 I spent the weekend at my Mothers house the week before last and was digging around looking for photographs of myself when I was the same age as my son. I found a few… a few I wouldn’t share with anyone else but my son! What was I thinking with the baggy trousers and platform shoes…!
I spent the weekend at my Mothers house the week before last and was digging around looking for photographs of myself when I was the same age as my son. I found a few… a few I wouldn’t share with anyone else but my son! What was I thinking with the baggy trousers and platform shoes…!
I also found some old Army pictures including these two taken during my basic training, which did an excellent job of shaking me out of my baggy trousers and platform shoes! Also provided me with the most tenuous link yet into the translation environment because I wanted to write about clean and unclean files. I don’t know who came up with this terminology, but if I think about it, the description probably fits quite well. But the first time I heard it I’m sure something like these photos would have been closer to mind!
So lets define an unclean file first of all. In our world this would be a file that contained the source text and the target translation… so essentially what we call a bilingual file. In the olden days, not quite as old as my pictures, this would have been Bilingual DOC or TTX and today it’s more likely to be XLIFF. However, we still see questions being asked because a translator has been asked to provide the unclean file for their customer and they’re not sure how to do this. The task can become more confusing because technically an XLIFF is also an unclean file but this term generally refers to Bilingual DOC rather than XLIFF, and probably rather than TTX as well. This of course poses a problem if you have a modern translation environment because even if the tools you use are capable of creating an unclean file like this, the only real guarantee that the file will be suitable for your customer is if it is created using the same tools they are using. So this means you need to be translating the unclean file in the first place and not a clean, or monolingual file.
Contents
SDL Legit!
 I’m going to talk about Trados unclean files, and if you have just purchased Studio 2014 then you may not have a copy of SDL Trados Translators Workbench which did create what we think about when we refer to unclean files. But you do have the next best thing… maybe even a better thing! You have a free OpenExchange Application called SDL Legit!. This application allows you to convert files that were supported by SDL Trados 2007 into a fully segmented Bilingual DOC or a TTX (I’ll come back to that phrase “fully segmented” in a bit). It also allows you to use custom ini files when you do this, and you can also use a legacy translation memory to pre-translate the unclean file as much as possible before you start if you wish. But I’m just going to talk about how you go about the translation workflow if you need to provide an unclean file to your customer and they only gave you a clean file to start with.
I’m going to talk about Trados unclean files, and if you have just purchased Studio 2014 then you may not have a copy of SDL Trados Translators Workbench which did create what we think about when we refer to unclean files. But you do have the next best thing… maybe even a better thing! You have a free OpenExchange Application called SDL Legit!. This application allows you to convert files that were supported by SDL Trados 2007 into a fully segmented Bilingual DOC or a TTX (I’ll come back to that phrase “fully segmented” in a bit). It also allows you to use custom ini files when you do this, and you can also use a legacy translation memory to pre-translate the unclean file as much as possible before you start if you wish. But I’m just going to talk about how you go about the translation workflow if you need to provide an unclean file to your customer and they only gave you a clean file to start with.
Let’s start with a sketch… the basic workflow for most users will be something like this:
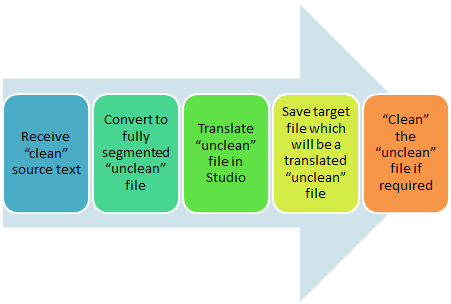
If we examine these parts it’s quite straight forward really.
Receive “clean” source text
This refers to the file you are provided by your client. For these purposes we are assuming that they have provided you with a monolingual source text. If the unclean file has to be a TTX then this file could be anything that is supported by SDL Trados 2007.
If it has to be a Bilingual DOC, (Bilingual RTF is not supported) then it can only be a DOC file. DOCX will convert to TTX by default.
Convert to fully segmented “unclean” file
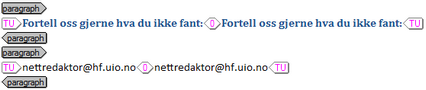
When the clean source file is converted to an unclean format you are presented with a new file that contains both the source and the target text. This process is normally carried out with a Translation Memory and any matches for the source segments are copied into the target part of the file. If there are no matches found then that segment will not have a corresponding target text and will be what is referred to as unsegmented. In practice it will look like this:
TTX
Unsegmented

Segmented
Bilingual DOC
Unsegmented
![]()
Segmented
![]()
Now, Studio can handle unsegmented unclean files because it will complete the segmentation on it’s own, using Studio segmentation rules. For simple text this won’t be a problem, but for some material, particularly if it’s heavily tagged, you may find that when you have completed the translation the differences in how Studio handles these tags might cause a problem for the old legacy Trados which your client won’t be too happy about.
When you used SDL Trados Translators Workbench to segment the files you had an option to “segment unknown sentences” and this always made sure that the files would be fully segmented even if there was no match in the translation memory. It did this by copying the source into the target. So in the examples above you can see that the segmented translation units have a zero match value separating the source from target, but they do have a source and target even if they are the same text.
SDL Legit! always fully segments the unclean files, whether you have a real translation memory to use or not, so you won’t be able to forget. There is another application on the OpenExchange called SDL TTXit!. This can only create bilingual TTX files and they are unsegmented. So in my opinion you are better off using SDL Legit! for a safer round trip of your files.
When you convert your files to Bilingual DOC you will find that you now have two files in your folder. One that has the same name as your original clean file with a DOC extension and one with a BAK extension. The DOC is the unclean file, and the BAK is a backup of your original clean file. So it is just the original DOC renamed as BAK.
When you convert to TTX the original clean file remains as it is and an additional file with the extension of TTX is created. This is your unclean file.
Translate “unclean” file in Studio
Once you have your unclean file, you open it in Studio and you will see something like this:
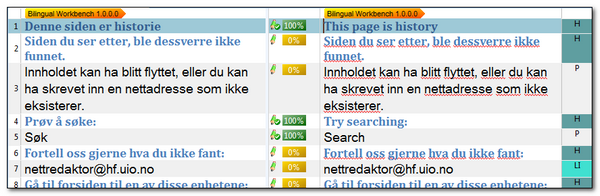
This is the unclean Bilingual DOC file in Studio. The 100% matches are segments that were translated during the conversion to an unclean file in SDL Legit! based on the contents of the translation memory I used. The 0% matches are untranslated and the source is just copied into the target. These are most likely the segments you need to translate.
The TTX will be similar although you start to see some of the differences between files and versions. So here the unsegmented sentences still have the source copied to target, but they are given an draft status. You can also see that segment #1 had a number in it that the Bilingual DOC file didn’t segment so it was ignored by the Studio filetype, whereas the TTX brought it in unsegmented and the Studio TTX filetype handled it with an untranslated status:
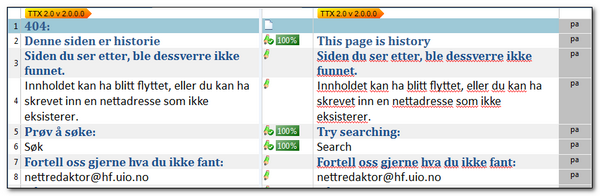
But in both cases you would simply translate the file.
Save target file which will be a translated “unclean” file
Once the translation is complete you save the target file from Studio. When you do this, depending on the original unclean file, you will have different options. So if the original was a TTX then you will see this:

You now have the opportunity to save the TRADOStag Document which is the fully translated TTX you wanted for your customer. Or, you can save the Original File Format which is the clean file you started with only now it contains the target text. So for TTX files you can save both the clean and the unclean file from Studio.
If the original unclean file was a Bilingual DOC then you won’t see this option. The target file will be the fully translated unclean file your customer wanted. Studio will not clean up this type of unclean file.
“Clean” the “unclean” file if required
If you need to provide a clean file as well as an unclean file, and you don’t have the legacy Trados tools then no problem… help is at hand with another free tool on the OpenExchange called tw4winClean. This tool will remove the segmentation mark up and leave you with a clean file as well as retaining the original unclean file, so you can still provide both files to your customer.
All that sounds complicated..!!
After writing all of that, and I could think of a host of other things I’d love to tell you, it certainly does sound a little complex. But it’s not really. So to demonstrate this in real time I prepared a short video just to show you the process from start to finish, and all without using the legacy SDL Trados 2007 at all.
A final note would be to direct you to this article where you can read a lot more about working without Trados – Life without Trados! And of course if you do have any questions or think I should have covered something else feel free to let me know in the comments.
I love those old Army pics 🙂
Thanks for the clear, systematic explanation and the peek at dealing with those archaic and often troublesome formats. It’s funny (or perhaps not) how embedded the terms “clean and unclean” files are with some people, so that they still can’t get their terms straight for Studio and other applications.
Thank you for this post Paul. Wish I had read your TTX it v. legit comment a couple of months ago!
An alternative way of explaining this is to start with the process – cleaning up – and explain it was an earlier way of describing the process of creating a target file from a bilingual, which literally involves removing something – the source text. The idea that removing something can be called cleaning is not too problematic I think. Then mention that the cleaning produces a clean file (target file) and so the filetype before cleaning was known as an unclean file. Which is nowadays called a bilingual file. .
Earlier bilingual file formats included ttx and bilingual docs so these are legacy bilingual file formats.
Perhaps also useful to point out that .
ttx is also known as TRADOStag Documents
bilingual doc is also known as SDL Trados Translators Workbench file
(this can be shown using the list of filetypes when using Translate Single Document).
You could also in another post put Revision into the workflow and then deal with the “some_file.ttx.sdlxliff” filetype – not sure if it would be called “bilingual bilingual”; “bilingual unclean” or “unclean blingual”!
The fact that to help with legacy issues you can open these filetypes as source files i.e. a source file can actually be “bilingual” can be a tricky concept to get across especially when saving them as bilingual which of course you have to do if you have reviewing in the workflow either through a project package or exporting for external review.
As Legit is an in-house SDL App, could you consider in a future version not using .bak to make a backup of the original source file, .given that the .bak extension has traditionally been used when cleaning up to make a backup of the bilingual file and this Legit use is a bit confusing to those used to this tradition.
f you have not yet covered tags and .ttx files that would be a useful post – I came unstuck badly with a large job involving .ttx files a couple of months ago, as I had not done a job with them for a long time and stupidly did not pseudo translate first and ended up losing a lot of time until I realised the problem was smart tags v compatibility tags.- this might be another useful post.
Which is also another way of saying those interested in more might want to click on Welcome -More Resources – SDL Migration Guide and read Chapter X on TTX and Bilingual Doc Files..
Hi Paul,
thank you for this post. I installed tw4winClean, but for some reason my file is still bilingual. I used for this Generetaed_doc could be that the reason, why did not change it?
My aim is to get doc file from XLIIF (which was a target), maybe you could help by this?
Thank you
Hi Anna, I think there may be a little confusion here, maybe by me!! tw4winclean is for cleaning a bilingual doc file. You cannot use it for anything else. So if the file did not originate as a doc file, and if it was not converted to a bilingual doc file by Trados 2007 (or earlier) or some other tool like Wordfast, then this tool is not what you need.
If you started with an XLIFF, and it sounds like this as your target is an XLIFF, then you cannot get a doc file from this tool.
But perhaps I’m misunderstanding what you mean?
Hi Paul,
thank you for reply. I am with you. I think I misunderstood function of tw4winclean.
This is how it was: I got to translate XLIFF file (my source. Sorry I said before it was target) and I used Trados 2011 for translation. Than I converted sdl xliif with SDL XLIIF Convertor and I got Generated_dox and than I wanted to use tw4winclean to get clean doc file. By this complicated way I just wanted to get Word file from my target file.
Could you tell me, if it possible at all to get target Word doc file, if source was a XLIIF file?
Hi Anna, thanks for clarifying. In this case the only way to get the “clean” target word document is to process the original XLIFF file in the same tool that was used to create the XLIFF. The SDLXLIFF Converter is just used to create a two column Word document for allowing a review of the source and target text without needing to use a CAT tool, and then import any changes back into Studio afterwards. You can’t use this to get at the original source file at all.
I hope that makes sense? Do you know how the original XLIFF you were provided was created?
Hi Paul, thanks for explanation. This original XLIIF was created with website translation tool. It delivers contet of website in XLIIF format or in CSV, no way unfortunately to have it in word document. So it looks like this is not possible at all.