 The Old Farts Language Code Club! This is a new club, inspired by a comment in the SDL Community from a prospective member. I’m not sure yet of the age at which you can qualify for membership, but in addition to the age requirements, which may have stringent rules to prevent any young whippersnappers from joining, it’s essential that prospective members have a good grasp of the language codes used in Trados Studio. I’m also not sure of the demand, so I may open a waiting list that could include anyone who already makes good use of the language codes in Trados Studio but isn’t an old fart yet!
The Old Farts Language Code Club! This is a new club, inspired by a comment in the SDL Community from a prospective member. I’m not sure yet of the age at which you can qualify for membership, but in addition to the age requirements, which may have stringent rules to prevent any young whippersnappers from joining, it’s essential that prospective members have a good grasp of the language codes used in Trados Studio. I’m also not sure of the demand, so I may open a waiting list that could include anyone who already makes good use of the language codes in Trados Studio but isn’t an old fart yet!
Contents
Language Codes
In case you’re still wondering where I’m going with this let me define what I mean by language codes. Trados Studio identifies the languages of the source and target resources used in your projects (SDLPROJ files), bilingual files (SDLXLIFF files), Translation Memories (SDLTM files), and many other types of file using a code. The code it uses is based on the windows Language Code Identifier (LCID) which you can read more about here in the Microsoft website. In fact you can even download a handy PDF from that site which gives you these sorts of details, and a lot of other useful stuff:
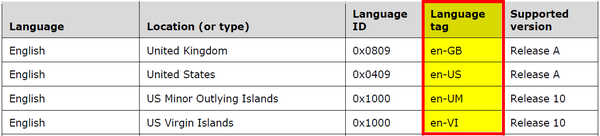
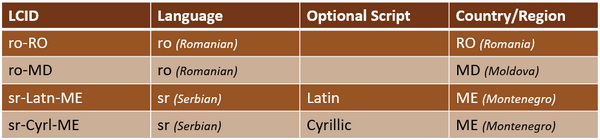
I have highlighted the column you may have seen people referring to when they say “language codes”. The codes that Trados Studio is looking for are are what we call “fully qualified” language codes because they consist of the language code and a country or region code. In fact some languages even have another optional identifier in the middle relating to the script used to write the language. For example:
Cultures
I want to mention something else while we’re on this subject and that’s “cultures”. This is also very important to understand in Trados Studio because this is joined at the hip to the language codes. I’m pretty sure you’ll understand this completely if I show you this:

In segment #1 the short date format is recognised by Studio and you can see the solid blue line underneath it. The result is the date is correctly localized into the target language automagically. In segment #2 the short date is not recognised as a date and instead is seen as three separate numbers so the magic to make the localization easier won’t happen.
The settings for this recognition are taken from the language culture information in windows which you can find in your Regional settings. This is responsible for helping ensure the correct automatic localization format for things like dates, time, currency, numbers etc. At least this is the theory… sometimes this behaves like the other side of an old fart and the results can be quite unpredictable. I’ve covered this sort of thing before and how to address it in various forms so I’ll just refer you to a few of these resources if you are interested:
- Spaces and Units…
- FIT XXth World Congress – Berlin
- Search and replace with Regex in Studio – Regular Expressions Part 3
The main reason I mentioned cultures is because the fully qualified language code will define what windows resources Studio uses to handle these sort of autolocalization tasks and this is partially why Trados Studio requires fully qualified language codes.
Why would you want join the OFLCC?
Learn how to use language codes when creating projects
Whilst I intend to discuss a few reasons why it’s useful to have the language code skills of an old fart, it’s their use, particularly when creating multilingual projects with the new Trados Studio 2019 project wizard, that sparked the reason for this whole article. For example, let’s assume you are creating a multilingual project for the first time with just ten target languages; Chinese (Simplified Singapore) [zh-SG], Chinese (Taiwan) [zh-TW], French (France) [fr-FR], Italian (Italy) [it-IT], German (Austrian) [de-AT], German (Germany) [de-DE], Japanese [ja-JP], Spanish (Spain) [es-ES], Spanish (Chile) [es-CL] and Spanish (Latin America) [es-419]. If I use the Trados Studio 2017 project wizard for this it takes me well over a minute with a combination of the mouse and the keyboard, getting past the recently added languages when I type, scrolling through the list (which keeps scrolling if I go too fast…) etc.
In Trados Studio 2019 I just need to type the language codes:
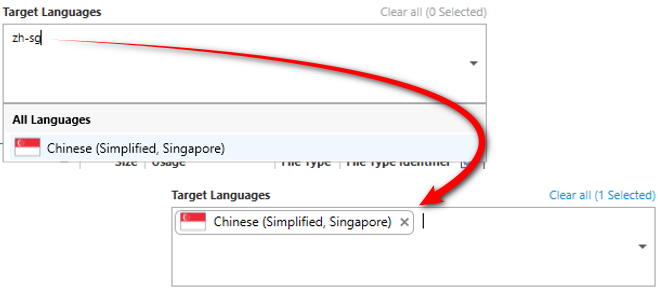
So doing the same thing using the language codes in the Trados Studio 2019 project wizard it takes me less than 30 seconds. Even with my slow typing speeds this is significantly faster and if you do this a lot all day long, often with many more languages in a project than this, it all adds up. The process is simple you type the code into the target language field and press the Enter/Return key as shown above.
 Most translators and project managers I know dislike using the mouse so this method is not only faster, it’s also pleasing to use.
Most translators and project managers I know dislike using the mouse so this method is not only faster, it’s also pleasing to use.
The other benefit to this of course is that as Trados Studio is going to create target language folders using these language codes, now you’ll always know exactly which ones are which when browsing for your target files, or trying to find the right SDLXLIFF file to send to a translator that can’t use your packages or connect to GroupShare.
Organise your translation memories in windows explorer
When you look at your translation memories in a project you see something like this:
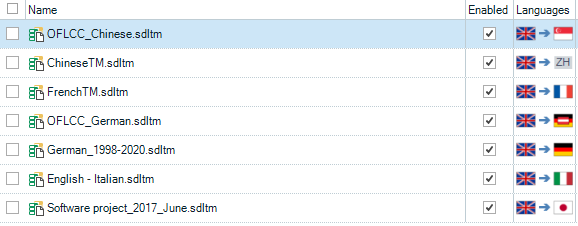
The flags on the righthand side in the Trados Studio Project Settings are a giveaway telling you which TM is which. This is important since the names may be even less useful than the ones I made up here. But how do you organise your TMs in the first place so when you select them they are easily distinguishable in File Explorer before you have created the project? I’m pretty sure the majority of project managers and translators will have their own system for doing this… but on the basis of looking at the computers of many users over the years I can tell you many do not. So here’s an old farts tip!
sourcelanguagecode - targetlanguagecode_relevantname.sdltm

If you use your language codes for the source and target languages of your TMs then you always know exactly which language pair they are before you have to do something with them. It also makes sorting them really simple as they’ll be grouped by source language and then target language, and then whatever other naming system you use (domain, customer, project code etc.). Seems a simple thing I know (and may be the result of own analness), but perhaps this will give someone an idea centered around the use of language codes if they’re collecting TMs and wondering about a logical system for naming these valuable resources.
Learn about unrecognised language abbreviations in files
If you receive files that require a language code, such as XLIFF files, and the language codes are not fully qualified you’ll see things like this:

I’m pretty sure this will be a familiar sight to many users but it’s not one you should worry about. You’ll still be able to translate the files and send it back to your client. So harmless, but a little annoying because this message pops up like an old fart every time you open the file and you can’t ignore it.
I also saw an XLIFF last week from a Trados Studio user that they could not open at all. The reason why not… the language code was “x-unknown”.
srcLang="x-unknown"
In this case however Studio really behaves like the worst kind of old fart and throws an error rather than give you the opportunity to change the code for something appropriate or even simply report it as it does in the previous example. So you can’t work at all until you change it in the source:

The error is also a little msleading as XLIFF Version 2.0 is supported and the only problem with this file is the language code. I learned in the SDL Community thread where this was discussed that it is acceptable to do this under the XLIFF standard so it would be a lot better if Trados Studio handled the failure gracefully… perhaps an improvement for the future?
Similarly, if you are importing TMX files into an SDLTM, or upgrading a TMX, Trados Studio needs to be able to understand the language codes. For example, you might have something like these in the file:
srclang="en" xml:lang="en"
This would be fine and Trados Studio would probably default to en-US. But if you used the same “x-unknown” then the upgrade process just won’t load the file… no information about why, but no error. If however, you try to import the TMX into an existing SDLTM you’ll see this:
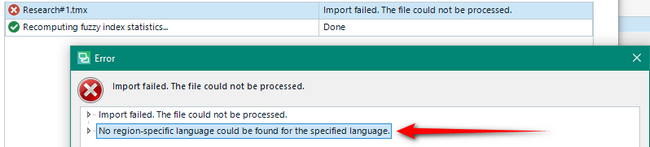
Fairly clear what the problem is here and now you’re aware of language codes you’ll know how to fix it. Interestingly I tried the same exercise to upgrade a TMX that had these unknown codes for source and target languages:
xml:lang="xx-ZZ"
Trados Studio created an SDLTM for me retaining all the TUs inside, assigning flags I’ve never seen before and allowing me to use it in a project via AnyTM:
![]()
I have no idea why this would be useful or why it occurs but this old fart is certainly full of surprises and like all old farts now needs an explanation to sleep well at night! I’ll update this post if I ever find out!
To conclude
I only mentioned a few places where knowledge of the language codes can be helpful. Most files and resources in Studio contain information about the languages being used and familiarity with these codes is often helpful when taking shortcuts under the hood, preparing files for translation, dealing with Machine Translation engines that use different types of language codes etc. etc. I would imagine that if you haven’t thought about these codes before that it wouldn’t take long to learn the ones you use on a regular basis either.
Hopefully we’ll be welcoming you to the OFLCC very soon, old fart or not!
I concur since I always refer myself to an old fart translator.
I concur and would like to become a member.
One of the old farts.
No newbies, the real ones only, sweat and tears, you know that actually used paper dictionaries once.
an old fart from France.
Ivan
I think Klingon should be a required language.
You’re in 🙂
I like the idea of Klingon too!!
Hehe, Klingon… actually “i-klingon” is an existing, yet grandfathered in the favor of 3-letter code “tlh”, language tag… 😉
Regarding the language tags – which should be the preferred term over “language codes”, BTW – I can only add that getting familiar with them opens the door to the magical world of Studio batch automation, e.g. via STraSAK (https://github.com/EvzenP/STraSAK).
Regarding the funny “XX” flags – I don’t see anything surprising here actually… it’s a result of a “last resort fallback” in a routine in Studio which assigns the flags to the language codes – if the routine does not find a real flag picture in Studio resources which would correspond to the “xx-ZZ” language tag, a “fake flag” is created using the capitalized letters from the primary subtag (i.e. the first part of the language code before the first hyphen).
Studio uses such “fake flags” for many ‘normal’ languages, e.g. the variants of Chinese… actually, even the by far most used variants of Chinese – “Traditional, Taiwan” and “Simplified, PRC” – do not show a real flag by today, at least in Studio 2017, and show “ZH” in place of the flag.
Thanks Evzen… good addition and thanks for the link to your automation kit. It is a very nice piece of work.
I imagine you’re correct about the language codes as this certainly seems logical. I’m still waiting for a developer to confirm this but your analysis seems very likely.
Hi Evzen,
At this point just a big Thank You for STraSAK, I use it all the time and it does wonders for my productivity. I use it in conjunction with AHK, which makes it even better, e.g. simple drag&drop of file and TM – voilà, project created 🙂
This is how Studio should really work, hopefully SDL will learn from this and implement far more automation functionality in Studio 2021!
Best,
Oli
Agree with big thanks to Evzen… it’s a great example of what can be achieved with command line working and I’m really happy he shared his efforts. But don’t forget this is only possible because SDL support it and still continue to develop the APIs.
Sure, the API is great and I definitely appreciate the effort put into it. Not pointing fingers, but other CAT tools such as Transit don’t have an API at all – which is kind of lame. I have actually started learning C# in order to communicate directly with the API, and although this isn’t easy, I was already able to put it to good use.
I understand that SDL’s main target group is (freelance) translators, and for them automation is probably not that interesting. But for transtech/project managers who have to create hundreds of often multilingual projects day in, day out, this gets a “tad bit tedious” 😉
Anyway, I am excited to see what RWS brings to the table, now that they have taken over. Interesting times indeed!
Hey!
I read your comments about Klingon and really got inspired! 🙂
I’ve been wondering for a time if it is possible to “forge” somehow Klingon as target language in Studio so I can use the Bing paid MT subscription there (via MT Enhanced).