 If this title sounds familiar to you it’s probably because I wrote an article three years ago on the SDL blog with the very same title. It’s such a good title (in my opinion ;-)) I decided to keep it and write the same article again, but refreshed and enhanced a little for SDL Trados Studio 2014.
If this title sounds familiar to you it’s probably because I wrote an article three years ago on the SDL blog with the very same title. It’s such a good title (in my opinion ;-)) I decided to keep it and write the same article again, but refreshed and enhanced a little for SDL Trados Studio 2014.
Something I only occasionally hear these days is “When I used Workbench or SDLX it was simple to create a quick analysis of my files. Now I have to create a Project in Studio and it takes so long to do the same thing.” I do think this is something you’re more likely to hear from experienced users of the older products because they initially find that getting a quick report out of Studio is a far more onerus process than it used to be. What they might not think of is how you can use the Projects concept to make this easy for you once you become just as experienced with the new tools.
The basic concept behind getting a quick and simple analysis report before you take on a job is that you create a Project that you only use for analysis and then you leave this permanently in the Projects View:

Once you’ve done this the process becomes quite simple. All you have to do is activate the Project by double clicking it whenever you want to analyse a file, or files, then drag and drop them onto the Files View. If you prefer you can also use the Add Files button from the File Actions group in the ribbon or Right-Click from the Files View window:
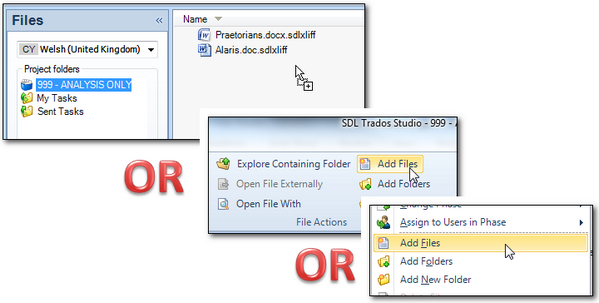
The one difference between these methods is that if you select Add Files in either of the latter methods they will always be treated as translatable files as long as they are recognised filetypes. If you drag and drop without changing to the source language first then you will be presented with an option:
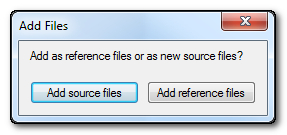
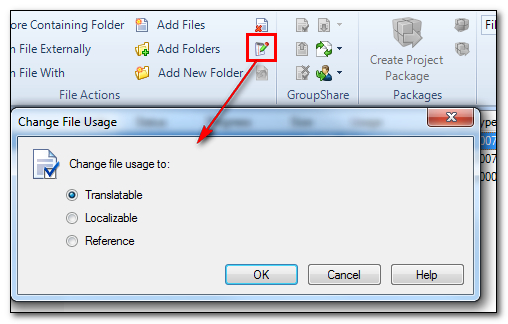
If you change to the source language then you won’t get this option and they will be added as translatable files. If you decide you want to change the purpose of a file after adding it then you can change this by selecting the files and then clicking on this icon in the ribbon:
In this example I’m just adding three files, and once they are in the list you can right click on a file (or folder), or select several files together using the ctrl key and choose the Analyze Only batch task, or select it from the Batch Task icon on the ribbon:
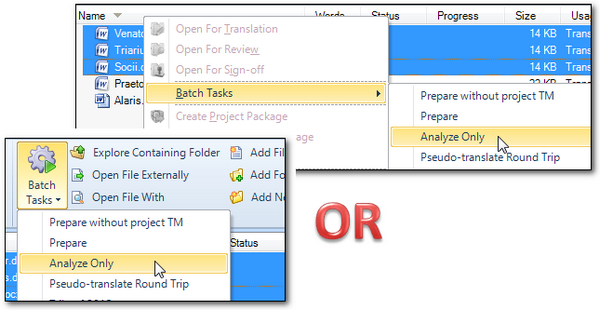
Once the task has completed you can select the Reports View and the reports at the top of the list will be the reports for this analysis. Note that the default Analyze Only task also produces a Translation Count report; if you have the Professional Edition you can create a custom task that only runs the analysis report:
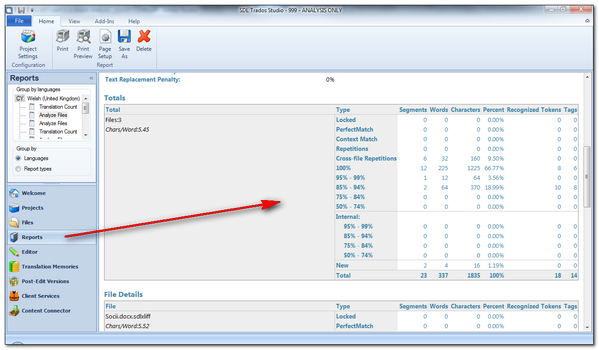
You can set the Project up to run without a Translation memory at all, or you can set as many Analysis projects up as you need all preconfigured with your usual Translation Memories and then the time it takes to run the analysis is as fast, if not faster than it was using Workbench or SDLX. A bigger advantage of Studio is that if you work with one source language and multiple target languages then you can analyse all the languages at the same time which is something you couldn’t do easily before and of course you can also use as many Translation Memories as you like… something else you could not do in Trados 2007.
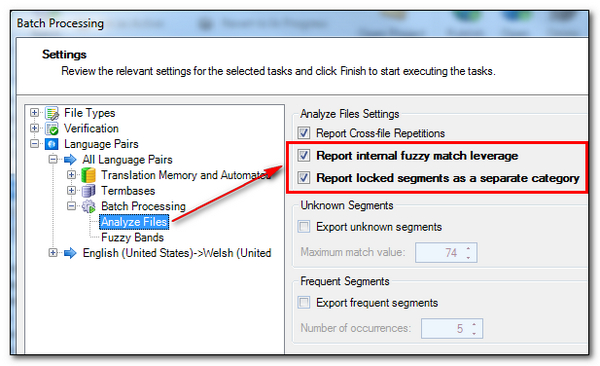
A quick note on carrying out the analysis without a Translation Memory. “Why would I do this at all?” you may ask. Many SDLX users made use of a feature that reported the internal repetitions. This feature allowed you to report on what benefits you would receive from translating based on the contents of the document you are working on rather than the Translation Memory. This allows a more realistic report on the effort required to translate and you can achieve this without a Translation Memory at all. In Studio we have an option called Report internal fuzzy match leverage which does the same thing and this can be activated under Batch Processing -> Analyze Files. The help guide in Studio covers this feature quite nicely, and of course you can still run with this option when using one or more Translation Memories as you see fit. In addition you can also lock segments that you don’t want to see included in the report and these can be reported as a separate item. This is found in the same location as the internal fuzzy match leverage:
I thought it would be handy to see the complete analysis process in one go in a video because it often takes longer to read an explanation of how to use things than it does to watch it, especially when I try to explain the various things you might come across as you go. Certainly I think this will show the process is pretty simple and certainly doesn’t take as long as you might think!
Finally, I just want to mention the OpenExchange. There are a number of applications available now that can use the analysis in Studio to make it easier for you to prepare reports for your customer, and there are a few that can be used to create an analysis without using Studio at all… and I’m sure there will be more as time goes by. Here’s a few examples that have been written to use the analysis in some way. I have linked to the OpenExchange pages and used the descriptions in these pages below:
SDL Studio InQuote : SDL Studio InQuote takes an analysis from any SDL Trados Studio Project, and creates a quote.
- The quote can be created in MS Word, MS Excel or copied to your clipboard.
- Rates can be added as simple word analysis, standard lines or grouped analysis.
- Client details can be saved in the app and assigned specific rates.
- Customize your own MS Word or MS Excel template.
- Localize the app yourself in your chosen language.
Post-Edit Compare : Post-Edit Compare is a tool designed to report translation modifications during the post-edit phases of a translation workflow.
The tool works by comparing two versions of the same SDLXLIFF file (before and after changes were applied); the files with changes are highlighted and all modifications are included in a comparison report.
The comparison report is formatted in a way that simplifies the understanding of what changes were applied from one version of the file to the other, along with a full break down of the modifications and related cost analysis.
SDL Trados Studio – Export Analysis Reports: SDL Trados Studio – Export Analysis Reports allows the user to export the SDL Trados Studio Analysis report into the CSV format.
goAnalyze: goAnalyze is a Trados 2009/2011 add-on which allows you to perform an analysis of several or even zipped files without having to open them in Trados Studio.
Before running the first analysis, you create profiles in the user interface of goAnalyze. These profiles consist of the language combination, the translation memories to be used plus optional analysis settings and even costing figures.
Free Online CAT Weighting Tool : Free Online CAT Weighting Tool used to upload the SDL Trados Studio analysis file from your computer to calculate the cost to quote.
So keep an eye on the OpenExchange because you never know who will create a tool to simplify the analysis further or use it in some clever way for added value. I don’t think it’s difficult to use Studio for this, and I hope this article clarifies it, but there’s always room for more innovation!
Thank you for helpful articles and guides!
I’m FL french-albanian translator and occasionally from clients I receive only SDL Trados analyze file as xml file (for info about upcoming project and accordingly I prepare bid and planing my time). When I import xml analyze report into Excel, result is confusing tabele. I’m wondering if is possible to import analyze xml report into excel with some more clear results and useful for preparing a bid. I tried to ask client to export analyze report to xls or html, but apparently it’s bothering for them 🙁 (Online CAT Weighting Tool is not best option for me, because I’m not online all the time)
KR,
Anamarija
Hi Anamarija, do you receive the full project package too? If so then you just open that and you will be able to read the analysis in Studio. I’ve never tried to use the XML in Excel outside of Studio but I imagine it would be possible with a little work… I’m just struggling with why this should even be necessary? Seems a little odd, especially when it’s not hard to save the analysis as excel in the first place.
Hi Paul,
Thank you for a quick replay.
It is odd – I agree with you :), but scenariom is: client sends to me a xml file with analysis, and after I confirm thw job (WC and due date), he sends me a package 🙂
So basically, if all you want is a simple analysis, the answer is: no dice. It’s a real pain to go through all this rigmarole for single documents if all the customer wants is a quote. I wish there was just some simple option to analyse a document without have to set up a project every time. Your solution is a pretty good workaround, I guess. But I’m going to try this GoAnalyze tool and see if it’s any good.
Hi,
Why do I get a set of figures when I run the analysis of a file against an empty TM (with internal analysis unchecked in Settings), and a different one when I check internal analysis and run the Analysis? Shouldn’t they be the same?
Thanks
Hi Marty, if the difference is the internal analysis then no they should not be the same. The standard analysis is based on the contents of your TM. So if the TM is empty they should probably be all no match. The internal analysis attempts to forecast the leverage based on you translating the file, so you get some idea of the benefits of using a TM as you work.
Hello Paul, these are the steps I followed:
-Created a new project with a pdf to translate an empty TM,. Then, batch anlaysis (unchecked show internal uanalysis). I do get matches, as follows (word counts):
678 repetitions,
72:100%,
2:95-99%,
New 369,
Total 1121
As I say, the TM is newly created and empty. My first issue is, aren’t repetitions and 100% the same thing here?.
I then go to Settings, check internal analysis, batch analyze the file, and I get these:
651 Repetitions
72:100%
2: 95-99%
Internal:
95-99: 28
85-94: 39
75-84: 45
50-74; 22
New 262
Total: 1121
I can’t make sense of ithis situation, can you help me?
Sorry about my poor explanations. I was in a rush! I found that if the TM you create for the project has ‘lookup’ enabled, the top fuzzy bands (with matches against the TM) will have some segment matches. If you disable lookup, nothing will appear there. Why is that? Also, checking or unchecking the ‘lookup’ option and checking or unchecking the ‘report internal fuzzy match leverage’ results in different repetition counts. Thanks for your help
There aren’t any tickets in the KB related to the issue I described above and I don’t have the Premium Software Maintenance Agreement. The analysis tool is not so simple after all! Why does SDL Trados Studio 2014 returns fuzzy matches when you analyze a text against an empty TM? I’m not talking about internal analysis. Quoting Paul: “So if the TM is empty they should probably be all no match.” Eppur si muove…
Hi,
I have a question. Some projects can be very big, including dozens of files. It could turn out that the files can actually be seperated into sets. For example, the group analysis of 50 files show 30% match, nice. But in reality there are 5 sets of 10 files within which the files are 80% similar (figures are artificial). Is there a way a figure that out without having to read them manually? And the second, what if not all of the files are words but there are for example excels as well? Thanks!
Hi, the only way to figure that out is to run the analysis and look at the report that is generated. It makes no difference what the files are, they can all be analysed together.
So the report will contain the match values between all document pairs?
The report is not comparing documents. It compares the segments in each document to what’s in your TM. If you run an “internal” analysis which is not turned on by default then this will compare the segments to what will eventually be in your TM if you translated the files; so in effect showing you the leverage you could get as you translated. This is pretty unscientific as it also depends on the order in which you take the files, so the internal analysis is a guide only… or should I say more of a guide than the standard analysis is.
I understand. Then aside Studio, do you perhaps know of some app that can e.g. analyze multiple word documents?
All CAT tools can analyse multiple Word documents. What specifically do you want to see? I must be misunderstanding your requirement.
Say for example that there are 9 word documents. I would like to see a table of similiarities between all of the pairs like this:
1 2 3 4 5 6 7 8 9
2 100 n n n n n n n
3 n 100
4 100
5 10 80 75 100 15 6 85 12
6
7
8
9
So, the numbers 1-9 are word documents. The numbers 100 are obviously 100%matches between identical documents (1-1, 2-2…). n is the match between all other pairs and it is these n’s that I’m interested in. For example, look at the row 5. It is immediately visible that words 5, 3, 4 and 8 are very similar, while the other words are not similiar to 5. Similiar meaning that the numbers represent the similiarity of content. It isn’t important is it characters, segments, what is important to get the general idea how the words relate to oneanother.
So you would basically need 36 different sets of analysis to cover each possible pair. You could do this with a CAT but you would have to do this manually. So like this:
1. Open doc #1, copy source to target and update into TM #1
2. Open doc #2, copy source to target and update into TM #2
3. etc… to doc #9 and TM #9
4. Open doc #2 – doc #9 and analyse all 8 docs against TM #1
5. Open doc #1, doc #3 – doc #9 and analyse all 8 docs against TM #2
6. etc…
You would have some repetition of analysis here as this would give you 72 reports, but could ignore the duplicates. So 9 sets of analysis would get you what you wanted and then you’d have to do a manual interpretation of the changes.
Maybe there is a cleverer way to handle this and it’ll be interesting to see if anyone chips in, but it’s not really what a CAT is designed for. You have asked for an analysis to compare files with each other as opposed to what a CAT is designed to do which is tell you how much of a document you have translated before so you can establish the effort.
What is the purpose of an exercise like this?
Oftentimes there are subsets of similar documents within the whole set due for translation. If you share the work with someone, it would make sense to give to one person all of the files within a single subset. That way he/she can use virtual merge for auto-propagation or, if virtual merge is not used, simply build up on his/her TM and, in the end, translate faster. The purpose is to avoid the situation where the same person translates documents that are not from the same subset. Obviously you could use shared memories etc., but it is far more convinient to split the documents properly. I am curios is there a way to do this without the need to manually examine the documents (which can e.g. be very large).
I’m not aware of one, but it seems to me it would an excellent tool/feature that recommended the most appropriate translation order before you started.
One possible alternative way to handle this is to use the “Export frequently occurring segments” feature. This can create a separate sdlxliff that contains only segments that repeat themselves more than a defined number of times in the project. You then translate this first, and then use the TM created from this to pre-translate the full Project. This way it won’t matter what the order is because all the repetitions are handled before you start. You will lose context this way, but for the right type of source material this might be the answer.
I know of that option, but losing the context is too big of a thing most of the time. Oh well. Thanks a lot for your help, if you stumble upon on a solution, please let me know.
The formatting is messed up but hopefully you understand what I mean 🙂
Question regarding exporting frequents:
If I set no of occurrences to 2, then I would expect an analysis of the exported frequents to show the wordcount total as the same total wordcount as the repetition total from my original file. Or am I misunderstanding? This is not happening in my file and I dont know why.
Sounds logical… would have to make some time to play with that one!
EDIT: Actually if you think about it then it won’t. The export takes one segment of each repetition, not all the repetitions. This is so you can translate them once then update your TM and pre-translate the original files. So the count should not be anything like the original.
I am sorry if my question is silly, but my Batch tasks are always empty (I have Trados Freelance Studio 2014), so I cannot create any report. Consequently, there is nothing in the Reports section. No matter what project I choose, Batch tasks are always empty. Please let me know what should be done, maybe I need to download some additional software? Thanks.
Try pressing Ctrl+S to save the project. Most likely you opened the file for translation and didn’t save/create the project. Batch tasks are only available for projects.
The projects are saved. This problem goes on for a month already if not longer. Maybe it is some software bug and I should reinstall Trados?
I don’t think it’s a software issue. Did you finalise the project maybe? Try reverting to sdlxliff by right-clicking on the project.
Yes, I did finalize the project so when I reverted it to “in progress”, I could use the Batch tasks. Thank you for help)))
Paul, this question is only slight related to this thread: sometimes, when I try to save a report (Reports > Analyze Files, right click and “Save As”), I don’t get the option to save the report in .xlsx format, but only htm/mht/xml. Have you run into this? It feels like a random behavior, but I bet there’s some setting that is causing it.
Hi Micaela, I haven’t seen this and I can’t find any reference to the problem in the knowledgebase either. Presumably you do have excel installed and you’re not using open office or something like that? Perhaps you can try asking this in the SDL Community where someone else might have come across it?
I’ll check with the SDL Community. (I work with Microsoft Office 365, but that should not make a difference, I’d think). Thanks for the prompt response!
Using Office 365 might make a difference… there are some features missing in Studio when you use the click to run installer that comes with Office 365 because this doesn’t install the full version of Office that comes when you use the msi installer.
Got it! Great to know about Office 365. I will look at making the switch.
Thanks for this excellent explication: I am myself a nwebie and I use SDL Trados 2011.
I have to give a quote for a new project and there is a lot of repetitions in the text (repeated sentences / paragraphs).
I want to take them in accout but I don t find the relevant statistics.
How can I access to them with Trados ?
Thanks in advance
Hi, all you have to do is run an analysis and then look in the Reports View in the navigation pane on the left. The analysis will be in there and you can save it to Excel if you wish.
Thank you very much Paul, I ll try to do it ASAP !
Hello Paul,
I am trying to do an analysis with no TM. In your video I cannot see if you remove the TM or not.
I create a project and go through the wizard: set any language, upload files, on the translation memory step I do not set any TM (but under “Language Resources” I specify the “template” that I already have prepared for all languages I work with, which is necesary if there is no TM available), etc… finish.
I get an error message (No translation memories found to look up translation for language pair GE>EN, which is the language I had to set on the wizard. For this purpose I had set the Language Resources template, which has GE on it.
As I understand from your article, I can do analysis without TM. Or maybe you mean something different?
Thank you for your help.
Regards,
Miriam
Hi Miriam, I think I must have confused you here. In order to run an analysis you always have to have a TM. You cannot use the Language resource Template for this as this is used for quickly creating a TM with predefined settings. So in my video I used a Project that I had already created for only running an analysis. The project has a TM in it already. So all I have to do is drop my files into the project, select them and run the Analysis batch task.
Having said this I think you might find that the SDL Analyse app is going to be far easier to use. You can find the latest version we are testing right now in the SDL Community as we improved it a little.
Hi Paul, thank you for your quick answer. Then I will use an empty TM for documents of new clients.
Regarding the SDL Analyse app (0.73), I already installed it, but I receive this message “SDL Analyse service is not available, please make sure the service is running….”. I went to this troubleshoot page: https://community.sdl.com/solutions/language/translationproductivity/w/customer-experience/1311.sdl-analyse , but this is for an older version of the app. I must mention, that I still have sdl 2014 and 2015 installed on my computer. Do I need the 2017 version for this app? Thank you for your answer.
Yes… this is only for Studio 2017.
Thank you very much Paul. I installed Studio 2017 and the app works great now.
Let´s assume that we have a file to translate that contains repetitions but there is no translation memory, so we are looking at the number of repeated fragments within the file. Does the software include in the repeated fragment count the first instance of a repeated fragment (i.e., the one that you will have to translate from scratch).
For example, if you have the fragment “xxxxab”, which appears 3 times, although the repeat count is 3, one of those will have to be translated from scratch so it should not be counted as a repetition. Will the software then place 2 of those fragments in the repeated count and the other one in the “new fragment” count?
I hope that my question was not too confusing, many thanks
Mar