 The RWS Community has always been a great place for me to learn more about the Trados products, especially with regard to how its use is perceived by others, and how the workflows the product was designed for can often be very different to reality. More recently, since my own role at RWS has changed, I’m somewhat removed from these realities and I also tend to pay less attention to the release notes for the desktop tools than I used to. But now I’m seeing that the community helps here as well and even triggers renewed interest in parts of the product I’d stopped paying a lot of attention to.
The RWS Community has always been a great place for me to learn more about the Trados products, especially with regard to how its use is perceived by others, and how the workflows the product was designed for can often be very different to reality. More recently, since my own role at RWS has changed, I’m somewhat removed from these realities and I also tend to pay less attention to the release notes for the desktop tools than I used to. But now I’m seeing that the community helps here as well and even triggers renewed interest in parts of the product I’d stopped paying a lot of attention to.
A recent post from Yulia Kovalskaya about fuzzy matches in terminology got me thinking about a topic I’d never thought much about before… fuzzy matching of terms coming from your termbase. In fact I hadn’t even noticed that the introduction of Trados Studio 2024 introduced improvements in terminology integration between Trados Studio and MultiTerm that are all part of a bigger effort to be able to pave the way for Studio’s integration with third-party terminology solutions… something I’ve long wished to see so that it could become possible for 3rd party developers to improve the terminology solutions available with Trados Studio, and with a deeper integration that could use many of the features that were only available to MultiTerm. So great to read these four key improvements:
- The Term Recognition window now displays the fuzzy match score next to each term, providing a clearer indication of the term’s relevance.
- Terminology Verification has been enhanced to accurately identify and flag duplicate terms within the same segment.
- Improved handling of source terms in non-Latin languages.
- Cleaner integration for third-party terminology app providers, allowing for more seamless integration with Trados Studio.
The main one of interest here, mainly because Yulia referred to it and I wasn’t aware of it at all, was the Term Recognition window displaying a fuzzy match score for the terms found in the source segment. I did reply to the question, but decided it might make a good article to explore a little more as we often talk about translation memory matches, but not terminology… or at least I haven’t!
MultiTerm Matching
The exact mechanism behind how MultiTerm matches terms is a secret, that even if I knew, I’d be shot for sharing!  So we’ll keep this based around the question that Yulia asked, but expand a little in simple terms to clarify the difference between translation memory matching and terminology matching.
So we’ll keep this based around the question that Yulia asked, but expand a little in simple terms to clarify the difference between translation memory matching and terminology matching.
Translation Memory searching breaks down into two (ignoring the more complex areas of fragment matching) and these would be a normal TM search, and a concordance search. In some ways a concordance search could be seen as being similar to a terminology search (MultiTerm) but they are not the same and the match values you now see in Trados Studio 2024 could well raise questions similar to the one Yulia asked because of these differences.
TM Segment Matching (Normal TM Search)
This is the standard matching process Trados Studio uses when you move to a new segment during translation. It compares the entire source segment you’re working on against all stored segments in your translation memory. The match score is calculated using algorithms like Levenshtein distance, which measures how many edits (insertions, deletions, substitutions) are needed to turn your segment into one that already exists in the TM.
The result is a fuzzy match score (e.g. 100%, 85%, 70%) that reflects how similar the whole sentence is to previous translations… not just a part of it. It’s designed for full-sentence reuse, and is less sensitive to the meaning and more focused on structure and word-level similarity.
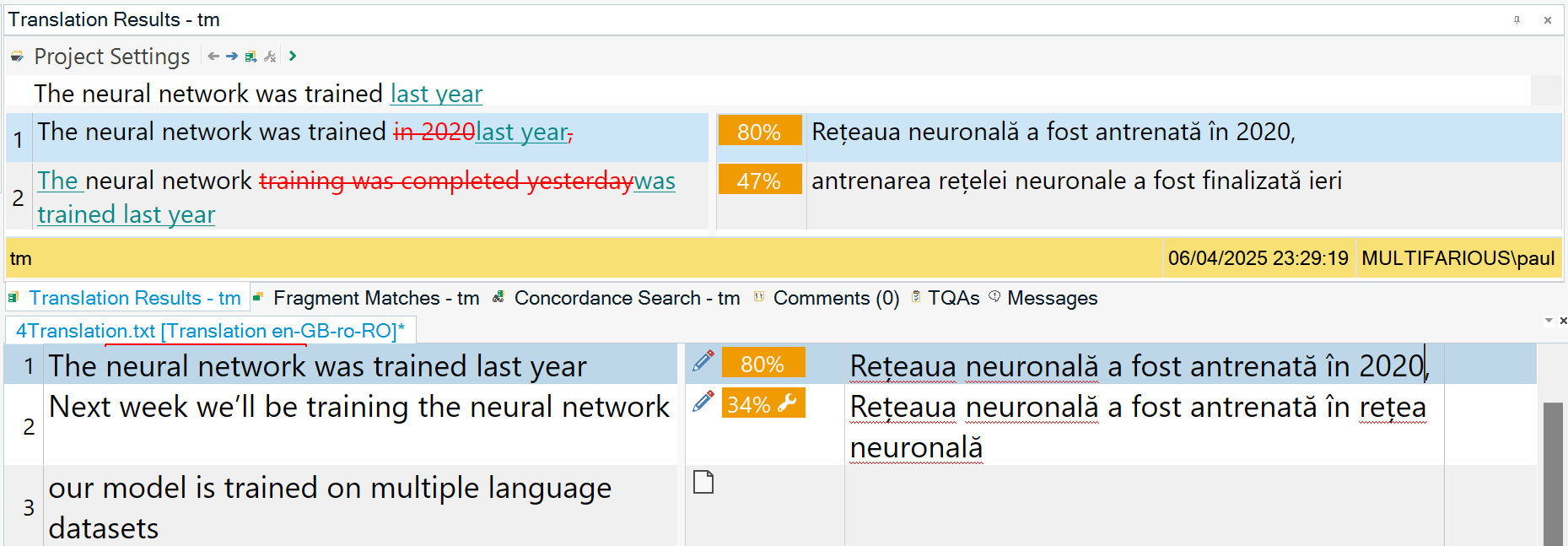
Example:
A new source segment like “The neural network was trained last year” might return an 80% match against “The neural network was trained in 2020,” because there are only small differences as shown below:
TM Concordance Search Matching
This works a bit like a TM segment comparison. Most likely using algorithms similar to those used in full TM matches such as Levenshtein distance (character-level or token-level edit distance).
The fuzzy score tells you how close your selected phrase is to phrases in stored TM segments. When you select a phrase and run a concordance search, Trados compares that phrase to parts of segments stored in the TM. It doesn’t penalise for extra words before or after the matched portion because the match is not against the full segment, but rather how closely your selected phrase aligns with a portion of the TM segment.
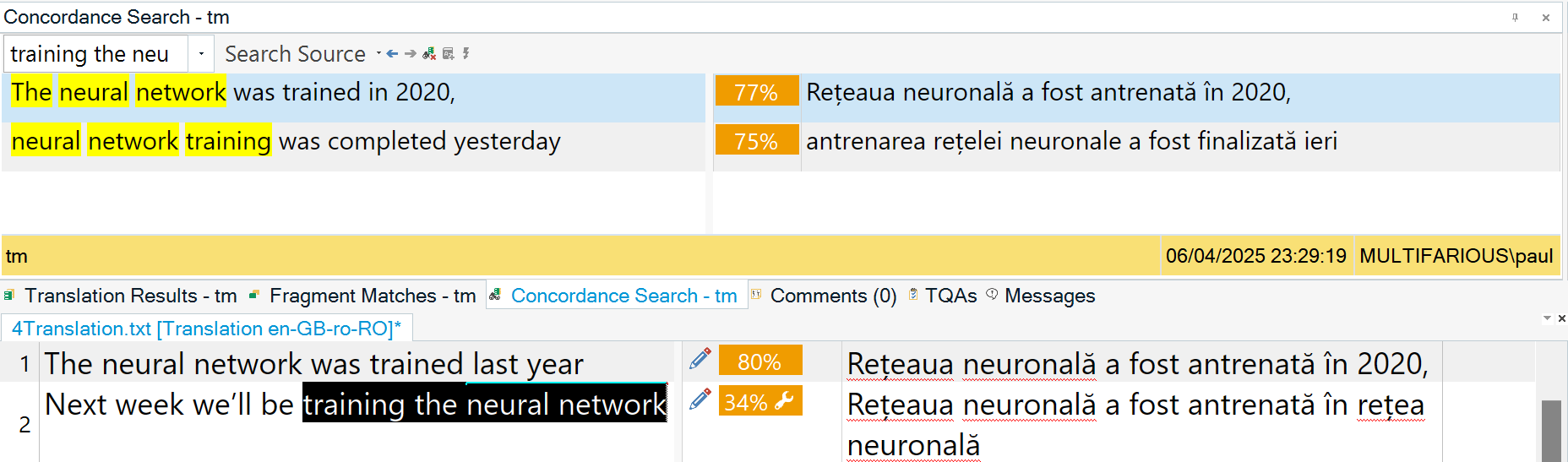
Example:
Selecting “training the neural network” and running a concordance search on it might yield 75% against “neural network training was completed yesterday”, because the words match, but they are in a different order and missing the word “the“, so the alignment is imperfect as shown below:
MultiTerm Fuzzy Matching
MultiTerm uses a form of fuzzy matching to identify terms in your source segment, even when the match isn’t exact. No single technique is the standard for this, but a hybrid approach is commonplace. For example, n-gram matching for scalability and flexibility, layered with edit distance for precision, and token heuristics for real-world robustness, all optimized via indexing. The goal being to determine how closely a given term resembles a portion of the source text, based on several linguistic and structural factors.
The fuzzy match score reflects the degree of similarity between the stored term and its possible appearance in the segment. This similarity is typically influenced by:
-
Token presence: Are the key words in the term actually present in the segment?
-
Token order: Are the words in the same sequence as in the term?
-
Token proximity: Are the words close together, or scattered across the sentence?
-
Intervening content: Do additional words or modifiers interrupt the term’s structure?
-
Orthographic variation: Are there minor spelling differences, pluralisation, or inflections?
It’s important to note that this process is form-based, not meaning-based. It doesn’t consider synonyms, paraphrasing, or surrounding sentence context. It focuses purely on how similar the source text is to the stored term in terms of surface form.
Example:
If your termbase contains “language model”, and your source segment says:
“our model is trained on multiple language datasets” then MultiTerm might suggest a match with a lower score… 61% if you set the minimum threshold low enough as shown below:.
 This is the only example of the new feature in 2024 showing the fuzzy match value in the term recognition window that I’ll show in this article. You can see the “61” between the source term (language model) and the termbase name (tb). So if you want some more I’d encourage you to visit the RWS Community and review the thread with Yulia as you’ll find a good number of examples to illustrate the point.
This is the only example of the new feature in 2024 showing the fuzzy match value in the term recognition window that I’ll show in this article. You can see the “61” between the source term (language model) and the termbase name (tb). So if you want some more I’d encourage you to visit the RWS Community and review the thread with Yulia as you’ll find a good number of examples to illustrate the point.
Comparison
I’ve never looked at how these different features carry out their matching in this blog in any real detail before, and it is interesting, and when I review this text I’m wondering what the real difference is between concordance matching and terminology matching since both of them aim to identify partial matches within larger segments. I think it’s less about the algorithms, although there are differences, and more about the underlying goals which affect how similarity is interpreted.
- MultiTerm is about enforcing terminological consistency, and concordance is about offering contextual guidance from translation history.
- MultiTerm asks “Does this sentence contain my predefined term?” whilst concordance asks “Where else have I used something like this phrase?”
- MultiTerm expects a tight match to the term’s surface form whilst a concordance search allows for looser alignment… the goal being to show potentially useful matches, even if imperfect.
- In MultiTerm, a fuzzy score is a signal of confidence that the exact term is being referenced whilst in concordance, a fuzzy score is more about resemblance, not correctness… it’s a hint, not a validation.
In essence, while both concordance and terminology searches leverage fuzzy matching to identify partial matches, their purposes diverge. MultiTerm drives terminological precision with a focus on exact term validation, while concordance offers a broader, context-rich exploration of translation history. This distinction shapes their fuzzy score interpretations… MultiTerm’s as a marker of correctness, concordance’s as a suggestion of relevance.
A good feature?
Ultimately, the introduction of this new feature in Trados Studio 2024 to display the fuzzy match scores shine a light on a subtle truth: similarity isn’t sameness. MultiTerm demands precision to ensure the terminology is controlled, while concordance thrives on loose resemblance to help shape the translation and provide some consistency… yet both remind us that in translation, ‘close enough’ isn’t always enough. When consistency or context hangs in the balance, ‘When close enough… isn’t!’, captures the challenge of knowing when a match really does fit the bill.
So when I think about the concept of a fuzzy match for terminology lookup it almost seems insane without the ability to see whether your match is 100% or not!
What about AI?
I can’t leave this article without at least mentioning AI a little!! The introduction of AI into translation workflows will undoubtedly influence the need for managed terminology, but will it eliminate it? Or will it just reshape its role and how it’s implemented?
Managed terminology, as we do with MultiTerm, is all about ensuring consistency, accuracy, and compliance… especially in industries like legal, medical, or technical translation. That kind of control is something AI doesn’t always prioritise. Large Language Models (LLMs) and neural machine translation (NMT) are trained on massive amounts of data and can often figure out the right term from context. So if you feed them “neural network,” they might correctly return “réseau neuronal” in French even without a termbase. That sounds great in theory, and in some cases it probably works, but it’s also where problems can start. The same model might decide to use “réseau nerveux” instead, which might be technically valid in a different context… but just not the one you intended. So while AI might reduce the need for manually curated termbases in more general content, it still can’t guarantee the precision you get from managed terminology.
In fact, I think AI might actually help strengthen the case for termbases, not replace them. For example, I can imagine tools evolving (if there aren’t any around already) that use AI to scan your content… manuals, websites, old TMs… and automatically suggest key terms for your termbase. You still need a human to approve them, but that kind of automation could make building and maintaining a termbase a lot easier. This fits nicely with the work being done to open up terminology integration in Studio 2024 where allowing third-party providers to plug into the term recognition workflow with a deeper integration supports a real opportunity to bring in more dynamic, AI-driven term suggestions alongside our existing termbases.
That said, we shouldn’t forget where this matters most. If you’re translating for a pharmaceutical company, “acetylsalicylic acid” has to stay just that. You can’t have AI deciding “aspirin” is close enough. Or “liable” vs. “responsible” in a legal context where it might seem like a small thing, but it can completely change the meaning. AI might be helpful, but it still needs the discipline and rules provided by a managed termbase. Post-editing in these situations is still going to rely heavily on those resources.
One of the interesting things AI does bring to the table is the ability to understand context really well. So instead of relying on fuzzy match rules like token order or proximity, it can just know that “language model training” and “training the language model” mean the same thing. Of course this can be helpful, but doesn’t always provide consistency. A termbase might require “cloud computing,” but AI might generate “cloud-based computation” instead because it flows better. That tension between AI’s flexibility and the non-negotiable nature of managed terminology is probably going to become more of a thing for translators to manage.
I think we’re already seeing AI blurring the lines between concordance, TM matches, and terminology. The role of termbases not disappearing, but perhaps shifting so they’re less of a front-and-centre tool, and more of a background calibrator, keeping AI suggestions in check. In the near to far future… answers on a postcard!
Bottom Line
AI won’t erase the need for managed terminology… it’ll probably transform it. While AI can infer terms dynamically and reduce reliance on static termbases, it’s probably not ready yet to fully replace the precision and control that tools like MultiTerm provide, especially in domains where terminology is non-negotiable. Instead, AI will most likely augment terminology management, automating term extraction and enhancing integration, shifting termbases from rigid enforcers to adaptive calibrators. As AI pushes translations toward ‘good enough,’ managed terminology will remain the guardrail ensuring that, as the saying goes, ‘When close enough… isn’t!’… precision still prevails where it counts.
 Every now and then I see an application and I think… this one is going to be a game changer for Studio users. There have been a few, but the top two for me have been the “
Every now and then I see an application and I think… this one is going to be a game changer for Studio users. There have been a few, but the top two for me have been the “ It’s all about the termbase definition when you want to merge termbases, or import data into MultiTerm termbases. The XDT… otherwise known as the MultiTerm Termbase Definition file is the key to being able to ensure you are not trying to knock square pegs into round holes! I’ve written in the past about
It’s all about the termbase definition when you want to merge termbases, or import data into MultiTerm termbases. The XDT… otherwise known as the MultiTerm Termbase Definition file is the key to being able to ensure you are not trying to knock square pegs into round holes! I’ve written in the past about  quite a good analogy… the four keys in the image on the right will all open a lock, but they won’t all open the same lock. If you want one of these keys to open another lock then you need to change its shape, or it’s “definition”, to be able to open the lock. A termbase definition works in a similar way because MultiTerm is flexible enough to support you creating your own lock. That lock might be the same as someone else’s, but theirs could also have a different number of pins and tumblers which means your key won’t fit.
quite a good analogy… the four keys in the image on the right will all open a lock, but they won’t all open the same lock. If you want one of these keys to open another lock then you need to change its shape, or it’s “definition”, to be able to open the lock. A termbase definition works in a similar way because MultiTerm is flexible enough to support you creating your own lock. That lock might be the same as someone else’s, but theirs could also have a different number of pins and tumblers which means your key won’t fit. I
I  I ran a beginners and an advanced workshop at the ATA56 pre-conference day in Miami this year. A really fun day for me as we start the day with no specific agenda or pre-defined course and then try to shape the session to suit the needs of the attendees. The beginner tends to be a little more prescribed, to start off with at least, and the intention is to try and cover the basics of how Studio and MultiTerm work.
I ran a beginners and an advanced workshop at the ATA56 pre-conference day in Miami this year. A really fun day for me as we start the day with no specific agenda or pre-defined course and then try to shape the session to suit the needs of the attendees. The beginner tends to be a little more prescribed, to start off with at least, and the intention is to try and cover the basics of how Studio and MultiTerm work.
 I think I’ve discussed Project Templates in the past, although perhaps only in passing. So let’s start off by painting a picture of the situation you find yourself in where templates come in handy. You maintain your own Translation Memories, in fact you have five you regularly use for every project but keep them separate because they are based on different sublanguages and you have some clients who adhere strictly to the minor linguistic differences. You have a couple of termbases that you also like to add to every project and you find it easier to manage the terminology for your clients in separate termbases rather than use custom fields that complicate the ability to import/export with your colleagues. You also have very specific quality assurance rules that you’ve honed over many years of translating and you know these are reliable and help you when you work.
I think I’ve discussed Project Templates in the past, although perhaps only in passing. So let’s start off by painting a picture of the situation you find yourself in where templates come in handy. You maintain your own Translation Memories, in fact you have five you regularly use for every project but keep them separate because they are based on different sublanguages and you have some clients who adhere strictly to the minor linguistic differences. You have a couple of termbases that you also like to add to every project and you find it easier to manage the terminology for your clients in separate termbases rather than use custom fields that complicate the ability to import/export with your colleagues. You also have very specific quality assurance rules that you’ve honed over many years of translating and you know these are reliable and help you when you work. I love this cartoon with the husband and wife fishing on a calm weekend off.
I love this cartoon with the husband and wife fishing on a calm weekend off. Why is MultiTerm a separate program, I can do exactly the same thing with another CAT tool? This is a fairly common question, and it has a very good answer too. It’s because MultiTerm is multitudinous! That is, it can be extended by you to provide a variety of termbases, so many in fact that you could probably create a structure to match anything you liked and you won’t be shoe horned into a fixed structure. As I thought about this the
Why is MultiTerm a separate program, I can do exactly the same thing with another CAT tool? This is a fairly common question, and it has a very good answer too. It’s because MultiTerm is multitudinous! That is, it can be extended by you to provide a variety of termbases, so many in fact that you could probably create a structure to match anything you liked and you won’t be shoe horned into a fixed structure. As I thought about this the