 If there’s one thing I firmly believe it’s that I think all translators should learn a little bit of regex, or regular expressions. In fact it probably wouldn’t hurt anyone to know how to use them a little bit simply because they are so useful for manipulating text, especially when it comes to working in and out of spreadsheets. When I started to think about this article today I was thinking about how to slice up text so that it’s better segmented for translation; and I was thinking about what data to use. I settled on lists of data as this sort of question comes up quite often in the community and to create some sample files I used this wikipedia page. It’s a good list, so I copied it as plain text straight into Excel which got me a column of fruit formatted exactly as I would like to see it if I was translating it, one fruit per segment. But as I wanted to replcate the sort of lists we see translators getting from their customers I copied the list into a text editor and used regex to replace the hard returns (
If there’s one thing I firmly believe it’s that I think all translators should learn a little bit of regex, or regular expressions. In fact it probably wouldn’t hurt anyone to know how to use them a little bit simply because they are so useful for manipulating text, especially when it comes to working in and out of spreadsheets. When I started to think about this article today I was thinking about how to slice up text so that it’s better segmented for translation; and I was thinking about what data to use. I settled on lists of data as this sort of question comes up quite often in the community and to create some sample files I used this wikipedia page. It’s a good list, so I copied it as plain text straight into Excel which got me a column of fruit formatted exactly as I would like to see it if I was translating it, one fruit per segment. But as I wanted to replcate the sort of lists we see translators getting from their customers I copied the list into a text editor and used regex to replace the hard returns (
) with a comma and a space, then broke the file up alphabetically… took me around a minute to do. I’m pretty sure that kind of simple manipulation would be useful for many people in all walks of life. But I digress….
I now have three files created from my list and I’ll use these to try and explain the concepts of segmenting text in SDL Trados Studio through the use of segmentation rules in your translation memory.
- a comma plus space separated list
- a comma only separated list
- a tab delimited list
In Studio without creating custom segmentation rules I’m going to see something like these:
comma plus space

comma only

tab delimited

I think all of these are the most common sort of problems we see users dealing with and hopefully they will allow me to explain the concepts you can use for segmenting on anything. So, first of all let’s see where you create these rules. Trados Studio segments files based on the structure of the file first and then using segmentation rules in your translation memory. So if you have a word file and you end a sentence wth a full stop followed by a space, or you press the enter key which inserts a hard return (or a paragraph break), you will get a separate sentence (or segment) in Studio when you open them up. Like this:

If you are working with markup files, like XML or HTML, then the segmentation is controlled by the parser rules for the separate elements. For example, opening an XML file with the parser rules set incorrectly could lead to something like this where the file is segmented based on full stops at the end of each sentence, but also where the inline elements (<nice>, <info> and <not>) have been incorrectly set as structural elements (see this article for more information on this rather large topic):

But if the structure of the file is all set up correctly then the only thing you might have to address is the segmentation of text that is placed into Studio as a single segment when you’d prefer to see it broken down further, which brings me back to my sliced fruit.
Segmentation Rules
Segmentation rules are held on the translation memory or in language resource templates. The options are exactly the same in both places. Language resource templates are very similar to project templates in that they provide you with a way to create a new translation memory based on a configuration you use a lot. So things like your Variable List, Abbreviation List, Ordinal Follower List and Segmentation Rules can all be set up in a language resource template and used as the basis of a new transaltion memory whenever you create one:

You create a new language resource template in the Translation Memories view by selecting New -> New Language Resource Template as shown above. You can also create a new translation memory based on a previous one, but using these templates is handy because they take up little space and can easily be shared with others. I think it would be handy to have an Apply Translation Memory Template application that worked in a similar way to Apply Project Template… and we might look at the feasibility of this in the near future.
To edit the segmentation rules in a translation memory you open it in the Translation Memory view and then select Settings from the ribbon, or right-click and select Settings from the context menu:

An important point to note is that you must select a translation memory to use the ribbon icon because otherwise it will be greyed out. Once you’ve done this you’ll find the segmntation rules under the Language Resources node. If you create a language resource template you’ll find the only settings in there are these listed under the Language Resources node shown below, so everything I’m about to explain is the same for both.

You then select Segmentation Rules and click on Edit. There are two options in the next window:
- Paragraph based segmentation
- Sentence based segmentation
The first option, paragraph based, does not support customised segmentation rules. It is just a way to segment your files based on paragraph as opposed to sentence and a paragraph is determined by the filetype structure I explained earlier. You can read a little more about paragraph segmentation in this article as it’s an useful option under the right circumstances. For our sliced fruit we are going to be working with the Sentence based segmentation where you’ll find three default rules:
- Full stop rule
- Other terminating punctuation (question mark, explanation mark)
- Colon
Generally I’d leave these alone unless you have a very specific reason for wanting to change them and you understand why this will be necessary. There are options when you edit them to add exceptions in addition to, or instead of, changing the rules and if you do play around in this area I’d recommend trying to use the exceptions first as this is usually a lot safer. But we’re going to add new rules.
Adding Segmentation Rule
New segmentation rules work by defining three pieces of information:
- what characters are there before you break to start a new sentence
- what character do you actually want to break on
- what characters appear after the break
There are two views where you can apply these rules, a Basic View:

And an Advanced View:

You’ll notice that the Advanced View only has two places for information, whereas the Basic has three. This is because the Advanced View uses regular expressions and the Before break pattern incorporates the first two pieces of information that you enter into the Basic View.
The rules you create are handled sequentially. So if we wanted to segment the first fruit file which is a comma plus space between the fruits we have to do two things:
- break before the comma
- break after the space
The reason we want to do this is so we are able to handle the words on their own and just filter out the comma and space in the editor. Doing this is not always obvious because the basic View doesn’t give us all the options for the things we need, unless they are really basic, and trying to add them in the Basic View and then switching to the Advanced View often leads to expressions that don’t work the way you expected as they can be escaped twice which then looks for the existence of a backslash as opposed to the backslash referring to a particular pattern. So to work around this I always use the information that is correct in the Basic View and then use a capital X for the information that is not there. This allows me to edit the Advanced View more easily as the basic requirements are there. This is best explained by an example:
Before break – I want to identify that there are letters before the last letter which is the break character

Break characters – this will be the last letter before the comma. I can’t enter this with an expression so I use a capital X

After break – I want a comma and a space, so use s for the space and check Regular Expression

When I switch to the Advanced View I see this:

It’s hard to read, so this is what I have:
[wp{P}][X]+
,s
It’s simple to see the capital X now and all I have to do is replace this with the regex for a word character. For this I’ll use a w and my expression looks like this:
[wp{P}][w]+
,s
When I open the file using the translation memory containing these rules Studio will open the file like image below with the text segmenting before the comma.

So all I have to do now is create the second rule to break after the comma and the space. This one is quite interesting because I don’t have anything before the break as the comma is now at the start of the segment, so I delete this entry and leave it blank. I then enter a capital X for the break characters so I can add the comma and the space in the Advanced View and select Text for after the break:

This gives me the following:
[X]+
[wp{P}]
I add a regex for the comma and space to replace the X like this:
[,s]+
[wp{P}]
Then when I open the file in Studio this time I get exactly what I need and I can filter out the commas to see something like this:
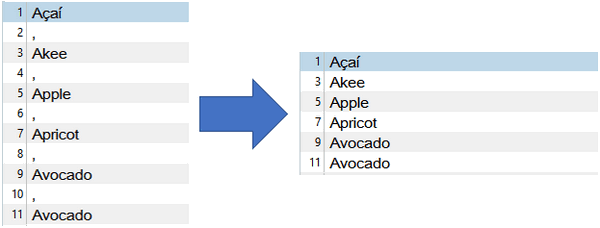
Now working with the file for translation is a doddle and I’ll ensure only the words are entered into my translation memory, and it’s easier to add them to a termbase if I like and ensure term recognition as the commas won’t be in the way.
Finally, as this article got much longer than I originally intended (hopefully because I included things that are useful for you and not just because I thought it was a good idea!) I have created a video showing how to do this for all three fruit files in succession.
Duration: 15 min 16 seconds
Thank you, Paul!
Would this explain why sometimes we don’t get matches? You know the terms have to show up but for some reason they don’t? I don’t control the setup because our jobs go through WorldServer, but it sounds like they are set up for paragraphs and not sentence match.
Many thanks in advance,
Mónica
Sent from my iPhone
Hi Monica, segmentation differences can always be a reason for not getting TM matches, but not terms as these come from your termbase. Might be worth you asking your question in the SDL Community where you can elaborate a little more.
I really appreciate this post. One slight modification for the lists I deal with, which are comma-seperated but one entry (keyword) may consist of several words.
Your rule will split “Hello World, Goodnight Moon, Neptune” into:
Hello
World
,
Goodnight
Moon
,
Neptune
So for the second rule instead of [,s]+ I simply use ,s (one could use ,s* to cover the possibility of several or no spaces). This way I get
Hello World
,
Goodnight Moon
,
Neptune
Daniel
Good adaptation… thanks Daniel.
In the meantime I had to realize how many ways there are to enter keywords:
Hello World , Goodnight Moon,Neptune, Plan B, Goodbye,
All the regex above don’t cope so well with that:
For the first comma rule:
[wp{P}] requires at least two characters before the comma, so “Plan B” is not a match, which is undesirable.
The regex for after the break, .s, requires the comma to be followed by a space, which is the case in the best of all worlds, but unfortunately not in our CMS.
To help this, I use w[ws]* as “Before break” regex and .s* as “After break” regex. This match will include all the spaces somebody might add between the word and the comma, but to me this seems the lesser evil.
The second comma rule needed some way to deal with the trailing comma at the very end of the string, so added the option of the sting ending ($).
So with
rule 1, before break w[ws]* and after break .s* and
rule 2 before break .s* and after break [wp{P}]|$
I fare pretty well.
Daniel
Thanks for sharing this Daniel. Hopefully the principle is helpful and then it’s just a matter of creating the rules to suit your content.
Hi
I would need help with the following issue. The segmentation rule “Full stop rule” is not working for me. I am importing a file in a project as “bilingual Excel”. It converts each Excel cell into one segment, regardless of content.
Hi Karl, I’m afraid you cannot solve this if you are using the Bilingual Excel filetype. The reason for this is that the bilingual filetype needs to keep the source and target aligned, irrespective of weather the source has a different number of sentences in it than the target. So the segments are always aligned by cell. The only way would be to handle this as a monlingual file type using the Excel filetype… not bilingual.