 After attending the xl8cluj conference in Romania a few weeks ago, which was an excellent, and very technical conference for translators, I thought it was about time I wrote an article around the things you can do with the Regular Expression Delimited Text filter since it is so useful for solving all kinds of tasks related to text based files that don’t fit any of the out of the box formats available in the product. Files such as software string files and csv files are common examples of where understanding how to work with this customisable file type can yield many benefits. So this article is food for thought and a few things that might be helpful to you in the future. It’s also pretty long (I’m not kidding!), so maybe grab a cup of coffee before you start to go through it!
After attending the xl8cluj conference in Romania a few weeks ago, which was an excellent, and very technical conference for translators, I thought it was about time I wrote an article around the things you can do with the Regular Expression Delimited Text filter since it is so useful for solving all kinds of tasks related to text based files that don’t fit any of the out of the box formats available in the product. Files such as software string files and csv files are common examples of where understanding how to work with this customisable file type can yield many benefits. So this article is food for thought and a few things that might be helpful to you in the future. It’s also pretty long (I’m not kidding!), so maybe grab a cup of coffee before you start to go through it!
CSV FILES
But Studio can handle a CSV file out of the box! Well that’s true, but only if you have one column containing the source and one containing the target. If you have a monolingual file containing text for translation that just happens to be separated by commas then the out of the box file type isn’t helpful. I actually discussed this at length with a few users in Cluj as there are obviously some good workarounds for this and I imagine this is what most people do already when handling a file like this:
- convert to Excel
- import to Excel
Both of these are good workarounds, but the first one is a very tedious process if you have hundreds or even thousands of these files to contend with, and the second one would fail if the CSV files were formatted differently because you couldn’t easily get the target CSV files back out later.
Now having said this you only have to do a simple search for “batch convert csv to excel” in google and you’ll get loads of free options to make this easy for you. But if I do that I can’t show you some really useful features of the Regular Expression Delimited Text filter which could be useful for other tasks… so instead let’s pretend I didn’t say that!
Step 1: Create the filetype
To begin with I go to File -> Options -> File Types and click on New… then select the Regular Expression Delimited Text.

This opens up the File Type Information pane and I complete these four fields (not all mandatory but they are useful):
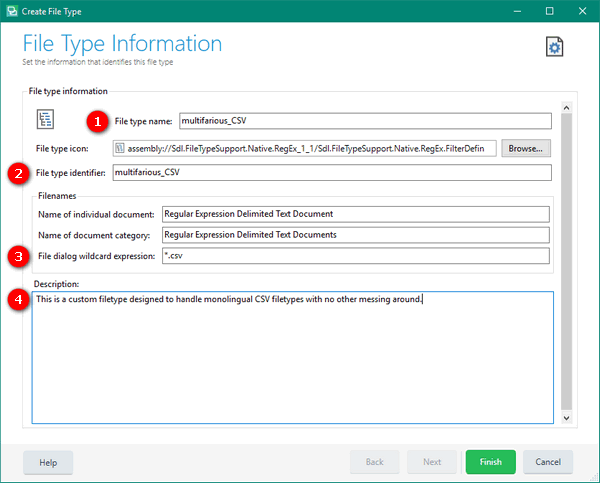
- File type name: this provides a unique name to the file type.
- File type identifier: (not mandatory) this allows me to be sure I have used the correct file type when preparing projects as it shows up in the Files View after preparing my project and also in the orange tab at the top of each open file in Studio when I use TagID mode.
- File dialog wildcard expression: you need to make sure this says *.csv if you want it to be used to open a CSV file.
- Description: (not mandatory) this is just useful, especially if you create a lot of custom file types, especially if you share with others, as you can make a note of what the file type does.
Then you click on Finish and you should have your new file type ready to go… now that was easy!!
Step 2: Previewing your genius
I wanted to add this in because this feature in Studio is a fantastic time saver when you are working on your ingenious creation. You just select one of your CSV files and click on Preview after each change to the settings in your file type:

- this is your new file type that should now be visible in your list.
- this is the Preview feature. Just Browse… for your test file and then click on Preview.
When I do this I can see that I have opened up all the content of my file for translation, but it’s not segmented as I’d like on the comma:

So the next step has to be to create the rules ‘ll need to segment the file.
Step 3: Segmenting the text
Normally, when you need to segment your text you’d think about creating a custom segmentation rule in your TM since this is what drives your segmentation. You could do this of course, but file types also assist in the segmentation of your file and this case I think it’s easier to manage in this way. If nothing else it means you don’t have to use a different TM whenever you’re handling CSV files.
So, how do we go about this? Well, the way I’m going to tackle it is by making the comma a non-translatable tag and set it as external. This is pretty simple and I just do this:
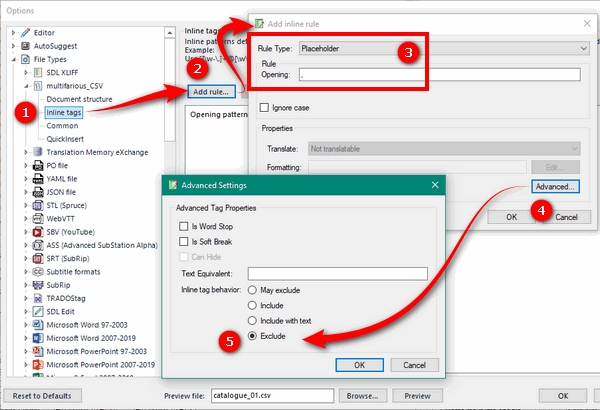
- Open the new file type you created and click on Inline tags.
- Add a new rule.
- Specify that the Rule Type is a Placeholder, and use a comma as the Opening rule.
- Click on Advanced…
- Then set the rule to Exclude
That was pretty simple too… now we can preview the test file again by clicking on Preview (see how fast this test is!):

In general that seems pretty good… until we scroll down a little and now I see that segments 54 to 57 should actually be in one segment, and segments 59 and 60 should also be in one segment. To understand why, and to illustrate the problem we have to solve, we need to look at the source file:
006,William-Adolphe Bouguereau,French,(1825-1905),"A Girl in Peasant Costume, Seated, Arms Folded, Holding a Ball of Wool and Knitting Needles in her Right Hand",1875,"1,305 €"
On inspecting the CSV file we can see that there are some lines, enclosed by double quotes, and this is because the use of the quotes tells a parser that can read CSV files not to separate on commas when they are within these quotes. So simply using a comma as the rule to segment on is not enough for my files. I need to be a little smarter. To do this I need to create a regular expression that will only find commas where I need to segment. So, this is what I did:
| [^”] | Match anything apart from a quote |
| * | Keep matching anything apart from a quote |
| “ | until you get to a quote |
| B | but only where the quote isn’t on a word boundary (commas and end of line are not recognised chars for a word boundary – not in w) |
This gives me this:
[^”]*”B
Now, I want to find a comma that doesn’t fall within this search pattern. So to do this I need to enclose this within what’s referred to as a negative lookahead:
(?![^”]*”B)
A negative lookahead is just an assertion, it doesn’t actually match anything. But if I add my comma because this is what I want to find, then I can now find commas but only when they’re not followed by what’s in the lookahead:
,(?![^”]*”B)
Apologies if that was a little hard to follow… it’s a good example of why it’s important to learn a little about regular expressions. If this is all new to you I’d recommend you start now as there are so many applications in a translation tool for using them and you can get a lot of benefits from this. But I digress… back to our file type. I can now replace the comma I used previously with my new expression like this:

And this time when I preview the file I see something like this:
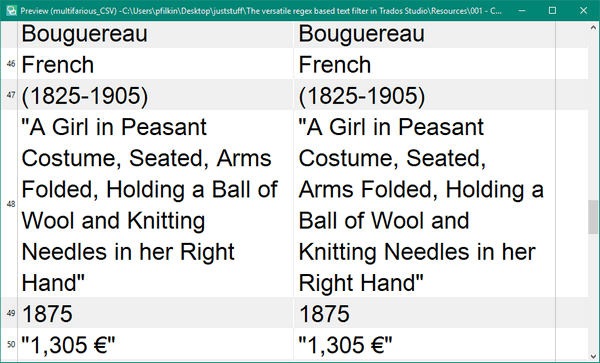
That’s much better… only spoiled by the double quotes that have been included as translatable text. But that’s easily solved by adding one more rule with a single double quote as a non-translatable placeable, and setting this as external so it’s removed from view:

And that’s it… for the sample files I used this does the job nicely and I can handle as many as I like without having to do any conversions at all. If you want to work through this example, here’s a test file you can copy/paste to create a CSV like this one:
SKU,Name,Nationality,Lived,Artwork,Year,Est. Value 001,Leon Bakst,Russian,(1866-1924),Portrait of Virginia Zucchi,1917,"12,250 €" 002,Sir Max Beerbohm,British,(1872-1956),The Encaenia of 1908,1908,"17,100 €" 003,Ivan Yakovlevich Bilibin,Russian,(1876-1942),Design for the Costume of Babarikha (the Matchmaker) in Rimsky-Korsakov's Opera 'Tsar Sultan,1928,"12,000 €" 004,Richard Parkes Bonington,British,(1802-1828),Shipping Off the Kent Coast,1825,"7,500 €" 005,François Bonvin,French,(1817-1887),"A Seated Woman, Sewing by a Table",1848,"10,250 €" 006,William-Adolphe Bouguereau,French,(1825-1905),"A Girl in Peasant Costume, Seated, Arms Folded, Holding a Ball of Wool and Knitting Needles in her Right Hand",1875,"1,305 €" 007,Ford Madox Brown,British,(1821-1893),Study for a Greyhound,1850,"25,950 €" 008,Alexander Pavlovich Bryulov,Russian,(1798-1877),"Portrait of Marie-Amélie, Queen of the French",1860,"8,400 €" 009,Paul Cézanne,French,(1839-1906),"Studies of a Child's Head, a Woman's Head, a Spoon, and a Longcase Clock",1872,"32,350 €" 010,Jean-Baptiste Camille Corot,French,(1796-1875),Civita Castellana: A Woodland Stream in a Rocky Gully,1826,"12,750 €"
Now we can take a look at some software string files that are also not handled out of the box.
SOFTWARE STRING FILES
These are file types I see coming up all the time in the forums in some form or another. Unfortunately they are often the most inconsistent files in terms of the syntax being used, but we can work around this easily enough using our rules. So, what do these file types look like? Most of the time they are key-value pair files, so I’ll use these as an example and I’m pretty sure you’ll be able to adapt the rules to suit any variants to this on your own… but if you can’t you can always ask for help in the SDL Community where you’ll find plenty of help from the many smart users in there:
Apple define their strings files like this:
/* Question in confirmation panel for quitting. */ "Confirm Quit" = "Are you sure you want to quit?"; /* Message when user tries to close unsaved document */ "Close or Save" = "Save changes before closing?";
These have three components to them:
- a comment enclosed with the /* and */ syntax.
- a key enclosed in double quotes preceding the equals sign
- a value enclosed in double quote after the equals sign
The ideal way to handle these files is to use SDL Passolo where the file preparation is a breeze and you can export to SDLXLIFF to translate in Studio afterwards if you prefer. Using the DSI Viewer from the SDL AppStore means you can see the comment and the key for each value being translated as you work… very neat and simple:

But… if you’re a Studio user without access to Passolo, and you’ve been asked to handle a file like this, which we see happening all the time, then here’s a solution using the Regular Expression Delimited Text file type.
Step 1: Create the filetype
This is exactly same as we did before, except this time you probably have to use *.strings as the File dialog wildcard expression.
Step 2: Previewing your genius
We can see here in our preview pane that the entire contents of the file are being extracted and segmented on the basis of Studio default rules:

So if we want to be able to see all of this information then we need to try and do a couple of things:
- extract the comment and lock it so we can still see it, but ignore it during translation
- segment the key-value pair so they are on separate lines
- lock the key so it can be seen but ignored during translation
Step 3: Extract the comment
This pretty straightforward, we just create an Inline tag rule using a Tag pair like this:

I removed some of the steps this time on the basis you would have no problem doing this after following the more detailed steps for the CSV file type above. Hopefully this also helps to see how simple this can be for all kinds of text based filetypes.
I could set this rule as Include under the Advanced… options so this now gets me this when I preview:

You can see that the comments are visible, in their own segment even if there is a period at the end of the comment, and also protected so you won’t translate them.
Important note:
However, in practice I had a small error repeating this for the other rules when I tried to lock the key in the same way I tackled the first rule above. So instead I took a different approach and set all the rules as translatable instead (which will remove the locked status in the image above) and used the formatting feature to colour the text red… I’ll explain why I did this shortly.
Step 4: Segment the key-value pairs
To tackle this I created two new rules, this simple tag pair rule to extract the key string and also colour it red as I eventually did for the comment:

| ^” | Opening: Match a double quote at the start of the line |
| “s | Closing: Match a double quote followed by a space |
That should allow me to extract the key string in the highlighted text below:
/* Question in confirmation panel for quitting. */ "Confirm Quit" = "Are you sure you want to quit?"; /* Message when user tries to close unsaved document */ "Close or Save" = "Save changes before closing?";
Then I created another tag pair rule to extract the value string which is actually the one I want to translate, but didn’t colour the text:

| =s” | Match an equals sign followed by a space and a double quote |
| “;$ | Match a double quote followed by a semi-colon at the end of the line |
That should allow me to extract the key string in the highlighted text below:
/* Question in confirmation panel for quitting. */ "Confirm Quit" = "Are you sure you want to quit?"; /* Message when user tries to close unsaved document */ "Close or Save" = "Save changes before closing?";
This nicely previews like this:

You can see that the text I need to translate is black, and the comment and the key string are in red, but visible to me while translating.
Step 5: Filter out and lock the non-translatable segments
Now, why did I colour them red apart from the obvious reason which is to be able to distinguish them from the translatable text? Well, if I open one of these apple strings files in the Studio Editor I can now use the Community Advanced Display Filter to filter on the red coloured text, like this:

So now I’m only displaying the segments I don’t want to translate. Next I just copy source to target, change the status to translated and lock them. I can now clear the filter to see this:
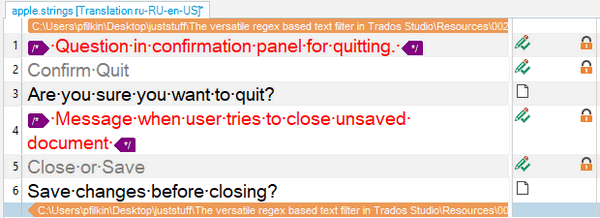
Perfect… I now get these benefits:
- my analysis will only include the translatable text
- when I confirm a segment I will only ever move to the next segment for translation
- I can always read the comments
- I can always see the key string
… and I get one little annoyance! The segment with text between tags (the comment) retains the red colour when I lock the segment whilst the other segment does not. If I did this again I’d use grey as the colour as opposed to red because I find it distracting… but I’m leaving this here because you may also come across a similar problem as me.
WHAT ELSE?
Well, the apple strings file was just one typical example, so here’s a few more (just the settings and what you should get) so you have some idea of how to use the rules for these sort of files that we do see quite often in the community forums.
Another way to handle our apple strings example
If you’re only interested in the translatable text and don’t want to see the comments or key strings at all then you can also handle this using the Document Structure node in the file type settings by telling it exactly what you want to extract in the first place :

| “.+=s” | Match a double quote, keep matching any character until it’s possible to match an equals sign followed by a space and a double quote |
| “;$ | Match a double quote followed by a semi-colon at the end of the line |
That should allow me to extract the value string in the highlighted text below:
/* Question in confirmation panel for quitting. */ "Confirm Quit" = "Are you sure you want to quit?"; /* Message when user tries to close unsaved document */ "Close or Save" = "Save changes before closing?";
This nicely previews like this:

LNG (Language Resource Files) and PHP (Array Files)
These types of files are used by various software applications and I have seen them (rightly or wrongly) with different file type endings, so it’s important to note the ending when you create your file type as you’ll need to use this in the File dialog wildcard expression which you’ll recall from step 1 in the CSV example. Typical examples I’ve come across are things like *.lng, *.ini, *.php, *.txt. The main thing is that the format of the text in the file could be something like this where you’re interested in getting at the highlighted text only:
lng file example
[trPrint] TR_About="&About..." TR_FormCaption="Find Text..." TR_SaveFilePositions="&Remember editing positions"
or something like this:
PHP array file
<?php /* en.php - english language file */ $messages['hello'] = 'Hello'; $messages['signup'] = 'Sign up for free'; ?>
All of these sort of files follow the same basic principle (as far as we’re concerned for the file type creation) and can be handled easily using the Document Structure node in the file type settings as we did earlier for the simplified apple strings file type. For the language resource file, lng, I could use something like this:
| .+=” | Keep matching any character until it’s possible to match an equals sign followed by a double quote |
| “$ | Match a double quote at the end of the line |
Which should get me:

Not bad… but I could improve on this and also protect the accelerator keys you can see in the text (& symbol) which will also help me with QA to avoid these important missing tags. To do this I just add a simple placeholder rule in the Inline tags and make sure the Inline tag behaviour is set to Include:

Now I have this:

So that was simple enough… and what about the PHP array file. A very similar task, and I could solve it with these opening and closing patterns in the Document structure node:
| .+s’ | Keep matching any character until it’s possible to match a space followed by a single quote |
| ‘;$ | Match a single quote followed by a semi-colon at the end of the line |
Which should get me:

So very similar and very straightforward.
Final Words
If you have a text based file type like these and after reading this post are still having problems then feel free to share a snippet and if I can do it I’ll add your example to the list. This sort of thing comes up so often I think the more we have as examples the better.
I also had some thoughts around what’s lacking with the current features for handling these file types in Studio and if we don’t see them in the product in the future we might take a look at handling them through the SDL AppStore:
- ability to define a pattern you can assign as a comment
- ability to define a pattern you can assign as Document Structure Information
- ability to define source and target patterns in case the file you have is multilingual/bilingual
If you have any other thoughts of your own feel free to add them and we can consider these as well. In the meantime I’ve added these to the SDL Ideas site… so go and vote today!
Hi Paul, I enjoyed reading this post! Really useful resource to point to. I especially like your ideas of enabling context information to be displayed to the translator. Can the XML filetype capitalize on that? A while ago I suggested that the XML filetype with embedded content processor would profit greatly from context information (https://community.sdl.com/ideas/translation-productivity-ideas/i/trados-studio-ideas/enable-more-document-structure-information-when-using-the-embedded-content-processor)… Could that be done at the same time?
Daniel
Thanks Daniel… I’m a big fan of creating a custom preview when you work with XML but it is a little buggy at the moment as you know which takes from the potential value of a proper preview approach. Hopefully we’ll fix that soon!
On adding document structure from an XML. I think you can do this already by using XPath to populate the description when you add structure information to a rule. Maybe that would be helpful… probably one to discuss on the forum and see if we can achieve what you need.
Hi again Daniel, I just got around to reading your link and realised I missed the point of your comment altogether. But no, this could not be done at the same time. The feature you need relates to the XML filetype and the way it works with the embedded content processor. This is something managed by a team we call “Core Components”. It’s nothing we could handle in the AppStore team unless we completely rewrite the XML filetype and this would be a massive undertaking and a pointless one.
The Regex Delimited Text Filetype is a smaller piece of work, and given the changes I want are quite wide ranging to something that is quite limited in its current scope we might take this on in the AppStore team if there is no sign of Core Components having any appetite for it.
Hi Paul,
Very nice reading this. I am completely new to regex filters, but these are more and more needed in my industry. Would you have a solution to filter the below tags?
———
“Add or edit limits by going to [onClickGaming(Responsible Gaming)]”
“To access your History please [onClickHistory(click here)]”
———
In theory, it should be simple since the opening pattern is [whatevertag( and )] the closing pattern. The content between the brackets () needs to be translated.
Thanks in advance.
D
Sure… opening pattern:
^[^\(]+\(
Closing pattern:
\).+$
Hi Paul,
Many thanks for this useful post.
Do you know if it’s possible to use regex in the XML embedded content processor to match over multiple lines? For example, I have an XML file with markdown as embedded content. The embedded content contains codeblocks that look like this:
“`
codeblock line 1
codeblock line 2
codeblock line 3
“`
I am trying to match the whole thing, including the “` at the beginning and end so that I can set it as Non-Translatable.
If I define a tag pair in the embedded content processor with the start and ends tags being “` then converting to SDLXLIFF fails: “Problem during writing internal tags! Check the definitions of your internal tags.” I am guessing that the start and end tags can’t be identical.
As an alternative, I tried making the whole codeblock a placeholder. The following regex does match the codeblock including the “` , but in Studio it doesn’t become a placeholder. Studio doesn’t seem to consider the regex to match the codeblock, although my regex tester says it does.
`{3}([\S\s]+)`{3}
Do you have any ideas how else I could make this work?
Studio 2019 has a markdown filter, which I’d love to use but I can’t because of the XML around the markdown.
Thank you!
Kind regards,
Perry
Hi Can you help to show token <token=”{Text}”/> as an inline tag in SDL trados 2022, where text comes in many forms in tag. It can be one word with number as name1 or 2 or more words with underscores as responsible_name. Many thanks in advance
You could use something like this for example:
Opening tag:
<[^>]+?"Closing tag:
"/>It doesn’t matter what form the text takes, this will pick up anything between these opening and closing tags.