 The debate over who’s right, and what’s the correct spelling… localization or localisation… will undoubtedly go on for a long time, unless you ask my Mother who knows the British are right of course! I always lean towards the British spelling, probably the result of my upbringing, and when asked I always take the British point of view.
The debate over who’s right, and what’s the correct spelling… localization or localisation… will undoubtedly go on for a long time, unless you ask my Mother who knows the British are right of course! I always lean towards the British spelling, probably the result of my upbringing, and when asked I always take the British point of view.
There are many Americanisms that have crept into our everyday speech, and if I’m really honest I use them too! If I’m even more honest I think I always used them and didn’t even know they were American English and not British English. The “z’s” are easy, but who gets cypher and cipher the wrong way around, disk and disc, gaol and jail or even meter and metre. No doubt there are those amongst us who would never get them wrong (my Mother would never get them wrong) but I think there are plenty of words like this that have become, dare I say it… interoperable! But what happens if you don’t want to get them wrong, and if you always want to stick to American English or British English? In our business this is often an important distinction, so with that introduction let’s take a quick look at how you could manage something like this using MultiTerm and Studio.
Forbidden terms
The concept of forbidden terms has been discussed quite a bit over the last few days in TW_Users, so I thought it might be a good idea to take some of the ideas some users shared with me around what would be useful to know when working with MultiTerm and tie it into the concept of Forbidden Terms. I’ll start here, which is really the end, because I think it helps to know where you want to get to when you are designing your termbase. This means you can convert the raw material you get from your client and make it more useful for a specific project by making sure the definition of your termbase suits your task at hand. So don’t just throw everything into one big mama of a termbase. This is still going to be useful of course and you can do this anyway, but maybe think about how you can use the information you have to improve the quality of your work and even work with multiple termbases.
So in this example I’m going to assume we’re working from Welsh to English, and I have two clients, one who always works into British English and one who works into American English. I want to make sure I never mix this up, and I could solve this by having two termbases, one for British and one for American. But if I did I’d have no need to write this article, and I’d also be maintaining a fair amount of duplication of effort as the terminology grew. So I’m going to work with a single termbase for both flavours.
The reason I started with the Forbidden Terms is because I want to be able to have Studio tell me when I use American English when I should have used British English, and vice versa. The feature in Studio that does this is called Forbidden Terms and it’s found in your Project, or Global Settings, under Verification -> Terminology Verifier:
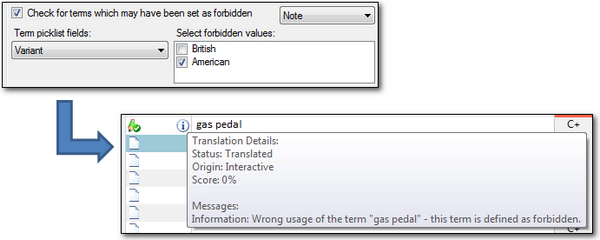
So the idea is that Studio will use the values you decide are Forbidden Terms and will notify you as you work if you use the wrong one. In the image above I used “gas pedal” instead of “accelerator” and because this American term is set as forbidden, and also set to flag this as a note rather than an error or warning, I get the little information symbol in the translation status column and the message telling me this is the incorrect use of the term.
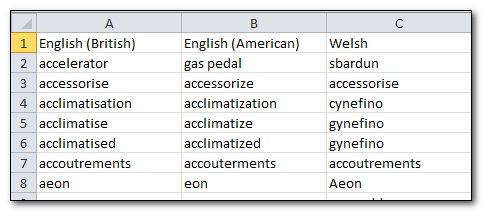
Now we know what a Forbidden Term is, let’s take a look at how we set all of this up. We’ll start with the raw data that we currently have in a spreadsheet… it looks like this with two columns for the English synonyms and one for the Welsh (all Google translated by the way… I hope it’s not too bad!):
Termbase Definition
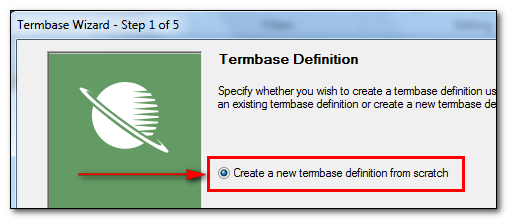
I need to take these three columns and I want to put them into a single MultiTerm termbase so that I have a mechanism for recognising whether a term is forbidden or not, The structure I use to do this is called a Termbase Definition and because of the multitudinous of MultiTerm this can be anything I like. So I don’t have to try and shoehorn this into a predefined structure. To do this I find the easiest approach is to create a new termbase and build the definition as I go and then use the Glossary Converter. This is as opposed to using MultiTerm Convert and then MultiTerm but that would work too. This is quite straightforward, and even fun, so I’ll share this method for now. First go to File -> Create New Termbase (or Ctrl+Alt+T) and follow the wizard to the first step where you can select Create a new termbase definition from scratch;
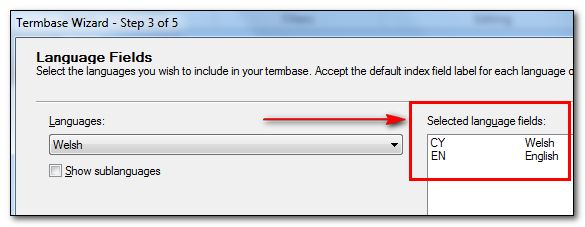
On the next screen you can give your termbase a friendly name… I just used “Definition” because I’m only doing this to get the definition and have a sample Termbase with the structure I want. The screen after that allows you to add your languages. I don’t want to restrict my use by having American English and British English as separate languages so I just select English and Welsh.
I’m going to categorise the type of English with an additional field. If you scroll back up to the screenshot showing how Studio can use this Forbidden Term you’ll see that the field is referred to as a picklist. This is a clue, but it’s a tricky one because you won’t know this until you try and use your termbase in Studio for this purpose, and by then it’s too late as you’ve already created it! But as we know it I add a new field that I will call “Variant” for language variant, and I’ll make it a picklist with two attributes, “British” and “American” as you can also see in the Studio screenshots above:
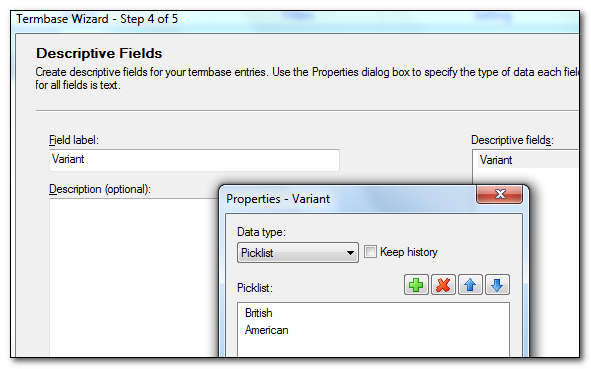
I just typed in “Variants” and then added it to my list, selected it and clicked on Properties where I was able to define it as a picklist and add the two attributes I wanted. I then click on next and this is where the fun starts because in here you can decide how you want your termbase structure to be defined… and it really can be anything you want, or in this case need:
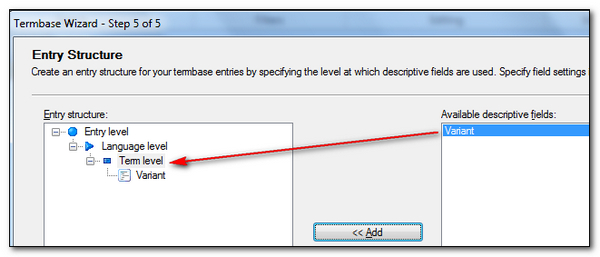
The entry structure on the left is automatically defined with the basics that MultiTerm needs, and this will be the Entry level, the languages and the terms. After that it’s completely up to you. In this case I just want to be able to recognise which variant of English each term is, so I add my new “Variant” field to the term level as shown above.
Then I click through to the end. Finally, just to see what this looks like I can click on the Termbase Management view where I can see what the finished definition looks like (this is still called Catalog if you are using the 2011 version or earlier… or maybe that should be Catalogue ;-)). I have no terms in here yet, but the termbase is created based on the definition I want:
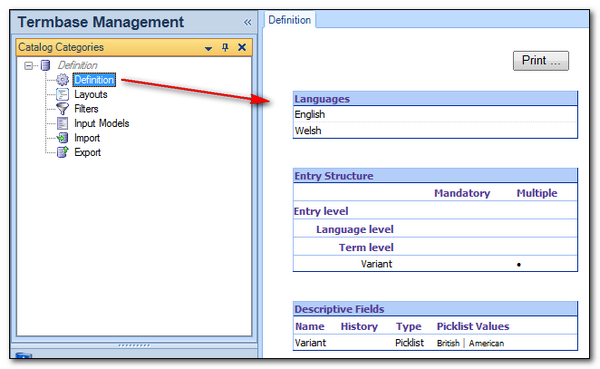
Importing the Terms
The next step, is to get all of your terms into a Termbase that has this structure. If you take a look at the original spreadsheet it’s clear it’s missing the “Variant” attributes against each term, and because I’m using the Glossary Converter I need to ensure that the column headings for the English are the same because I want synonyms and not separate languages. So I change the spreadsheet so it looks like this:
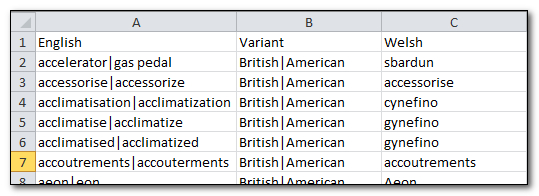
The way I did this was to “concatenate” the English variants with a pipe symbol between them. This is a neat function in Excel that just looks like this:
=+A2&"|"&B2 or =CONCATENATE(A2,"|",B2)
The top one is just shorthand and allows me to write the formulae in the way my mind works, but if you use the formula feature in Excel it will look like the bottom one.
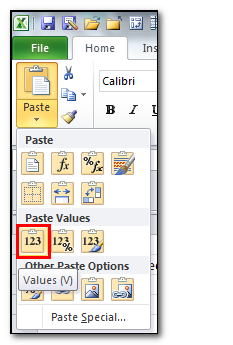 Both do exactly the same thing. I write this formula into column D and copy it down the length of my spreadsheet, then I copy the entire column and paste it as values only into column A using the Paste Special feature in Excel. This gets rid of the formulae and leaves me with the results of the concatenation only. I can now delete column D.
Both do exactly the same thing. I write this formula into column D and copy it down the length of my spreadsheet, then I copy the entire column and paste it as values only into column A using the Paste Special feature in Excel. This gets rid of the formulae and leaves me with the results of the concatenation only. I can now delete column D.
The next thing is to replace column B with a new header called “Variant” and then copy “British|American” all the way down the spreadsheet, overwriting whatever was in there before. Once this is done it should look like the one above with three columns containing all the appropriate information for my termbase.
The Glossary Converter has an option to use a pipe symbol as the separator between synonyms and will map the appropriate “Variant” to the right attribute (British or American) as well. I like this one because it maps nicely with the way some other tools like to handle glossaries.
So all I do now is start the Glossary Converter and click on settings where I can activate the synonym support and make sure the symbol is the pipe symbol, and then activate the checkbox that allows me to point to the termbase I created at the start. I won’t be populating this termbase, I’m only using it as an example of what I would like my new one to look like:
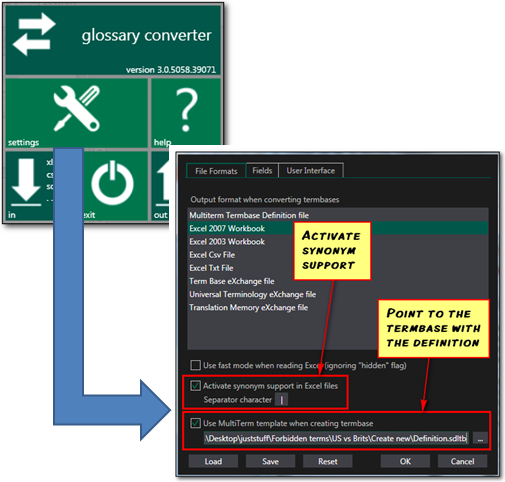
Once this is done I click on OK and this returns me to the main window where I just drag and drop my spreadsheet into the interface and make sure that my language columns are recognised as languages, and my “Variant” field is recognised as a field at Term Level:

Then I just click on OK. The result is that my termbase is created and it is structured like this:

Perfect… all I do now is add this to my Project in Studio and set up my Terminology Verifier as described at the start! This is quite a long post, with lots of screenshots to try and explain how this is achieved in simple steps, but the actual time it takes is very short. So, just to finish I have created a short video of the whole process from start to finish, going through all of these steps and then applying this and working with it in Studio. It’s easier than you might think, and this process, once you become familiar with it will allow you to get a lot more from Studio by using the glossaries and terminology your clients provide on a project by project basis in the future.
Just in case you have not used the Glossary Converter yet you can find it here on the OpenExchange… it’s a free tool and well worth downloading and using:
The GLOSSARY CONVERTER on the OpenExchange
The whole process!
Paul, this is a great article!
I have one client for whom I translate American English into British English and have been doing so for seven years now. OK, it’s all technical work where certain terms in one language either don’t crop up at all in the other language or where the term has a completely different meaning. There the ‘forbidden terms’ will be a great help, especially as I can use the SDL Term Bases in my other localiz(s)ation software. But then there are the ‘grey’ terms that might be allowed or forbidden, such as ‘meter’ (as in gas meter) and ‘metre’ (as in a measurement unit).
To take this one stage further, how would I get an automatic translation when copying source to target in setting up the project of the forbidden words?
Glad you like it Ben!
On your question, I’m not sure I completely follow you. Do you mean you want to set up Translation Project, translating from British to American (or the other way around) so you have a list of synonyms? And then use Machine Translation for this? I’m probably being dumb here, so maybe you can explain in simple steps for me?
Hi Paul,
I meant something along the lines of what Andreas is thinking. When I’m in Studio and move to the next untranslated segment, it copies over the source text to the target side. If a forbidden word crops up in the target segment it would be great to get an automatic substitution. In the grey area, some words could be described as forbidden in certain situations, but in other situations they could be allowed. This would apply to the US to UK translations that I do as the bulk of the text remains the same and it is only certain words that need changing. It would not apply to my German to English work.
ok – I see what you mean. I think this is a little different to where Andreas is coming from. I can think of a workaround that might be interesting for you using the Terminjector. It goes like this:
– copy source to target for the entire project and update to a TM
– Create the project again and use the Terminjector to pretranslate with the TM you just updated
The Terminjector would allow you to have a list of the terms in a text file, and then it will automatically replace any term it finds in the TM before it is inserted into the target side of the translation in Studio. So this would achieve what you wanted, but not by using the forbidden term approach. It would be based on every US term in the list being substituted automatically with the UK one.
Maybe that would be a useful way to handle this usecase?
Great stuff, Paul, and how timely 😉
I’ve learnt even more about forbidden terms now.
As always you’re an inspiration Emma 🙂 It was very useful for me too; I like playing around with these things and trying to find the easiest way (for me).
Thanks for the article Paul. The terminology verifier has one (major!) flaw though, which would apply in your situation as well in some (rare) cases – let’s say elevator | lift. If you use a polysemous word which is defined as forbidden anywhere in the termbase, it will be reported, although in the current context (the entry you actually use) it may define it as allowed. I really hope SDL will improve this soon. I think it is really important that homonyms in the termbase should be able to both allowed and forbidden, in different entries of course.
Cheers,
Andreas
Hi Andreas,
There’s always an exception to the rule in pretty much anything. How would you see this being achieved without using some sort of machine translation to get the context maybe, or perhaps linking it to the context of a previous translation maybe? The latter would fail if you hadn’t translated something similar before… for former would work, but only if the machine translation was good enough.
Sounds tricky to me.
Hi Paul, sorry if I wasn’t precise enough. Actually, it’s not as intricate as you might think. I just want Studio to check the target term with respect to the source term. Currently. the “forbidden” check only checks the target term. So if the term you use in the target is set as forbidden in *any* entry, you will get a false positive in the verification. Example: DE to en_US and you’re translating the word “heben”. You write “lift”, which in MultiTerm is set as forbidden for “Fahrstuhl” since it’s en_GB for “elevator”. This will produce an error even though you might have an entry for “heben” where “lift” is allowed in en_US. The verification can’t tell the two “lifts” apart and will thus give you an error.
To my mind, this really needs to be rectified since this severely hampers concept-based terminology work.
ok – I had a chat with the Product Manager about this and he has added homonym disambiguation to the product backlog. That doesn’t mean there will be a quick fix, but it does mean whenever the items on the backlog are reviewed (after each release) we have an opportunity to try and squeeze them into the development program alongside other things on the list.
Great post! An easier way to concatenate for dummies: use the Merge columns from (free) Excel add-on “ASAP Utilities”.
Hello Paul,
thanks for this article. I’m trying to do the same in order to create a termbase for Studio that recognizes correct and wrong collocations but the Glossary converter doesn’t recognize correctly the columns. Does it have anything to do with the Glossary converter version? I see in your video you use the 3. version whereas I have the 4.3.
Hello Davide, I think it’s more likely the way you are structured. Better to ask this question in here and then we can help you more easily.
Thank you Paul for your reply. I managed to create the TB after saving the Excel file into the old xls format and the Glossary converter worked fine. but I have not tested it in Studio yet. If I’ll have problems with it I’ll use the link you suggest. Davide