that it had no BOM. If I add the BOM and then give the file to László he’d be able to read it and then I’d have to shoot him… which of course I don’t want to do!
If you need to add the BOM you’d need a decent editor such as the ones I mentioned to be able to add it, or maybe use a tool such as the File Encoding Converter from a master of useful tools and applications for localization and espionage, Patrick Hartnett. This tool supports the changing of encoding for loads of files in one go… an essential tool for anyone regularly dealing with these kinds of issues.
.
Declaring the encoding
Phew… this is getting complicated, but I haven’t finished yet!! The lack of a BOM in the file only causes potential problems if the correct character encoding is not declared in the file in the first place. The W3C recommendation is that this declaration is always made. If the file is HTML then I could rewrite my file like this for example including the meta statement in my header, or as I have done here having omitted the head element altogether, before the body (html is very forgiving!):

This time it wouldn’t matter whether I had a BOM or not, the characters would all be displayed correctly in my browser. Now in theory if you use a BOM, browsers since HTML 5, are supposed to take this in preference to whatever the encoding is, but not all browsers respect this precedence so I believe the recommendation would be always declare, and don’t use the BOM! The other advantage of declaring is that you can always see the intended encoding and hopefully avoid problems where it’s driven by invisible bytes.
Now I’ve used HTML for the example here, but similar problems can occur with XHTML as well… so the W3C have published a recommended list of DOCTYPE declarations to help ensure these kinds of problems are minimised. They also publish a summary of character encodings and their respective declarations for all XML and (X)HTML documents. Wouldn’t it be good if all the files received for translation followed these rules 😉
Now with everything corrected my final decrypted file looks like this:

.
But what about Studio?
I can’t finish this article without mentioning how Studio handles these sorts of problems. The “writer” options on these filetypes has similar options to control the BOM, and the HTML has the specific META declaration which is not used in XHTML or XML. The options speak for themselves, but should be used in conjunction with the requirements of your client to help ensure that the final target files are always going to be created in such a way that the encoding is appropriate for their intended use:
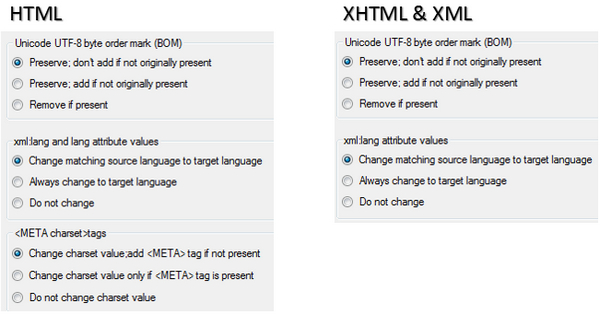
I think these are settings that are often overlooked, especially if the creation of the filetype is left to the translator or project manager. In many ways these sorts of problems fall into the category I wrote about in the previous article “A little Learning is a dang’rous Thing;” but maybe the explanation I’ve tried to provide here will at least provide a little awareness that they exist and why they exist too… and maybe even help to resolve a problem the next time you come across it.
.
At the start of this article I set out to try and explain the problems of encoding in a simple way, but as I scroll back through what I’ve written I’m not at all sure I’ve done this. Perhaps this is just one of those subjects that is complex and handling files with the potential for encoding adventures is something that requires knowledgeable people somewhere in the mix to ensure things are done correctly and the problem doesn’t land at the feet of the translator or project manager. Perhaps I’d be better off writing a novel! I read in the introduction to Mats Linders excellent manual on Studio that he always wanted to write a novel… I hope he does a better job than I would!
Great article as usual Paul, but the Arabic displayed is not correct, I am afraid, direction wise. The whole text is not properly read on screen, as that might need an RTL marker to fix it. Let me know if you need help with that.
All the best.
Sam Ragab
Oh dear… just another complication and one you could only notice if you spoke Arabic! I’ll send you the html!!
ok – I believe it’s correct now. The problem was an interesting one as the Arabic was still rendered correctly in a browser, it was just displayed in a strange way in my Editor. If I changed the Editor view to show the Arabic RTL then the entire file was handled that way and looked even stranger, although still correctly rendered in a browser. I guess this is a good practical demonstration of the way different applications work when handling different character sets in one code page!
Thanks for your input and your transcreation!
Hi Paul!
Nice article!
Regarding: “The lack of a BOM in the file only causes potential problems if the correct character encoding is not declared in the file in the first place. ”
We often get txt files encoded in UTF-8 without BOM – and this causes problems with the Studio regex-based txt file type where special characters (like German umlauts) get corrupted. The only solution is to convert such txt files into UTF-8 with BOM and change the encoding after the translation once again.
However, we would expect Studio to be able to deal with such BOM-less txt files straight away.
Any ideas how to avoid the need for pre-/post-processing such txt files?
Thanks!
Christine
Hi Christine, interesting question and I’m not sure whether there is a bug here or not so I will report back later after discusing internally. What I think happens is that first Studio will read the file and look for either a declaration of the encoding or a BOM. It will do this because the only other way to “pick” the correct encoding is to scan the file and look at the text and this could take time… so I’m guessing for now that Studio won’t do this as it’s just a simple editor and it needs to be told. The other problem is that if the source is English then eithout a BOM or a declaration then there is nothing in the file that tells Studio it should be anything more than ASCII so how would it know to be UTF-8. I guess the target language could be the trigger, and this is partly why I’m wondering bug (or maybe lack of feature?).
So now you have two options. In the filetype settings you can tell Studio to add the BOM, but it’s adding it to an ASCII file and this encoding is innappropriate for your character set, so adding the BOM to this won’t help… and it clearly doesn’t.
The next option is to change the encoding in the Active Document Settings to UTF-8 and when you do this the file saves correctly and the characters are all legible. But of course you have to do this for each file as there is no project setting for this unfortunately… only individual files.
So for now I think I would ensure that all your files had a BOM before you added them to Studio because then they will be handled as UTF-8 and the targets will be perfect. The File Encoding Converter I mentioned is perfect for this and if you need to remove the BOM afterwards because the host application is built to not expect one then the same tool makes short work of that too.
But I will discuss with development. Thanks for the interesting question.
A BOM in UTF-8 files is not required and indeed often not included in files we receive. Would be great if Studio could handle this properly.
Did report this in 2014 already but reply was this: “The problem is that the only way to find out if a file is UTF-8 or not, is to scan the whole document until you get to the first UTF character. In large files/projects this will pose a real issue because this scan will take some time. In its current state, Studio’s detection algorithm does not perform this scan, that is why we recommend using a BOM.”
For more information about the BOM in UTF-8 see here: https://www.w3.org/International/questions/qa-byte-order-mark
Thanks Thomas, indeed. And in 2017 there is no change. There is work planned now that I am aware of to allow you to specify the encoding to be used for the files when creating a project, so similar to the single document approach where this is possible now. But I agree, this is an area where Studio is currently too strict and inflexible.
Great news Paul. Thanks for the update.