 Every now and then I see an application and I think… this one is going to be a game changer for Studio users. There have been a few, but the top two for me have been the “SDLXLIFF to Legacy Converter” which really helped users working with mixed workflows between the old Trados tools and the new Studio 2009, and the “Glossary Converter” which has totally changed the way translators view working with terminology and in my opinion has also been responsible for some of the improvements we see in the Studio/MultiTerm products today. There are many more, and AnyTM is a contender, but if I were to only pick my top three where I instantly thought WOW!, then the first two would feature. So what about the third? You could say I have the benefit of hindsight with the first two although I’m not joking about my reaction when I first saw them, but the third is brand new and I’m already predicting success!
Every now and then I see an application and I think… this one is going to be a game changer for Studio users. There have been a few, but the top two for me have been the “SDLXLIFF to Legacy Converter” which really helped users working with mixed workflows between the old Trados tools and the new Studio 2009, and the “Glossary Converter” which has totally changed the way translators view working with terminology and in my opinion has also been responsible for some of the improvements we see in the Studio/MultiTerm products today. There are many more, and AnyTM is a contender, but if I were to only pick my top three where I instantly thought WOW!, then the first two would feature. So what about the third? You could say I have the benefit of hindsight with the first two although I’m not joking about my reaction when I first saw them, but the third is brand new and I’m already predicting success!
Not so long ago we saw a plugin called the SDL Trados Studio Word Cloud which I believe the developer created just because he could… and it looked cool. Fair enough, I liked it and that’s a good enough reason for me. But then I wondered how much better this might be if we could just string a few things together to solve a problem… and so I wrote this article “It’s not all head in the clouds“. The article turned out to be quite popular, not least because it opened up the possibility to extract term candidates from a Studio project which is something you still can’t do today without a bit of a workaround using the SDLXLIFF to Legacy Converter to get a TTX or a BilingualDOC from your files and then use these in SDL MultiTerm Extract. But if the process I went through in the article to achieve this was made simple with a single plugin it would of course be even better. And then we got lucky!!
We got lucky because we took on a couple of interns in our app development team, Laura Paraschivescu and Adrian Maniu, and tasked them with creating this very solution. Between them they have created an application to complete my top three… an application I love playing around with because it has really put the fun into terminology extraction. If you know me, I bet that’s not something you’d expect me to say!
projectTermExtract
The application they have developed is called projectTermExtract and you can download it from the appstore for use with Studio 2015 or 2017, the currently supported versions of Studio. In a nutshell the way it works is this:
- Select your Studio Project or file(s) in your Project
- Extract the term candidates as a visual display
- Narrow down the potential candidates
- Add a file containing these candidates to your Studio Project for translation
- Convert the translated file to a Termbase and add it to your Project
I’ll run through the process in a video at the end, but I thought a quick visual would be interesting just to show how simple this really is. All I did was right-click on the files in my project, select “Extract Project Terms” to extract the terms and then cut down the candidates with a few rules:
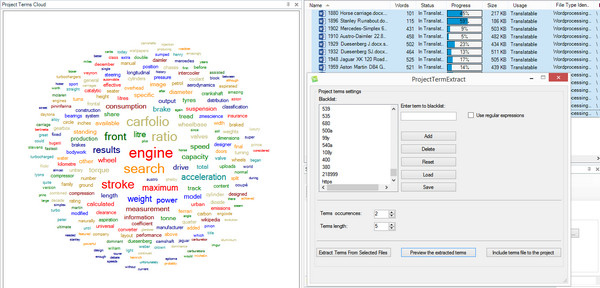
The rules are straightforward and make sense without getting too complex. Perhaps over time and depending on the reaction from users when they play with this the extraction algorithm could be enhanced, but for the time being it’s very simple and just extracts single words from your Studio Project. You then have the ability to do the following:
- Create a blacklist of words you do not wish to be added to a termbase
- regular expressions are supported so you can filter out product codes, numbers, dates etc. in one go
- the list can be saved for the active project and pulled up again easily should you wish to stop and come back to the task later
- words can be added or deleted from the list
- Set the number of times a word is allowed to occur in the Project before it gets extracted
- Set the minimum length of a word before it gets extracted
All the time you play with these simple options you can preview the effect by regenerating the wordcloud in an instant. I find this part of the application to be strangely addictive just watching the difference your changes make to the potential candidates!
Once you are satisfied with your setup you click on the “Include terms file to the project” button and this adds a file to your project and prepares it for translation. You won’t see it immediately, but if you press F5 this will refresh the view and the file will be there. Now you can translate it and once you are complete just right-click on the file in Studio and select “Generate Termbase“. The termbase is added to your project immediately and you’ll start to see results that can be used to help your productivity and consistency immediately:
- term recognition you can apply via autosuggest
- fuzzy match repair where you have similar sentences with differences in terminology
If there were extracted terms in the final list which you don’t want in your termbase then just don’t translate them. Any target segments that are left empty will not be added to your termbase. So if you have a lot of words in your Project and it wasn’t possible to see them clearly in the word cloud you still have a way to exclude them as you work. The word cloud just delivers a very nice and visual way to clean out the obvious stuff before you get to work on the detail. It’s also worth noting that whether the translations are confirmed or not they will be added to the termbase. They just have to be present in the target and they will be added.
What we need now is a nice way to deliver a termbase like this to your customer if they don’t use any tools at all. We do have the RTF export from MultiTerm… but this doesn’t always deliver what you expect and you need to be an expert with Rich Text syntax to be able to change things to meet your needs. I’ve had this on my “reluctant to learn todo list” for years! Perhaps we’ll see a nice little plugin for this in the future and support an easily customised export to DOCX… I certainly think it would be helpful! In the meantime your best options (if the RTF export doesn’t work for you) are probably these:
- share the SDLTB (if they use Studio)
- export to another format like Excel or Tab Delimited text and edit to suit (Glossary Converter will make short work of this)
Some things to watch out for
The projectTermExtract plugin works brilliantly and I really love it, but there are a couple of things to look out for. The first is languages that the app can’t tokenize such as Japanese and Chinese for example. The algorithm that creates the wordcloud is very simple at this stage so if there are no spaces between words it can’t determine them. Trados Studio has only been able to achieve this since Studio 2017 using it’s upLift technology so the app would need to be able to leverage that. Perhaps something for a future version.
Also, if you decide, after generating your termbase, that you’d like to create another in the same Project using the plugin then this doesn’t work easily. There are some restrictions in the capability of the API and despite everything the developers tried they could not manage this via the APIs. So if you do this you’ll get this message:
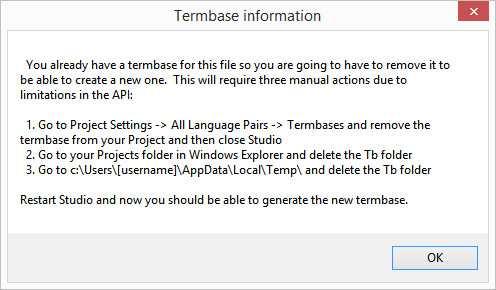
The instructions are quite explanatory and this works perfectly. Hopefully this won’t be something you need to do very often and creating one termbase per Project using the plugin will be enough, so you may never need to do this. Perhaps in a future release the team will be able to overcome this. For now, I hope you like this as much as I do… so much so that when I think of my top three apps the winner is this one! It’s been a long standing omission from the Studio solution and I think even with its currently simplistic extraction method it’s going to make a lot of users very happy… nice work Laura and Adrian!
The process
I have created a short video for anyone who would like to see how this all works in practice… hopefully you’ll find this helpful. If you do then download it today!!
Approx. running time: 14 minutes 31 seconds
Good app indeed. But it should be developed to extract whole terms and not just words.
Hi Christophe, I completely agree and as I mentioned, this is a good start. I’m sure we’ll see many enhancement ideas in the next few months and once we have a good idea how people would like to see this work we can come back and address them with an improved version.
Hey, but what’s this app good for it I have to translate the extracted terms first by hand, before I can gain a term bank? Any translator knows that translating single terms, out of their context is much more work than within. To try it from the opposite side, I have tried the app with a translated project and its TM, and it would function if I were able to insert all the terms from the relative tm with a click per term, but this doesn’t work at all. No terms are recognised from the existing tm. Where is the error? Thanks for any useful reply to this.
Hi Maren, context is important of course and it’s up to you to find the context. If you were to use MultiTerm Extract, or any other terminology extraction tool from a monolingual source you have the same issue. Maybe one way to tackle this is to create a TM from the source files by copying source to target and then use this as a read only TM for the translation of the terms. You can then concordance each one and see the context. probably a number of ways to do this, not least to just search the source file.
On your own test… I guess you need to lower your search settings or use concordance instead. I imagine your project TM contains full sentences and not just single terms.
Hi Paul, thnx a lot for presenting the new plugin.
Is there a chance to edit the blacklist as a file, so we don’t have to enter the terms one by one, but use a predefined blacklist?
Best regards
Burim
Found it in the project folder 🙂
Anyway, it would be great to have the possibilty to chose the blacklist file via a dialogue.
Hi Paul, after doing some mor tests, I have the following issues, maybe you can pass this further to the colleagues who have been working on the plug in?
1) small letters: I get all the extracted words in small letters, which is not really useful for german words
2) case sensitive: as the words in my german blacklist often start with capital letters, the plug-ins blacklist does not eliminate them, as the extraction is with small letters. I even can not manually add the same word in once starting with small and once in capital letter. I can make a list in the txt-blacklist file though, adding both versions.
3) plugin not saving the settings: when changing from the Project View to the Files View you lose all settings and get an extraction from the beginning, without blacklist.
3) I have a problem including the files to the project, receiving the follwoing error message:
“Failed to include projetct terms file: Unable to add the XML file to the project! Could not find the file with id: 00000000-0000-0000-000000000000.
Best regards
Burim
Hi Burim, it would make a lot more sense to take this conversation to the community as this is not really a great place to engage properly on this app. But just a few thoughts:
1. small letters? Do you mean lowercase or the actual size on the screen? If the latter seems it may be related to their frequency.
2. case sensitive: surely this is because you have tried to create your own blacklist with words that don’t exist in your project? Don’t try and bend the solution to do something it has not been designed to handle. I think it’s a good idea to have this but it needs to be done properly.
3.) we need more info on this, so the steps you followed, the manual workarounds you tried to implement etc.
Definitely best to report this in the AppSupport forum in the community please.
Hi Paul, I will report in the AppSupport forum 🙂
And yes, lower caaaaaseeee… this was the word I was searching for (sorry). The plug-in extracts all words in lower case.
Creating my own black list actually works very fine. The only problem is related to the lower case issue.
Thnx.
Burim
Hi Burim, just to close this bit off for anyone reading it,,, we have added the features you asked for and resolved the problem, all in the current version on the store. Thank you for your feedback!
Hi Paul, thank YOU 🙂
Hi Paul,
I’ve tried to apply this to my projects but after getting to the point of wanting to generate the termbase I receive the error “unable to generate the termbase! Unable to connect to the termbase repository! …”
Here is the screenshot: http://i63.tinypic.com/1gptgp.png
Do you have any ideas why?
I am clicking on the xml, not on the other files.
Thanks,
Nicola
Hi Nicola, have you updated Studio and MultiTerm so they are using the latest versions? It’s not enough to just update one without the other.
Hello! I am having this issue too…and both my versions are updated…any idea how to solve this? Thanks
Hi Gloria, best to post this into the SDL Community where we can help you properly with the issue.
So far, this technology works unexpectedly well for Chinese in part because of the lack of tokenization. SketchEngine already has the best bigram/trigram extractor for Chinese on the market and it is hard to beat their keyness score features. However, when it comes to multiterms, SketchEngine cannot process these, but it seems that the Trados extractor is quite effective for extracting Chinese multiterms when the minimum length is set to “4.” This rarely gives false positives for Chinese at it is quite rare for 4 random Chinese characters to appear randomly together as opposed to as part of a logical word.
Hi Adrian, that’s an unexpected bonus for me! Thank you for sharing that.
Dear Paul,
do I find anywhere in your blog something about tags beginning with [[
I need it for .po files
Sorry for leaving a comment at a wrong place!
Unfortunately, doesn’t work for the languages that have declensions
Thank you for the in depth video! Would’ve gladly processed it, however I’m guessing it doesn’t work for LV. Got the generic “Unable to extract the SDLXLIFF content! Objectreference blahblah” and that was that.