 By taggy files I mean “embedded xml or html content” that is written into an Excel file alongside translatable text. In the last article I wrote I documented a method sometimes used by people to handle tagged content in a Word file… funnily enough I came across a Word file containing the XML components of an IDML file today and I guess it must have been prepared in a very similar way judging by the enormous number of tags using the tw4win style to hide them when opened by any SDL Trados version! Proof for me that this practice is sadly alive and well. But I digress… because this time I want to cover how to handle a similar problem when you find HTML or XML tagged content in an Excel file. This crops up quite a bit on ProZ so I thought it might be better to document it once and for all so I have something else to refer to in addition to the Studio help.
By taggy files I mean “embedded xml or html content” that is written into an Excel file alongside translatable text. In the last article I wrote I documented a method sometimes used by people to handle tagged content in a Word file… funnily enough I came across a Word file containing the XML components of an IDML file today and I guess it must have been prepared in a very similar way judging by the enormous number of tags using the tw4win style to hide them when opened by any SDL Trados version! Proof for me that this practice is sadly alive and well. But I digress… because this time I want to cover how to handle a similar problem when you find HTML or XML tagged content in an Excel file. This crops up quite a bit on ProZ so I thought it might be better to document it once and for all so I have something else to refer to in addition to the Studio help.
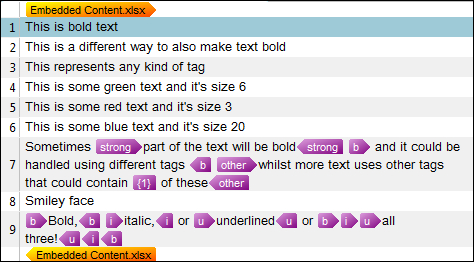
Studio uses a concept when creating custom XML files of parsing the file again based on the document structure type of an XML parser rule and replacing patterns you create in the parsed text with tags. Now let me say that again in English… Studio can look in the content of the text that is extracted for translation and then pick out the bits you don’t want to see and convert them to tags. So for example, if you had an Excel file that contained things like this:
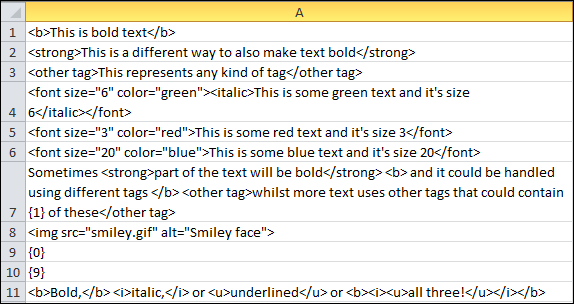
And then you opened this file in Studio you would see something that looked just like the Excel spreadsheet but what you would probably prefer is what it can be changed into as shown below:
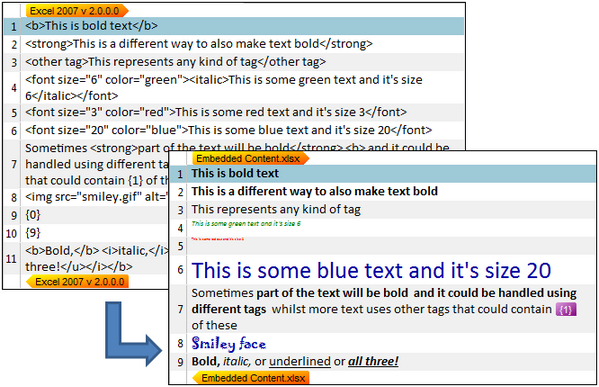
So you want to protect all the angle brackets and text between them. Just in case you don’t like to see all of this in wysiwyg mode don’t forget that you don’t have to. You can change the font sizes as shown by Kevin Lossner and Jayne Fox in a neat little video, or you can also select the default to always show you consistent plain text, and all tags (because we know they are really there even in wysiwyg mode!) all the time with this option here… so plenty of choice to suit your preferences:
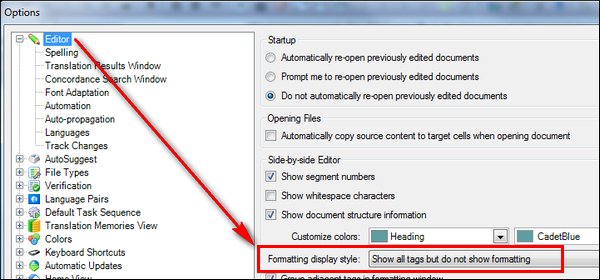
Of course you also don’t have to convert the plain text excel file into the crazy formatting I showed here!
But the important thing is that we have converted all of the tagged content in the Excel file into protected tags in Studio so that you can safely translate the text alone. How do you do this… easy!
You just create some rules, using a little regex, to pick out the text that should be tags. These rules are all added through the Excel filetype settings for XLS and XLSX filetypes in here (the screenshot shows XLSX):
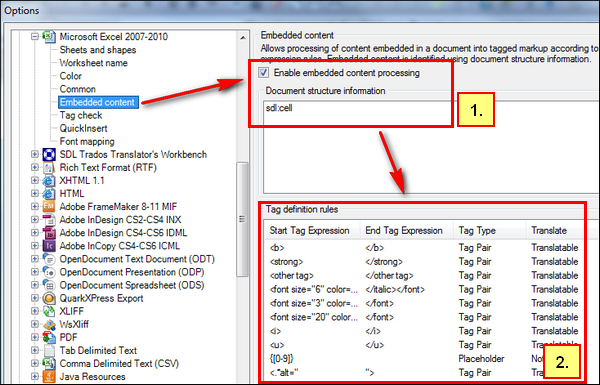
So the process is to first enable the “Embedded Content Processing” in 1. by ticking the box, and then selecting “Cell” from the list of available types. This is because for Excel the ONLY one that works is “Cell”. The rest are all part of the available types when you use the same “Embedded Content Processor” in a custom XML filetype, but they have no effect in the Excel filetype. It makes sense when you think about it as we are dealing with “Cells” in Excel… but it’s not the most intuitive part of this solution.
Once you have enabled the processing you can add your rules as I have in 2. I was a little flamboyant with them in this case just to show you what could be done if you wanted… I could have converted all of the tags in this file with three rules… maybe less if I was really clever. In reality, most Excel files I see translators having problems with only contain quite simple XML/HTML and in these cases the first catch all rule below will probably handle the complete file:
TRANSLATABLE TAG PAIR - CATCH ALL
<[a-z][a-z0-9]*[^<>]*> </[a-z][a-z0-9]*[^<>]*>
PLACEABLES
{[0-9]}
Alt attribute
<.*alt=" ">
The interesting thing is that in my actual example, by getting a little flamboyant I have actually shown how simple it can be because I have just taken the literal text that formed the tags and added these as rules. For example, I don’t want <b></b> tags to be text. So I add them in as a translatable tag pair here:

Quite simple when you look at it like this… but the drawback is that you need to add a rule for every type of tag in the file which is what I did to create the colourful view above. If you have a lot of different tags and it’s a big file (or lots of files) then the slicker regex rule is much better and it may well be all you need to catch all the tags:

Once you have added all your rules, and made them as fancy as you like, you can open the Excel file and all being well you’ll see protected tags, or a fancy wysiwyg format to handle the file.
Just to finish off… the same file displayed using the “no wysiwyg” option I mentioned above will show as follows even if I have set all the fancy rules I did. The segments that don’t show any tags are like this because the tags are actually at the start and end of the cells, so they are not required. If I did want to see them (and have to deal with them) this is also possible by changing them to be internal rather than external in the advanced rules as you add the regular expressions:
Very nice and useful write-up, like all the previous ones! Thanks a lot!
I am just wondering, without reading your great article: How would I have known that I need to select “Cell” from the document structure selection list? I did not find any documentation about the Excel Embedded Content handling in the On-line Help? Wouldn’t it be useful to pre-configure “sdl:cell” for the Excel Embedded Content settings, while leaving Embedded Content processing disabled?
Please continue writing useful articles like this one!
Hi Frank, thanks for your comment and I’m glad you find it helpful. A good question too… I looked all over the place and couldn’t find this mentioned so I have asked our TechPubs to address this in the online help. I guess I came across this problem when we released the feature, asked a developer, and didn’t think about it again until now… my bad! But I agree with you on making it straightforward and I know development have a better solution in mind so this is probably why they have not addressed this specific one. So for now, we can fix the documentation and I hope this article helps as well.
Hi paulfilkin,
I am quite bit wondering about creating custom XML file. Can I use the tag <strong> instead of <b>?
Hi Richard, the good thing about XML is you can use whatever you like… or whatever the originating system can interpret. So whatever elements are in the XML files you receive then this is what you create rules for. If you wish to add tags not in the file that just make sure that the system creating the XML files will know what they mean when they get the target file back? So if <strong> is the tag used for bold by the originating system then all will be well. But if it’s <b> then it may not be a clever idea.
Is there an “Embedded content” section planned for XLIFF file types ? It would be very very useful.
I wish there was such an option with xliff files as well. I am trying to import a MemSource xliff file (it works after I renamed the extension) but unfortunately there is no way to protect tags (they look like this, I added extra space so that the be displayed correctly)
{4}{5 & g t ; None & l t ; 5}{6}
There will be a solution to this shortly using an OpenExchange application that creates a nice clean protected xliff for translation.
Good to know Paul; please give me a shout when it is available.
I am wondering if this app is already online.
Which app? This is all about functionality that’s built into Studio.
Hi Paul,
Any news on this front?
As the user above said, this function would be very helpful if available for XLIFF files as well.
Thanks for your constant support!
None yet I’m afraid. I know many of the filters are getting an overhaul for the next major release so we may see something in this area then. There was a small app developed that could help with this but the developer abandoned it unfortunately, so we have to wait until either another developer does it, or it becomes part of the core product. I have a feeling the latter may be faster.
Hi Paul, I’m working with Studio 2017 and encounter this issue as well (with sdlxliff-files). Has any progress been done in the meantime?
Hi Caroline, this is a very different problem with sdlxliff files as these are already prepared. However, you can use the cleanup tasks batch task from the appstore.
Thanks for the info, Paul!
Fortunately, I could find a workaround for this issue.
1) Using a text editor, replace “<" with "|” with “>|” in the .xliff file.
2) After saving the modified .xliff, import it in Trados. All the tags at the beginning and the end of a segment will be visualized preceeded or followed by a |, which “fooled” Trados.
3) To get rid of the | after creating the .sdlxliff for the Trados project,
use the “Replace” function in SDLXLIFF Toolkit.
*Please note that no character will be found if the .sdlxliff bilingual structure is not created,
so at least pre-translate the file before performing step 3, or either translate even one segment of it.
*The | character can be replaced with what you prefer.
I suggest to use a character that is not included in your source text,
so that you can get rid of it easily during step 3, without damaging your source text.
I hope this can be helpful for someone, as it took about 24 hours for me to find this “exploit”.
Peace!
If you have a number of tags, how do you represent these in Studio’s regex?
Well… I guess if the dots are all squashed up as they get when you type an elipse in Excel or Word then use a rule like this (just copy and paste from excel or word straight into the placeholder space):
…
But if they are not then this I guess:
.{3}
Both work for me depending on how the elipse is put together.
HI Paul,
Following your instructions I used the start and end tags “{” and “}” which did the trick. However, when translating, the tags appear like this in target segment http://imageshack.com/a/img839/2795/9tbh.png when using Microsoft MT. I wonder whether there is a way to avoid that.
For the time being I am using a “low-tech” way: Paste Excel file to Word, apply internal style to tags, import to Studio. That way I have no issues with MT and tags getting messed up.
I’m trying to use these settings (the three catch all ones) for a new xml file type to handle embedded html. I seem to get an error everytime I prepare a file (object not set to an instance…) but it goes away when I restart SDL or go to a different project then back again – are there limitations to these regex?
Don’t forget that regex is designed to suite the circumstances. For most excel files with embedded html these rules are going to be good enough… for most but not as a rule set in stone for everything. You need to make sure you create rules to suit the content of the file you have, especially if you have an XML as opposed to Excel which is quite likely to require correct handling. Send me the xml file if you can and I’ll take a quick look – pfilkin@sdl.com.
Hi Paul, I have been trying to add a rule (placeholder) for a line break which can be either represented as or in HTML. This is in my Excel file type. Somehow, Trados doesn’t like this and sends me an error message at the time of preparing the file saying that the file is missing tag pairs. Do you know where that would be coming from and if there is a work-around for that type of tags?
Hi Sarah, I can’t see the tags you tried to demonstrate… maybe you can drop me an email and I’ll take a look?
See your message above: “There will be a solution to this shortly using an OpenExchange application that creates a nice clean protected xliff for translation.:”
Hi Paul, I’ve been trying to find a way to translate HTML text copied from website back-offices (CMS) and pasted into Excel files, because of the embedded content feature. Although this works for < > and {} tags, I’m stuck on HTML specials such as “&”, which should ideally be converted as in the Convert Entities feature for XML files. Do you know of a simple way to include this in the Excel embedded content feature? Or any other ideal way to translate such HTML content from website content management systems?
Hi, for now you have to use a regex for this too. I’m hopeful we’ll be able to chain the html filter to the excel filter in a future release and this will make it easier. But for now you need to add a rule… maybe something like this:
&.*?;
You could even create a specific set of different rules that were less general so you could go to the advanced settings and add the actual text you would see inside the tag which might make it a little better for the translator.
Thanks Paul. That’s what I thought, or was afraid of as it’s a bit annoying to see accented characters as tags inside words. I’ll try the advanced settings. Thanks. Lieven
Hi again, When adding e.g. “&” as a placeholder and ticking “Tag represents the text: &” in Advanced, should this not convert the tag into “&” instead of showing the tag? Or what this option do exactly? Or am I forgetting something? Many thanks, Lieven
Hi Lieven, well I may have given you a bum steer. I’m pretty sure this is how it should work, but I see the problem you may have come up against. I just tested this and don’t see the intended display… I just get the very entity I wanted to hide. I have reported this, but didn’t want you wasting more time on it until I hear back next week. Might be a bug.
Hi Paul, This is an interesting and informative article, thank you once again for sharing your expertise!
I handle these type of files occasionally, which contain a lot of formatting tags like as you described. However, the client (or the agency I should say) always converts these Excel files to itd files. Does this mean there will be no way for me to tweak the settings and hide these tags in the itd file? I looked at the SDL Edit under File Types and did not see the “Embedded content” option.
Hi Chun-yi, correct. Unfortunately if the file has been converted to ITD already then you can’t do this because there is currently no embedded content processor for this format.
Thank you for confirming this. Too bad that my client still uses SDLX. I can’t work with a CAT tool that does not have the filter function. So I will not bug you guys at SDL to add this embedded content functionality to the itd file type–this is legacy and we need to move on:)
This is a great resource. I might be a bit late here, but I have an Excel sheet which contains XML, and while I can handle most of the content, how can I get Trados to protect the XML declaration? (). Your help is appreciated!
I guess you could convert the whole thing to a tag? So if the declaration was this:
<?xml version=”1.0″ encoding=”UTF-8″?>
You could add a regex for the entire thing something like this:
<?.*??>
I think that would probably work.
That works perfectly! Thank you so much for your quick response.
Hey Paul
Awesome post. Thanks a lot. I’ve extended your post a bit:
http://remy.supertext.ch/2014/08/translate-excel-files-with-embedded-html-content-in-sdl-trados-studio/
But I’m are struggling a bit with the alt tag. You example only works if there are no other attributes inside the img tag. As soon as there are src, style, class or anything else in a different sequence it falls apart, Unfortunately, I’ve tried , but either it does not segment it correctly or I get an Unmatched tag pair error. Since you seem to be the Regex-King maybe you have a better idea?
Hey Remy… I’d hardly say regex king… I’m more like a learner trying to share the things I’ve learned along the way!
I think handling embedded code in excel is great for simple cases. More complex scenarios really should not be in Excel in the first place, but we do see them. So I think if it was practical I would remove the heavily scripted segments and handle with the html filter, then put them back. If it’s not practical then regex is the way to go, but how you handle it will depend on the content of the file and the sort of things you want to extract. The expressions are probably going to become quite complex and fraught with the likelihood of errors from unmatched tag pairs as you have found out. This is just because the expressions have to become more specific to avoid this happening.
The best approach is coming (not sure when we will see this yet) and that will be to have the ability to use the html filter inside the excel filetype for embedded content, exactly as we have done for the xml filetype.
Handling HTML in Excel the same way as in XML would be awesome.
I agree with you that Excel is not the best format, but not that I can control this. Sharepoint for example does this.
Anyway, was just hoping that you might have a solution for the img alt tags, but no worries. We can work around that.
In anycase, I think my blog post might help a few people.
Nope… just getting more detailed with the regex as you have done is the only way right now. Great article though, thank you for sharing the link. Here it is again!
Translating Excel files with embedded HTML content in SDL Trados Studio
Hey Paul, different issue today. It seems that all tags that I define as Placeholder are not separating segments. Even if I choose “Exclude” in the Segmentation Hints under Advanced Properties.
Regex: |s+[^>]*/>) for a
Anything else I have to set?
The online help specifies that the “Exclude” option will use the Tag Pattern to segment the text WHERE POSSIBLE,
and Excel is the file format where this is unfortunately not possible:
http://producthelp.sdl.com/sdl_trados_studio_2014/client_en/Configuring_Legacy_Embedded_Content_Processors.htm
This is correct Frank, but perhaps you can do this via segmentation rules in the TM instead?
Frank & Paul, thanks for the feedback. Not sure if I understand your point. This works fine for Tag Pairs it seems. Just for placeholders it does not.
In this case… as I wasn’t aware of this difference which sounds like a bug… why not create a tag pair instead? So for example, if the placeholder was <br> then use opening and closing tags like this:
<b(?=r>)
(?<=<b)r>
That seems to do the trick for me.
Great idea. The tag recognition works, but I get “the document cannot be processed since it contains unexpected contents.” as soon as I change the tag to “Exclude” in the Segmentation hint dropdown. Which was kinda the idea of this whole thing 🙂
Perhaps you’ve got some overlap with your expressions? Can you email me your file and then I don’t have to guess? The regex solution is quite handy, but having the ability to use a proper html filter inside Excel will be better!
Hi Paul, I am missing the “Like” button! This is so cool! Thanks
Great article and great help…however…I’ve got this :
{DOMAIN}/accounts/activate.php?key={MD5_HASH}
My embedded content rules do get out the but not the placeholders in between, while the whole thing should not be translated…any idea on how I should do this?
And now with everything written down :
{DOMAIN}/accounts/activate.php?key={MD5_HASH}
Hi Arjen, maybe review this article and post again… it’s a wordpress limitation and you need to use entities for your example in the post :
Hi Paul, hope you can help me.
My Excel file has cells like this:
<strong>text1 to be translated</strong><br/>
text2 to be translated<br/>
Between > and text2 there is a soft return.
How can I let Trados Studio 2014 recognize tags and segmentate after the soft return? I can only make one of these two things.
With segmentation rules I can correctly segmentate, but in that case tags are always hidden (I need to see tags in the editor).
Without segmentation rules I can correctly manage tags, but the cell is not split in two segments, and I need it.
Thank you in advance!
Diego
Hi, why do you need to see these tags? It looks as though they are external to the text in your example. If you want them to be visible you need to make them inline. Alternatively show All Content with the display filter and you’ll probably see them there too.
How to solve entities in segments like this then. Any ideas?
Termoblocket har ett rostfritt rör vilket minskar kalkproblem (det är dock fortfarande viktigt att avkalka maskinen).
• Hölje:
Formpressad aluminium
• Vikt:
7 kg
• Vattentank:
Hi Andreas, you need to escape reserved chars in comments for wordpress. I think this is what you meant:
Termoblocket har ett rostfritt rör vilket minskar kalkproblem (det är dock fortfarande viktigt att avkalka maskinen).
• Hölje:
Formpressad aluminium
• Vikt:
7 kg
• Vattentank:
Easy enough to handle with regex… maybe something like this would work based on your example text?
&.+?;
This worked an absolute treat – thank you so much. Saved me hours of head scratching!
i am having a problem cleaning the Excel file once it’s been translated. It’s all gone fine until Studio 14 creates the target file and then I get an error that says “The target translation cannot be created because a mismatch with the source document has been detected”. I have got the translation in the TM so I’ve removed the file and started again but the same problem exists. Are you able to shed any light on this? I haven’t moved or renamed anything. Thanks Michelle
Most likely the temp file has been removed before Studio finished using it. Perhaps you have some defrag tool, or clean up tool of some osrt running in the background that wiped the temp director while you were working? Something like that perhaps?
Try opening the excel file again from scratch using the single document workflow and then pre-translate it with your TM.
Thanks very much, that worked perfectly. Really appreciate your speedy reply.
If you have a number of expressions, should they be caught by your catch-all regex expression?
and I’ve just realised that this is more or less the same question as I asked in February last year. Please note that the ellipse is just to represent different types of text that might appear in the expression and doesn’t itself appear in the expression.
The tag pair might therefore be <a href=”[RelevantText]”> </a>
The catchall I provided might not pick this up as it contains an attribute which you might also want to translate. So create a specific rule for this one or create a different catchall… all depends on what you have and what you want extracted. Sometimes you might want the [RelevantText] as translatable text and sometimes you might not… so catchalls require careful use.
Hi again. I have set up the catch-all tag pair <[a-z][a-z0-9]*[^]*> </[a-z][a-z0-9]*[^]*> for an xlsx file as you described in the article but it seems to have converted them all into what look like placeable tags (i.e. the rectangles, each with its own Tag ID no.) rather than as tag pairs.
I am concerned that this will be rather confusing for our translators and that they may end up messing up the order.
I am using Studio 2014. Have I made an error? Is this a bug or a feature?
My settings:
Tag Type: Tag Pair
Start Tag: <[a-z][a-z0-9]*[^]*>
End Tag: </[a-z][a-z0-9]*[^]*>
Ignore case left unchecked.
Translate: Translatable
Formatting: left untouched
Advanced…: left untouched
Hi Malcolm, there is no way of knowing without seeing your file. The catch-all is not necessarily a real catch-all… it’s more of a catch-most-of-them 😉 If you send me some samples in an excel file of what you are faced with I’d be hapy to take a look?
Hi Paul.
I’m not quite sure how to send you a file but the tag pairs concerned include ul /ul, li /li, b /b, ol /ol and the previously mentioned a=href etc.
It does occur to me that by using this “catch-most-of-them”, it doesn’t give Studio any information as to which end tag goes with which start tag and this may explain my issue. It looks as though I may have to list them out separately after all to do a proper job.
Most likely… it would be better if we could use the html filter inside thexml but this will only be part of a future solution. You might still get away with simplifying the riles a little with a bit of smart regex, but listing them all will be easy and probably faster.
When I tried to use very very complex tag pair, I often ran into the error “Problem during writing internal tags! Check the definitions of your internal tags.”
A work-around I used a few times lately but which works only if your Excel files do not contain any graphics or embedded objects:
1. Convert the XLS files to a format called “XML spreadsheet 2003 (*.xml)”.
2. Define XML file type settings containing an XPATH-based parser rule like this (if column no. 2 is to be translated):
“//Row/Cell[position() = 2]/Data”
You may need to remove the default namespace declaration during translation (xmlns=”urn:schemas-microsoft-com:office:spreadsheet”) and re-insert it afterwards.
I’ve done this one too… and then tried to create a stylesheet so I had a sensible preview while working… but having problems with the stylesheet and this type of xml.
Hi, we sometimes convert Excel files into XML by using an XML map template to create a custom XML map based on the Excel file. We then add this XML map to the Excel file, and map the elements. Finally, we just need to export the Excel files into XML data files. The benefit is that you can specify XML elements in the Excel file and then adapt the parser settings to indicate which of those elements contain HTML embedding. The instructions are a bit too long to add them here, but if anyone is interested, I’ll be happy to send them, or I can send them to Paul… Although this may sound “complicated”, this has proven to be quite a straight-forward and easy solution for us. Best, Lieven
Hi Malcolm, I’ve just posted a reply to another comment in this post. We use XML maps before exporting XSLX to XML. We can then use the Embedded option in Studio for specific columns/elements in the Excel file. Let me know if you would like detailed instructions on this method. Best, Lieven
Hi Lieven. If you think your method would help me, I’m interested but am not sure how you can send the instructions to me, as I’m not particularly willing to expose my email address on a public forum. Is there a Private Message system here?
Is your method essentially the one shown here: http://www.excel-easy.com/examples/xml.html
You could both use the SDL Community… it’s free and it has a private message facility. It’s also a more sensible place to ask technical questions because more people can see it and it’s geared for sharing screenshots, threading conversations etc.
Hi Malcolm, The method is indeed the one you mention in your last reply.
I’m in the SDL Community as Lieven Lannoo (AKIRA Translations). Drop me a private message there and I’ll send you the detailed instructions on how to set up the Studio project for the XML file you create using those instructions.
Hi Paul,
I’ve been trying to protect some tags in an xlsx using the method in this article, but it doesn’t seem to work. I’m using 2015 and I’d like to know if there is anything else I need to do, because what I see in the editor is exactly the same as it was before using the rules in the Options pane.
Assuming your rules are correct my first thought would be are you using Project Settings or File -> Options to make the changes? You should be using File -> Options and re-parsing the file each time. If that doesnlt help I’d need to see an example… but I’m on leave right now so may not be quick!
Thank you for the answer, Paul… I’d been trying to figure this one out since I first learned about RegEx. It never occurred to me that I should re-parse the files, so I did everything but that 🙂 Also, I always believed that there the UI should differentiate somehow between these Options. Maybe by using a different term altogether to avoid any confusion…
I used the SDL Community and received my answer from Jerzy Czopik, so my problem is finally solved.
Is it possible to do something similar with the same problem in Word files?
No… but you can handle word files a different way. Regex for Microsoft Word.
Hi Paul,
I’m late to the party, but nevertheless many thanks for sharing this information.
I currently am dealing with an Excel file with embedded HTML. Your post has helped me much (cut about 10k words from the wordcount!), but there’s some stuff I’m still struggling with.
One of these is the placeholders. I have segments where the placeholders run further than “{9}”, i.e. “{10}”, “{11}” and so on. I am far from a regex buff, so I wonder how I can catch that in the regex for placeholders?
Another more pressing issue is the content of CSS sections, specifically internal style sheets (example here). The style tags at the beginning and end are recognised with the catch-all regex that you gave, but I’m stuck with everything in between, like in my situation:
Do you (or anyone else) have some pointers as to how I can also include this in a placeholder/tag regex, so it’s protected and not counted as translatable text?
Hi Matthijs, a good place to ask these questions is here, Regex and XPath Forum in the SDL Community.
On the numbers, try {d+}
On the rest, maybe try this {{.*?}}
Better to share a proper example in the forum where it’s easier to help and share ideas.
Regards
Paul
Hi Paul,
Thanks for your reply. The suggestion for the placeholders works. For the CSS bit, I’ve indeed posted a question on the Regex and XPath Forum. I hope someone there can help me out.
Regards,
Matthijs
Hi Matthijs. In these cases, we create an XML map with elements which we then link to the columns in the Excel file (using the Developer tab in Excel). When this is done (doesn’t take long), we export the Excel sheet (not the workbook, this works per sheet) to XML. In Studio, we create specific file type settings so that we can indicate which elements contain HTML tags and activate “embedded content > HTML 5” for these elements. So there’s no need to set placeholders and tag pairs, Studio will automatically recognize all HTML tags and convert them accordingly. Afterwards you just need to import the translated XML file in the Excel file (using the Developer tab).
We have detailed instructions for this procedure. Let me know if you are interested and I’ll send them to you (too long to post them here…).
Best regards,
Lieven
Hi Lieven,
After toying around a little with Paul’s suggestions (also for dealing with the internal style sheet stuff) I notice things get terribly complicated. Segmentation rules cut up the segments with the CSS code before we even get to the matter of dealing with the code. This leaves me with a lot of segments that basically are garbage, incomplete snippets of code. Dealing with this in the Excel format is not quite as straightforward as I first thought.
So with apologies to Paul, I’d like to try Lieven’s procedure for handling this, hoping that the code gets dealt with before Studio considers segmenting the strings. I’ll contact Lieven through the SDL community.
Cheers,
Matthijs
Yep… dealing with overlap can be tricky as the rules get more complex.
Dear Paul,
thank you for this great article. I would still have a question. Is there a simple or similar way to change “written tags” (such as , etc.) directly in SDLXLIFF files? I am receiving prepared project packages from the client but all tags are written directly in the text.
When the project’s volume is higher, it is OK to export XLS file and then create new project with XLS filetype (thanks again for your article), but in low volume projects it would simply pay off and would be very helpful if there was a way to change the tags directly in the SDLXLIFF files.
Is there anything I could do with that?
Thank you very much in advance.
With kind regards,
Jan
Hi Jan, I can’t see what you have posted here… you need to escape code for it to show. Perhaps you’ll be better off asking this question in the SDL Community?
You could also take a look at this article though… might be what you’re looking for. It’s a handy app on the appstore for tagging up sdlxliff files after they have already been prepared in a project.
Hi Paul, thank you for your replies. I will check the articles and SDL Community, too.
I was able to block most of the tags in excel, but is there a way to block
new line PHP code?
I guess you need \n
The backslash is a special character in regex so you need to escape it first.
Not quite sure what I am doing wrong, but it doesn’t seem to work in my Excel files. Problem is extremely simple: I only have the tags and but neither the regex rule nor the addition of the tag pair works in Studio. The tags and are still visible. Document structure is ‘cell’ as instructed. I even added these rules to both Excel 2000-2003 and Excel 2007-2013, just in case. Restarted Studio, but still no luck.
Maybe it’s a File -> Options versus Project Settings problem? Much better if you post your issue into the SDL Community where it’s easier for you to share the issue and easier for me and others to help you?
It seems the tags “” and “” aren’t showing in my message.
You need to write code in forums in a special way… see this post.
Thanks Paul. Anyway, in the excel files I need to translate the <text> and </text> should be removed. I will post this one in the SDL community.
Excellent… you figured it out! Just on that… you could use this as a placeholder:
(<|/|)text>
Or just create separate opening and closing tags depending on how it’s represented in the file. But good you go to the community it will far easier!
Hi Phil,
Thanks for this post! I used your tag definition rules when trying to prep an Excel file I received from a client and they work beautifully.
There remains one issue that I haven’t been able to solve myself: this client’s Excel file includes text strings enclosed in double brackets [[like this]]. Ideally, I’d want these strings to be locked in tags to prevent accidental translation or editing. I tried to create the following rule to catch these strings:
Tag Pair
Start tag: [[
End tag: ]]
Tag properties: Not translatable
However, after I implemented it, Trados started giving an error message ("Could not find a part of the path [filename]") when I tried to open any file to translate. Do you see what I’m doing wrong?
Thanks in advance for your help!
Hi Trudy, perhaps you just didn’t escape the closing tags? Should be like this:
Tag Pair
Start tag: [[
End tag: ]]
Tag properties: Not translatable
Or as a placeholder like this:
[[.+?]]
Hi Paul,
Escaping the closing tags gave me the same error (oddly enough, I don’t get these errors when tag properties are set to “translatable”; but that’s another story). Fortunately, using the placeholder rule worked perfectly — Thanks!