 Ever since the release of Studio 2009 we have had the concept of Language Resource Templates, and ever since the release of Studio 2009 I’d risk a bet that most users don’t know what they’re for or how to use them. To be fair this is hardly a surprise since their use is actually quite limited out of the box and access to the goodies inside is pretty hard to get at. It’s been something I used to see users complain about a long time ago but for some years now I rarely see them mentioned anymore. This article, I hope, might change that.
Ever since the release of Studio 2009 we have had the concept of Language Resource Templates, and ever since the release of Studio 2009 I’d risk a bet that most users don’t know what they’re for or how to use them. To be fair this is hardly a surprise since their use is actually quite limited out of the box and access to the goodies inside is pretty hard to get at. It’s been something I used to see users complain about a long time ago but for some years now I rarely see them mentioned anymore. This article, I hope, might change that.
But before anything else I should explain what a Language Resource Template is. If you open a Translation Memory in your Translation Memory Management View, and then go to your settings you’ll see something like this:
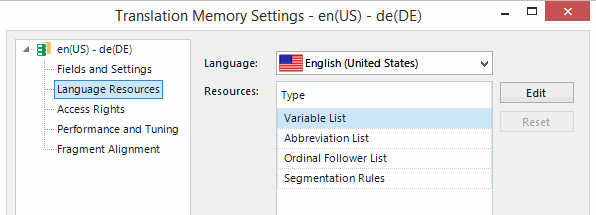
Contents
Variable List
In practice, “variables” in Studio are words or phrases that don’t change at all when you translate them. So it’s useful to be able to ensure they are handled automatically in Studio by defining lists containing these “variables”. I’ve covered these in the past… some 6 or 7 years ago!
Abbreviation List
By default Studio will segment sentences at the end of a sentence. But if you use “abbreviations” in the middle of your sentences like acc. (according to), Cert. (certificate) or Pharmacol. (pharmacology, pharmacological) for example then you don’t want the sentences to break at these points. For some languages there are default sets of “abbreviations“, but you can customise the list to suit your needs.
Ordinal Follower List
In some languages ordinal numbers can be followed with a fullstop, and when this happens you don’t want the sentence to break at this point. In German the date 25th December would be written as 25. Dezember. In order to prevent the sentence from segmenting after the 25. Studio allows you to enter Dezember. Again there are defaults for some languages, but you can add anything you like to the ordinal follower list to control segmentation in some way. For example in my sentence before last you could add the word Studio to the list if you wanted to prevent the sentence from segmenting between 25. and Studio.
Segmentation Rules
There are default rules for every language that define how sentences are segmented. They normally cover a “Full stop rule” and rules for “Other terminating punctuation”. I’m pretty sure they are also exactly the same defaults used for every language (I only checked a few) so you might want to change these to suit. Certainly there are many reasons for adapting these rules and I have addressed these on and off over the years:
All of these things are what you will find in a Language Resource Template and you can create a template without the Translation Memory from the same menu you might use to create a Translation Memory when you are working in the Translation Memories view:
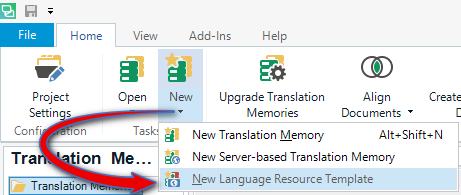
It looks like this:
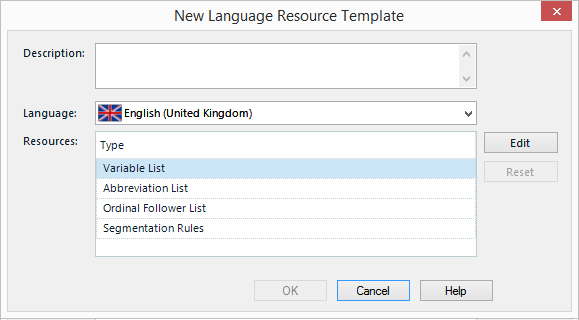
So that’s all interesting, and they are very useful. But the problem with them is that they are applied on the Translation Memory. They are not a separate resource that you could reuse on a different Translation Memory, unless you were creating a new one. So if you had 20 Translation Memories and they all used the same Language Resources then making a change to just one of these resources would mean you have to make this change twenty times. Painful, but reluctantly doable once. But if you have more Translation Memories, and if you regularly update them then this probably becomes unworkable for most users pretty quickly. I aso didn’t mention that these rules control the source and the target segmentation, so if you do a lot of alignment then you can double the effort described; and if you handle more than one language pair then you can multiply all of that effort by each language pair you are responsible for maintaining!
Phew… is it any wonder many users are not familiar with Language Resource Templates?
applyTMTemplate
You may be familiar with the extremely useful Apply Studio Project Template application developed in 2015 which allows you to quickly apply the settings in a Project Template to any Studio project you like. Well, we had an idea to take the same principle and make it possible to apply the settings in a Language Resource Template to any number of Translation Memories you like. This way you can maintain at least one template and only have to change this one to be able to apply the changes to hundreds of others. Pretty cool! You can find the applyTMTemplate application on the SDL AppStore here.
After installing the plugin you’ll find it in the Add-Ins menu in all the Views in Studio, like this:
And if you’re a keyboard jockey then you can also set a custom shortcut for this feature in your File -> Options -> Keyboard Shortcuts… maybe useful if you do a lot of updating TMs:
To demonstrate how this app works I created 12 Translation memories out of six different language pairs by also creating TMs in the opposite direction. I then created one single Language Resource Template and edited all four of the resources for each of the four languages. All I did then was select the Language Resource Template, tick all the resources I wished to be applied (these are actually checked by default), drag and dropped all 12 Translation Memories into the window and clicked on Apply. Almost instantly the resources I added into this single template were applied to all of the TMs:
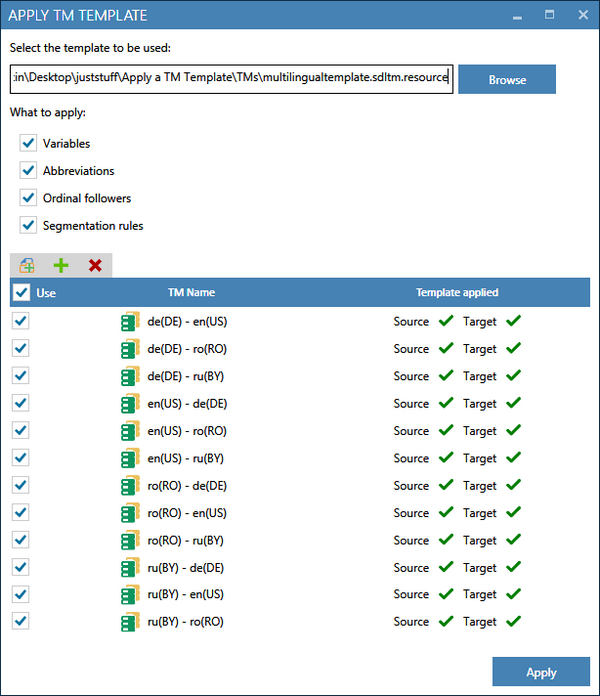
You can see a visual confirmation that the operation was successful as all of the source and target languages have a tick against them. If a language fails, and I did find one in testing (which will probably be resolved in due course) then the TM that failed will be displayed something like this:

Here the resources for Swahili (Congo) failed to update, but the rest did. I’m not sure where the error comes from at the moment but it was only when I decided to try a slightly exotic language for fun that I discovered the problem. I have no doubt it will be identified and resolved in due course… but for now it serves as a good example of what will happen if a language fails to update. Now that I know this I could go in and manually update this one, but that’s a small price to pay compared to all the work I’d have to do for all of the languages before this application was made available!
Some friendly words of warning
As with all Translation Memory operations, always back them up before you carry out any kind of operation on them and thoroughly test how they work and can be exported after these Language Resource Operations. Your Translation Memories are valuable assets!
And unlike Translation Memories which have a pop-up to show you where they are when you hover over them in the Translation Memory view, like this:

Language Resource Templates don’t do that. So don’t forget where you put them or you’ll be searching your computer for *.sdltm.resource files to find out where they are. I only mention this because I had the very problem twice! I can only think that the lack of awareness around Language Resource Templates is why nobody ever noticed! Perhaps this will change now we have this great tool that brings the concept of templates for Translation Memories a new lease of life!
Hi Paul
as you mention alignments (“…so if you do a lot of alignment…”), the Aligner seems to use the segmentation rules of the associated TM to align the source and target texts. Does it also use the TM content to align segments? Or anything else from the TM?
Daniel
Hi Daniel, if by TM content you mean the abbreviation lists, ordinal followers and segmentation rules then yes. All of these things affect segmentation.
Hi Paul, does the Aligner also use TUs? So if I have a TM that contains:
Hello World -> Hallo Welt
will the Aligner use this to match these or similar strings in the alignment process?
In other words, will a TM with many TUs similar to the content that is to be aligned help the alignment process?
Daniel
Hi Daniel, no it won’t. The aligner is a tool for aligning one document with another based on segmentation. I believe it will use document structure to help the alignment, but only document structure in the documents you are aligning. It pays no attention to the content of the TM you have attached to the alignment process at all.
Hi Paul! As a LSP we have hundreds of TMs and often a TM is udpdated with the newest settings as abbreviation and segmentation rules while working on a project in that specific language. So the Resource Template is useful, when you know at the beginning everything you need. But reality is, that it evolves, so one TM is always the one which is on the top of actuality. It would be great, if one could export a template out of such a TM. Or use such a TM as a template to apply on other TMs. I know we can use it to create a new one.
PS: Is there any news on the the abreviation list, to being able to import as a whole, like it was in the TagEditor? That would be great 😀
Exactly why this tool is so good. Don’t update one TM. Update the Language Resource Template instead and then apply to all your TMS in one go.
I see what you mean. By instinct you go to project settings and update the TM. Should change that behaviour. But know, as we have the TMs full of settings, ist there a chance to transfer them from a TM to a Template?
Hi Burim, we are working on this sort of capability now… and more. Will let you know when it’s done.
Hi Burim, we have implemented this feature you mentioned and more. You can find the updated plugin here.
Hi Paul, great! Have to wait for Studio 2019 though.
Hello Paul, Thank you for your Newsletter, which is always a gold mine. I was wondering⦠Is there already any similar tool allowing to extract Terminology from an existing TM before I start translating? The result I get from the tool âSDLTmFindVarsâ (thanks for this!) goes in this direction, but it is limited to those segments with identical words in both languages. Another question: I read your answer referring to TermInjector (thanks again!). Well, I am not able to create the regex I need (yes, I read everything you wrote about it). Could you please help me creating those 2 ones? Case 1: how could I create a regex for the text between brackets to be treated as a variable in the following segment? And, could it also work if the text before the brackets changed? Example : Aufgagen Fallstudie «Company Name» -> Exercice de lâétude de cas «Company Name» Case 2 : I always have a problem with Swiss numbers: they are written with an reversed apostrophe in German, but not in French. For some reasons, Studio does not handle them automatically (I guess it is because it is not simply German and French, but a language variant, i.e. DE-CH to FR-CH). Example: 50â000 -> 50 000. The space must be unbreakable, i.e. in Word alt+0160, which does not exist in txt-Editor. Bonus question: if the number is preceded by âCHFâ, the decimal sign has to be a dot, but only in this case⦠Any possibility to do this? I guess my questions are misplaced in this e-mail, but I wouldnât know where to ask them⦠Thanks again for your great help on your Website (what does âmultifariousâ actually mean?). Best Regards / Mit freundlichen GrüÃen / С наилÑÑÑими пожеланиÑми / Meilleures salutations
Caroline Charlier
http://www.luxtranslations.de
Wow… a lot of questions! Might be better to ask these as separate questions in the SDL Community.
A few quick answer where it makes sense…
You could try the projectTermExtract plugin.
For the regex questions use the community it’ll be easier and the chars won’t be corrupted as they have neen in wordpress. There is actually a regex forum in there too.
The projectTermExtract plugin works great after the fine tuning that was made. It would need just some little more things to be thought about to make it even better, like e.g. click and select the words on the image to add them to the black list. Is there any work going on on planned with the plugin?
We have all kinds of enhancements planned for this plugin… just need to find time to do them.
Hi Paul,
Sounds like a brilliant app! I have a client running SDL TMS, this would be exactly what they need to pin down variables and abbreviations.
However, there are a few things that are unclear to me.
1. The app only works as a plugin to Studio 2019 or later? What if the client doesn’t own a Studio license? There’s no way to make this app interact with SDL TMS on its own?
2. Let’s say that the client buys a Studio license. Can the app then apply settings straight on the TMs in TMS (i assume there is some depository with a server path).
3. The way their TMS is configured, when the translation vendor downloads a studio package, TMS generates a project TM on the fly, based on two or three master TMs that are matched in sequence. Does this project TM then inherit the settings (variables/abbreviations lists etc) from the master TMs? Or are they lost in the process and the project TM becomes plain vanilla?
4. Assuming that the project TM doesn’t inherit settings within TMS, me as a project manager would then instead run applyTM Template. Typically, i would then have downloaded 15-20 sdlppx files into various languages. Does the app work on packages, or would I have to unzip them, point to the TM and zip them back to sdlppx?
Sorry for all questions. Just let me know if I should move these to the community?
Hi Jan, the app is only for desktop TMs. It’s not needed for server TMs since this capability is already there to some extent. I can’t comment on SDL TMS… so I’m only talking about Language Cloud (Trados Live) and GroupShare. I suggest you ask these questions in the SDL TMS community.
Me again, sorry!
I just realized in the workflow described above: the files are segmented in TMS, which means that the project TM and subsequent package is irrelevant from a segmentation viewpoint.
You can skip questions 3 and 4.
The key to get it right is really for the client to apply TM settings on the master TMs in TMS.
Amendment to question 1: would the app work with a trial version of Studio 2019, or would there be limitations on what the trial license can do?
I was wondering, if you use several translation memories for 1 project (and update all of them or 2 out of 3) and those memories have each different language resources (different segmentation rules or Dates/Times), which language resources will be used, the ones from the first TM in the list? Thanks
I have tried this setting and thought it would be very useful, as I would like to update the settings of many TMs using a template. I found, however, that the configured exception to the full stop segementation rule, which was the main setting I wanted to change in the TMs, was not applied. The other settings were changed, so I know that the feature works in general. Might be a bug there? I guess I will have to open all of my TMs and change this setting manually after all…