 Unfortunately the practice of being asked to translate a Microsoft Word file that contains HTML code doesn’t look as though it will go away any time soon for some translators. But it’s not the end of the world and it’s often all in the preparation of the Word file before you translate it.
Unfortunately the practice of being asked to translate a Microsoft Word file that contains HTML code doesn’t look as though it will go away any time soon for some translators. But it’s not the end of the world and it’s often all in the preparation of the Word file before you translate it.
This article is just a short.. ish one I decided to write after seeing this come up again in ProZ last week, and because it’s another place where all those lovely regular expressions we’re learning about can come in handy. Yes, Microsoft Word also supports regular expressions, although it is their own flavour. You can read more about this by just googling for “regular expressions in Microsoft Word” and you will find plenty of help on the subject. In Word they are called wildcards but they have many similar principles as we’ll see with this very simple example.
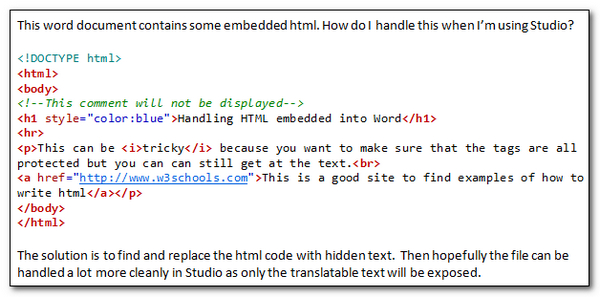
I have a Word file that looks like this and you can see I have added what’s often referred to as embedded HTML copied in as text:
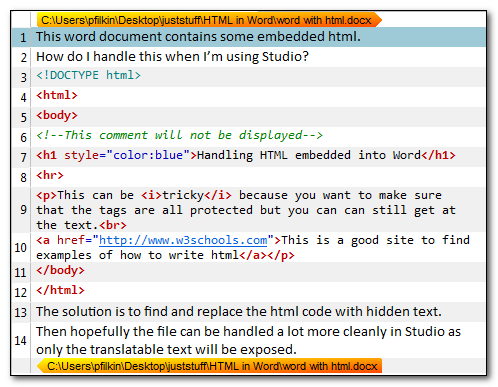
If I open this ins Studio I get this which is not too easy to work with. Hardly surprising though as this is a terrible way to handle content like this… actually if anyone can tell me why people do it I’d be interested to learn!:
So the solution for Studio users is to do one of two things:
- Copy the html into a decent text editor, save as html, and then use Studio to handle the html separately, or
- Use a little regex magic to replace all the tags as hidden text so they can’t been seen in Studio
For this article I’m going to use the latter and search and replace the tags with the hidden formatting property in Word. Sometimes this is an easier approach for files with embedded content like this because the HTML may be scattered all over the place so this is one operation rather than many. To do this I’ll use the following expression to find the tags:
<*>
So very similar to .NET flavour of regex that Studio uses but this has a slightly different meaning. Word uses the angle brackets to mark the start and end of a word so that you can find single words only… sort of like word boundary markers in .NET. I actually want to find the angle brackets so I have to escape them and this is what the backslash does. The star symbol is exactly the same as .NET, it just means find anything. So in my Word find and replace dialogue I set it up like this:
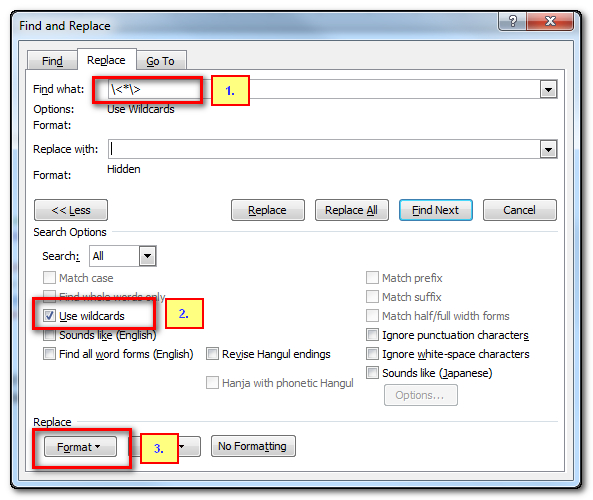
- I enter my regular expression
- I check the “Use Wildcards” checkbox
- I click on “Format”, then “Font” and in there click on “Hidden”

You can see just beneath the search pattern and beneath the empty replace box it tells me what settings I used for each. Now all I do is click on “Replace All”. Immediately all my tags have disappeared and the Word file looks like this:

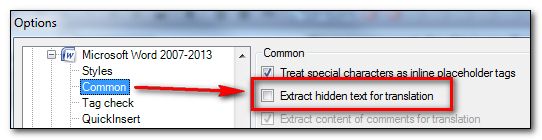
![]() But don’t worry… if I click the display formatting button it all comes back again… so the button shown here on the right. The text will now have dotted lines under it but this just tells you that it has the hidden font properties so I can simply set the option in Studio not to extract hidden text for translation. You can find this option here under the “Common” node in the filetype settings for Microsoft Word:
But don’t worry… if I click the display formatting button it all comes back again… so the button shown here on the right. The text will now have dotted lines under it but this just tells you that it has the hidden font properties so I can simply set the option in Studio not to extract hidden text for translation. You can find this option here under the “Common” node in the filetype settings for Microsoft Word:
Now when I open the file for translation I see this:
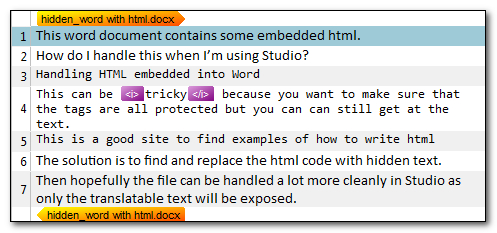
Much easier to handle, all the HTML code is hidden, and I can safely handle the file.
In reality this is an exercise in seeing yet another application for regular expressions in other software tools…. this time Microsoft Office… because I truly hope you don’t see any files like this at all. But if you do, as I do occasionally see, then perhaps this article will be helpful for you in having to safely navigate the content of the file without destroying the tags.
Once you are done you select the text in the target file, right click and select font, then unhide the hidden text. Simple!
Excellent article. Thank you very much for this tip.
Hi Paul,
nice article!
A different, possibly more convenient solution: What if the MS Word file type in Studio is extended by the Embedded Content tab which the XML, Java and Excel file types already contain? This would allow you to define regex for embedded HTML directly in the Studio file type, which would then be reusable for other MS Word files with embedded HTML (and you would not need to apply pre- and postprocessing in MS Word for each single file).
And thinking even a bit further head: If the Embedded Content rules could be exported/imported as a set, and thus reused in other file types, someone could even make the typical rule rule for embedded HTML available via SDL OpenExchange 🙂
Kind regards
Christine
Hi Christine, these are all good ideas and you can expect solutions around your ideas in the future. The openexchange is also a potential solution for other ways to tackle this as well because the new API with Studio 2014 improves the potential for adding more amazing things to Studio, even things that allow a developer to change the UI and how applications work with Studio. I think the power of the openexchange is really going to come into its own with the next release and I’m very excited to see what can be done.
But hopefully the idea I was getting across about how useful regex can be in many applications other than Studio… so it’s not just a geeky Studio feature… came across as well.
Thank you for sharing these tips Paul!
What amazes me is that although tags are hidden, Studio detects and displays the italic tags around “tricky”! Great!
It’s a pleasure Christophe, I learn stuff every day looking at interesting ways to use the tools. in this case it sort of recognizes the tags… and this is because they are “internal” tags. So Studio treats hidden text as tagged text. This means that when they can be moved externally it will always be outside the segment completely, but if it’s inside the sentence then the tags will be shown as inline tags. So it’s not really finding italics tags… rather hidden text tags that are inline.
My approach on this is to use regexes to apply external and internal styles as applicable. The benefit of this being that sometimes tag content is informative about the nature of the text.
Speaking of Studio though, perhaps it would be more user-friendly to have ready made regexes for different file-type embeds, so that the user can simply select the one appropriate, or get Studio analyze the file and find that itself.
Hi Paul, this was just an article I was looking for… I tried regex tagger in memoq but I can’t override the existing tags there, so your solution was just suitable.
thanks!
Jure
Thank you Paul,
this works perfectly with the combination WIN 10 Pro + MS Office 2016 too (I had some doubts 🙂 ).
Claudio
Excellent… I think 😉