 A strange title, and a stranger image with a pair of zebras and a road, but in keeping with the current fascination with animals during the SDL Spring Roadshows I thought it was quite fitting. Nothing at all to do with the subject other than the Zebras may be duplicated and they are hovering a road to somewhere that looks cold!
A strange title, and a stranger image with a pair of zebras and a road, but in keeping with the current fascination with animals during the SDL Spring Roadshows I thought it was quite fitting. Nothing at all to do with the subject other than the Zebras may be duplicated and they are hovering a road to somewhere that looks cold!
The problem posed at the SDL Trados Roadshow in Helsinki by some very technical attendees, after the event was over, was about how to efficiently work on a Translation Memory (TM) so you could remove all the unnecessary duplicates.
The problem can be managed through Studio using the features available in the Translation Memory Maintenance View… but only if you know which segments are duplicates so you can find them. Not really helpful in this case where we actually want to be able to find the segments with same source but different target, and then remove the ones we don’t want with the aid of better QA features that are in the Studio Editor.
So the solution we came up with was to make use of two of the things we demonstrated during the events:
- SDLTmConvert – an OpenExchange application
- Frequently Occurring Units – a Project Management feature in Studio
To demonstrate how this works I took a TM from the DGT (just a sample of around 20k TUs), upgraded it to Studio and then using the SDLTmConvert application I converted it into XLIFF files. I don’t intend to work on these files directly so I just created 4 files with around 5000 TUs in each one.
I then created a project in Studio with these files and made sure that when I did this I applied the Frequently Occurring Units feature during the analysis:
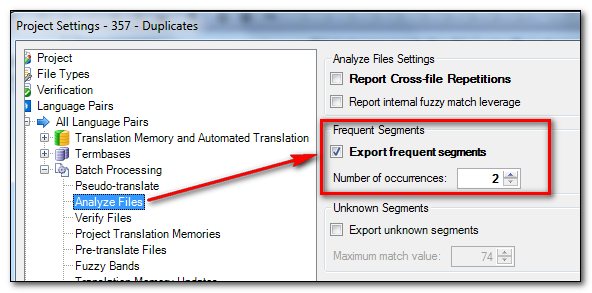
This is a very cool feature in Studio that allows you to create an SDLXLIFF file containing only the segments that occur more than the number of times you set… I selected 2. If you use this when you are working on a Project with some colleagues, but you don’t have a TM Server (SDL GroupShare) where you can actively share the same TM as you work, then by translating this file first and then pre-translating the Project you can ensure consistency for these segments. Then you share the pre-translated files out for translation… so pretty neat.
But for my purposes I’m interested in the TUs that occur more than once so I can find the duplicates in the TM and remove the ones I don’t want. So to do this I add the exported file (which is created in a folder called “Exports” in the Studio Project folder) to my Project as a translatable file and then open it with my TM attached. I now see things like this:
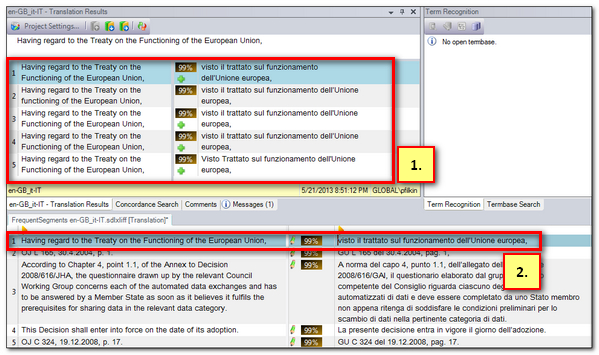
So 1. is my TM Results window and 2. is the active segment in my Frequently Occurring Units export. You can see I have 5 results, so I can now decide which ones I wish to keep and I can remove the rest one at a time, or by selecting more than one at a time, by right-clicking in the TM Results window and selecting “Delete Translation Unit”:
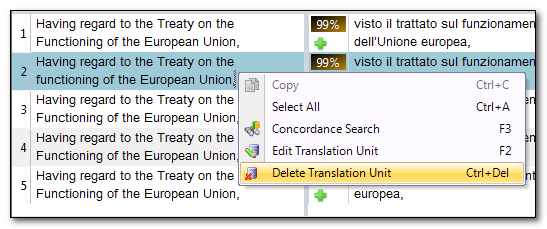
If I also ensure my TM is not set to update so I don’t mess with the context information that may be on the TU then I can work through the file confirming segments and then I know exactly where I got to and can easily return to the task on another day if there are so many TUs to correct.
I thought this was quite a neat solution using the Studio Platform to solve a problem that perhaps many people have come across and then resorted to other, perhaps more arduous means to resolve it.
Thanks Paul! However, wouldn’t the “Search for potential duplicates only” search type option in the TM maintenance view accomplish pretty much the same thing? It does also find translation units that have a different target.
Hi Tuomas, of course you are correct. Using the TM maintenance window does do a better job of actually finding all the duplicates in fact. The only difference being you have to work through the TM one page at a time, and you have no QA features to help you. But you are right and I should have clarified that better. Thank you…. I clarified that a little in the post.
What you are suggesting here Paul is post-processing while the “Update main translation memory” batch task still creates unnecessary duplicates. IMHO, checking hundreds of segments after updating TM or reviewing a document is simply not an option, because it simply forces the reviewer to do the job twice.
Hi Agenor, to be honest I have no idea what you are referring to. This process is simply an alternative to using the duplicate search in a Translation Memory by using the Frequently Occurring Units feature to generate a file of the duplicate segments after creating a Project based on XLIFF files that were created from the TM.
OK, let’s take it offline. Please check Jacek Mikrut’s e-mail for more details on the issue.
Cheers,
Agenor