
When the developer of the Word Cloud plugin for SDL Trados Studio first showed me the application he developed I was pretty impressed… mainly because it just looked so cool, but also because I could think of a couple of useful applications for it.
- You could see at a glance what the content of the project was and how interesting it might be for you
- It looks cool… or did I say that already?
Actually if I’m honest I never got any further than thinking about those two things so this application was a kind of “head in the clouds” app that was almost an interesting experiment that seemed a good idea but we’re not 100% sure why. 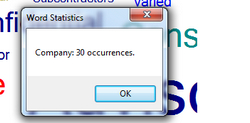 But there is one more interesting feature to this plugin which is that you can click on the words and it tells you how many occurrences of them there are. This is interesting because if you had a termbase before you start that contained all these terms then you have consistency of translation as well as autosuggest capability which could be quite useful. So it’s a sort of term extraction tool without you really having to do any work at all. Well it would be a term extraction tool if you could get them out!
But there is one more interesting feature to this plugin which is that you can click on the words and it tells you how many occurrences of them there are. This is interesting because if you had a termbase before you start that contained all these terms then you have consistency of translation as well as autosuggest capability which could be quite useful. So it’s a sort of term extraction tool without you really having to do any work at all. Well it would be a term extraction tool if you could get them out!
So I looked around to see where the file was that held this information after you created the word cloud and interestingly enough it’s saved in the same folder as the project… and even more interestingly it’s a nice simple XML file! In fact it looks like this:
<?xml version="1.0" encoding="utf-8"?> <wordcloud> <hash>1</hash> <words> <word text="Advisor" count="43" /> <word text="Company" count="30" /> <word text="Construction" count="26" /> <word text="flowers" count="1" /> </words> </wordcloud>
The actual file is much bigger than this as you’d expect but the format is repeated all the way through. You get the word as an attribute followed by the word count as an attribute. This is perfect… I guess you can see where I’m going with this now? I can create a simple xml filetype for Studio that can do two things:
- Extract all the words for translation
- Only extract those that are above a certain value
I added the second point because you might not be interested in all the words that are not repeated… you might be, but you might not. So if I create the possibility to set this value in the filetype you can make your own mind up and the filetype becomes very useful. So, what two rules do I need for this, and do I even need two?
The first one to extract the words from the text attribute is simple enough:
//word/@text
So this just uses XPath to extract the words from the text attribute. To set the count I can add this into the same expression like this:
//word[@count>5]/@text
So this just means only take the word elements that have a count value greater than 5 (you can change this to whatever you like… 0 if you want everything, or omit the count part from the rule), and then just take the contents of the text attribute. Simple, and now I have this as my filetype parser rules. I added the //* out of habit to ensure nothing else is parsed… you don’t really need it at all in this case:
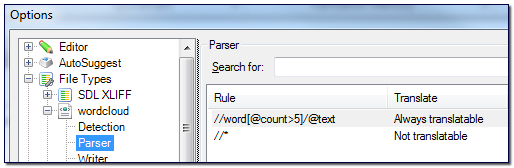
Now what?
So now I translate the file in Studio. When I’ve done this, keeping in mind the end goal here is a termbase, I need to convert the SDLXLIFF to a TMX (unless the developer of the Glossary Converter adds SDLXLIFF to the convertible file formats ;-)) because from there I can easily create the termbase. Conveniently there is an app on the OpenExchange called SDLXliff2Tmx which will allow me to convert an SDLXLIFF to TMX with a drag and drop.
So the process is OpenExchange all the way… with a little translation along the way.
Wordcloud -> XML -> SDLXLIFF -> TMX -> SDLTB
Now if all that sounds complicated it’s not… here’s a short video to explain the process:
So the Wordcloud plugin has a surprising benefit after all… it’s also a free term extraction tool that takes no effort at all and allows you to create a Project termbase before you start your work. Very cool! One last thing… if you want more information on how to use XPath, or how to create custom XML filetypes, you can find a couple of articles here which might be useful:
More Regex? No, it’s time for something completely different.
Why do we need custom XML filetypes?
Very interesting post, Paul. A couple of questions spring to mind:
1. I see there are no “and”, “it” and “a” words, so the app obviously uses a language-specific stop list. Where is it stored?It would be nice to customise this or import my own, if possible.
2. While your XML→SDLXLIFF→TMX→Glossary Converter workflow is ingenious, to say the least, less geeky people would be better off with a wizard or app that uses your workflow or similar system to produce a project TB that we can translate before or during the project.
Good question Emma! So far this is only a useful, but hardly technicaly capable term extraction mechanism. I took a quick look through the code as it’s publicly available on the SDL github site and I don’t think it works the way you think with a stop list… I think it’s calling some built in functionality from Studio via the API to do this.
So the best solution is probably to start gathering enhancement suggestions and then anyone can contribute to the code and improve the app to make it more useful for this facility. I like the idea a lot, and it’s very simple, so a few simple controls to improve the output might be useful.
I also agree with you about the idea of a wizard of some kind so perhaps a developer can look at that too. Maybe have the ability to convert the sdlxliff directly to a termbase via the Glossary Plugin… this would be a very cool app. So two buttons:
1. Take the word cloud and open up in the editor view for translating
2. Convert the finished translation directly to a termbase
That would be pretty cool and possibly not that hard to do with the right developer who already has the various classes in place to do most of this!
Hi Emma and Paul! Is there any news on this issue? With German text the word cloud does show all the “und, oder, der, die, das, in” and so on, making it less useful than it seems to be for english text. The tool would be just great if there would be some kind of ignore list.
Best regards
Burim
Hi Burim, there is no news. But the sourcecode is available so you could do this yourself, or ask a developer to look at it.
Hi Paul, thnx, I’ll ask a friend. Does he need anything from Trados or is the sourcecode all he would need?
Sourcecode is all he’ll need. Go to the developer pages on the appstore to find the API documentation.
Hi Paul,
So it seems our little discussion at NTIF regarding the word cloud did sow a seed! I’m constantly thrilled and amazed how you come up with useful solutions combining the different plugins!
Indeed it did!! Thank you 🙂
Hi Paul,
How does it handle compound terms? Any given word may require a total different translation when it’s part of a compound.
It doesn’t… you’d have to make this change in MultiTerm, or use something like MultiTerm extract to do this thoroughly. This is only a very simple term extraction tool with no intelligent processing in there at all. I think it has some value and it’s pretty interesting, but it’s not designed to be a proper term extraction tool.
Interesting plug-in and was excited until I tried it…
It breaks and cannot be used when you create a project with reference files (which is all projects for me).
Here is the error message:
Failed to generate word cloud: Type “Sdl.ProjectApi.Implementation.ReferenceFile” cannot be cast to “Sdl.ProjectApi.ITranslatableFile”.
Hi Jesse,
You should report this in the community forum for apps. The developer does see these and can address your finding.
I’ll try this, Paul!
Of course, in my case I want to see all the white elephants in bold. Admittedly, I like the idea of the “extract” product, but it is pretty pricey, and a simpler path may also be http://www.online-utility.org/text/analyzer.jsp.
I am always annoyed if I neglect this type of analysis at the very beginning of the work flow – because the “Supercallifragilistic…” words hide in German court decisions like nasty maggots.
Many thanks!
Hi Paul! I just discovered this app and followed the instructions in the film clip, but when opening the xml-file it shows words with 2 or 3 letters anyway. I use Studio 2017 and I suppose the film shows Studio 2015. Could this impact the result?
Hi Elisabeth, the film was 2015, but it would not make any difference. Did you also know we developed this idea further here?