 My son asked me how my day had gone and before I could answer he said in a slightly mocking tone “blah blah blah… XML… blah… XML … blah blah”. Clearly I spend too much time outside of work talking about work, and clearly his perception of what I do is tainted towards the more technical aspects I like the most! Aside from the note to self “stop talking about this stuff after I leave the office!” it got me thinking about why I probably think about XML as much as I apparently do and how I could help others avoid the very same compulsion! I’ve written articles in the past about how to use regular expressions in Studio, and an article on using XPath, and I’ve probably touched on handling XML files from time to time in various articles. But I don’t think I’ve ever explained how to create an XML filetype in the first place, or why you would want to… after all Studio has default filetypes for XML and this is just another filetype that the CAT tool should be able to handle… right?
My son asked me how my day had gone and before I could answer he said in a slightly mocking tone “blah blah blah… XML… blah… XML … blah blah”. Clearly I spend too much time outside of work talking about work, and clearly his perception of what I do is tainted towards the more technical aspects I like the most! Aside from the note to self “stop talking about this stuff after I leave the office!” it got me thinking about why I probably think about XML as much as I apparently do and how I could help others avoid the very same compulsion! I’ve written articles in the past about how to use regular expressions in Studio, and an article on using XPath, and I’ve probably touched on handling XML files from time to time in various articles. But I don’t think I’ve ever explained how to create an XML filetype in the first place, or why you would want to… after all Studio has default filetypes for XML and this is just another filetype that the CAT tool should be able to handle… right?
Wrong! Well partly wrong anyway. If the XML is simple then the default filetypes will probably handle the file perfectly well. But what makes XML unique compared to most other filetypes is that the translatable text could be hidden in user defined locations, and Studio (or any CAT tool for that matter) does not necessarily know where it is, or that it should be translated, without you providing some additional information.
But before I dive in I think it might be helpful to understand a little of the terminology here, not everything you’ll ever need to know about XML as this is a pretty big subject and I’m still learning myself, but rather a few simple things that are relevant to knowing how to extract translatable text. Take this short XML file as an example:

The first red line <grandparent> is called an element. In this case it’s an element I decided to call “grandparent”. In fact this element is a special one because it’s also the first and last element in the file. So this is also called the “root element” and it’s important to note this because we can use the root element as one way to automatically decide which filetype to use when opening an XML file in Studio. There are two more elements in my file; “parent” and “child”. I deliberately used these names because this nesting of the elements inside one another is important. Here we have one element called “parent” which is a child element of the “grandparent” and it contains the translatable text “I’m the parent and I have two children”. Inside this “parent” element I have two “child” elements and they also contain an attribute. The translatable text is in black, “My son is called George.”, and “My daughter is called Sally.” The attributes are providing more detailed information about the children, so in this case defining whether they are male or female. As a general rule, the information I have just provided is how we would like things to be in an ideal world. But that would be too easy and in reality there are no real rules to say when you should use an element and when you should use an attribute! In practice this is just how we would like to see them in the translation industry and if they come like this then the default XML filetype, called AnyXML in Studio, will often suffice. But we want to look at the real world!
Why use custom XML filetypes?
So let’s take a look at a couple of files, starting with an XML file that looks like this and following the simplistic logic I explained above:
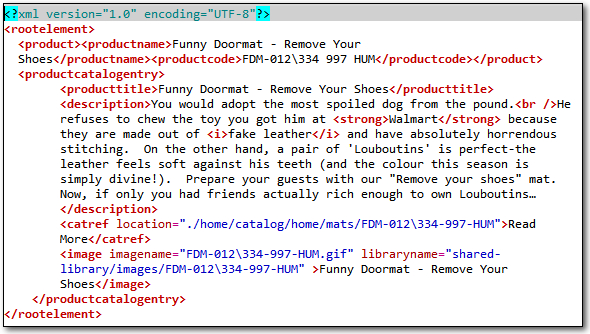
This is quite straightforward, every piece of text that looks as though it’s translatable is inside an element. If I open this in Studio without creating a custom XML filetype it looks like this – I’m using the TagID mode to display tags so the tags are numbered and the orange tab at the top is displaying the name of the filetype that is being used to open the file for translation:
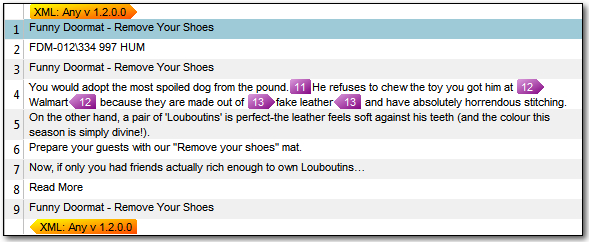
So here, the Any XML filetype (the default in Studio) does a pretty good job and even manages to determine what is likely to be inline tags versus external tags, so the text flows quite nicely making it easy for the translator. For this file you could even copy source to target for things like segment #2 which is not really translatable text. So pretty simple and definitely usable… But now let’s take an XML file like this which contains exactly the same content but has been prepared in another, equally valid, XML way:
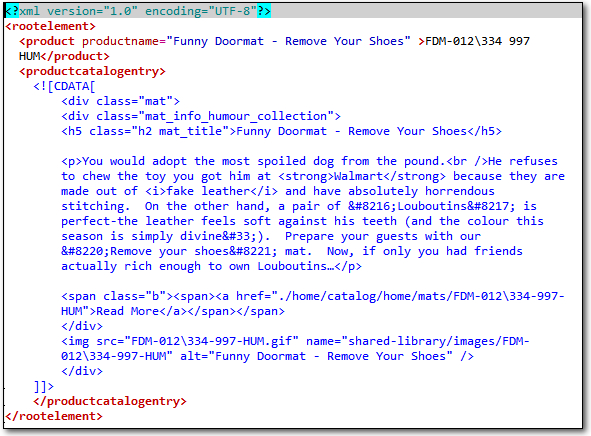
The one is trickier because some of the translatable text is now in an attribute rather than an element (the productname attribute for example), and the default AnyXML filetype does not extract text from an attribute. We might not consider it to be good practice to use an attribute for this, but in practice we all know it’s pretty commonplace and there can be good reasons for the file to be constructed this way. In addition to this much of the text is provided in the file by using a CDATA section. This is normally used for part of the file that should not be parsed at all with an XML parser, often including characters that would be illegal in XML. This can be a complete html file that is embedded into the XML, or part of one as I have done here, or even something else based on a custom script written by a developer. So there is no single way to handle all embedded content. If I open this file with the default AnyXML filetype then it looks like this where we see html entities, opening and closing tags (<> for example) and the name of these tags (div class=”mat” for example), all of which you would not want to have to try and translate around:

Yuck! Not very nice at all because not only is it parsing the html code inside the CDATA section as translatable text without any kind of tag protection at all, it’s also missing the product name at the start because in this file it was stored in an attribute as opposed to an element. So what we really need is a custom XML file that can deal with the specific nuances of this particular XML file. The release of Studio 2014 SP1 provides a neat way of dealing with the CDATA or any other form of embedded code, but the basic principle of how to create a custom XML filetype in Studio is the same now as it has been since the release of Studio 2009. At the risk of this being a ridiculously long post let’s take a look at how this is done using the second, and more complicated XML example… at least we’ll look at how I normally tackle it as there are other ways.
A general note though. I won’t be covering every single thing about XML file types in Studio either. So if you have a question I didn’t address in this post please refer to the online help which is pretty useful, or post your question into the comments below so we can build a useful reference article for anyone else.
First Steps
My first step in creating a custom XML filetype in Studio is to import the XML file so I have all the elements and attributes in the XML available to me for selection as I create the custom rules. To do this you go to the File Types node in your options (not forgetting there are differences between the general Options and Project Settings as usual) and click on New which will bring up the Select Type dialog box:
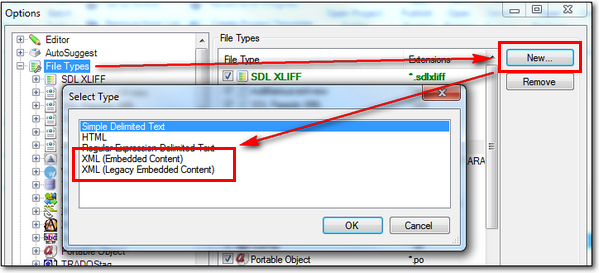
If you’ve done this before in any version of Studio prior to Studio 2014 SP1 you will note that there are now two options for XML.
- XML (Legacy Embedded Content), and
- XML (Embedded Content)
I mention them in this order because the XML (Legacy Embedded Content) is the same as it was in previous versions. XML (Embedded Content) is the new to Studio 2014 SP1 approach and I’ll cover this after discussing the old one briefly as I go through the steps. The next steps will be the same irrespective of which of the two XML types you choose.
File Type Information
First you select the XML filetype you want and click on OK. This brings up the File Type Information dialogue box where the only two things I normally change are the File type name and the File type identifier:
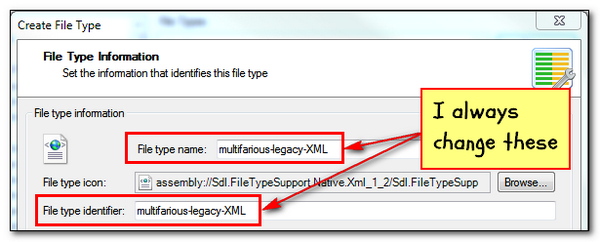
I change these because it makes it easier for me when I’m working to see the name of the filetype I created in the list of available filetypes, and also when I open the file and change the tag display to TagID mode the orange tab at the start and end of each file will display the name of the filetype too. Because I generally create XML filetypes to help other users I find it useful to easily distinguish the names in this way. Then I click on Next >.
XML Settings Import
This takes me to the XML Settings Import dialogue where I typically select my XML file so that all the elements and attributes are added to my filetype to make it easier for me to create the rules:
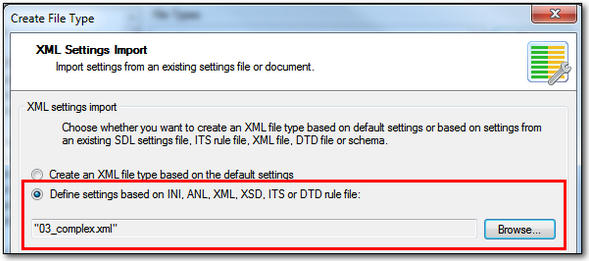
I browse to my XML file, or one that is representative of a batch of XML files, and after it’s selected as shown above click on Next >.
Parser Rules
I now see all the elements that have been identified in the file, and they are listed like this based on whatever defaults Studio believes the tags should be:
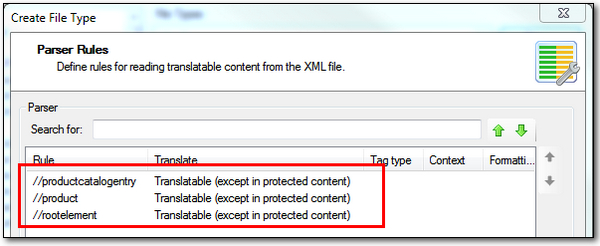
At this point I would normally just click on Next > and would address the rules in detail after the filetype was created, but to keep this simple and ensure the article flows logically I’ll make the changes to the parser rules now. But it’s worth noting that if you miss something it doesn’t matter as it’s simple to make changes later on.
If you look at the XML example above, the one with the CDATA as this is the XML we are addressing here, you can see that what we want to extract for translation is the the content of the productname attribute and the productcatalogentry element. The rest I don’t want. So first I remove, or disable, the rootelement and the product. Then I add in two rules… you’ll see the Add…, Edit… etc toolbar becomes active for more options when you select a rule. My Parser Rules now look like this:
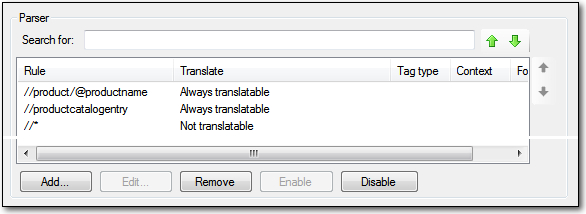
I created the //* by selecting the XPATH option in the Add Rule dialog box (read more on XPath in Studio). This is basically a wildcard where the star simply means select everything, and I made that Not translatable. I did this because the first thing I want is to make sure I get nothing at all parsed into my file, and then I can bring in the information I specifically ask for, which in this case is the two rules above that. This is not essential, but I was shown this when I first learned from the Master, Patrik Mazanek, and the habit stuck!
The productcatalogentry element was already there, I just changed the Translate property to Always Translate by editing the rule. I did this as a matter of course because the default is Translatable (except in protected content) and I want to be sure that the content of this element will always be extracted even if it’s parent element is not. Plus of course I wanted to explain this concept that could be the reason for text not being parsed if you set a parent element to Not translatable.
I could have created the //product/@productname rule using XPath too, but because I imported the file into Studio earlier on as part of these steps it’s easier to let Studio do this for me. So I just Add… a new rule and select the Rule type Attribute, then select the element containing the attribute I want to narrow it down (a large XML file could contain a huge list, and sometimes with overlapping attribute values):
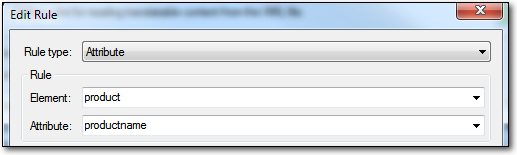
I set this to Always Translatable as well and then click Next >.
File Detection
I’m now brought into the File Detection dialog that provides me with a number of different ways to recognise the XML file I am opening. This is very important because as you create more and more it’s quite easy for Studio to use the wrong filetype for a particular file and if you didn’t notice (also remember why I always change the identifiers at the start) you may find your translated file coming back partially translated or parsing information that should not be at risk of change at all. This is particularly so when handling XML files from the same customer as they may well use the same root element but have different schemas for example. In this case, let’s keep it simple and just use the root element as the criteria for recognising my file:
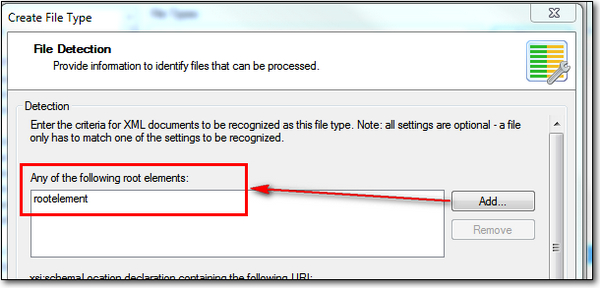
My root element was actually called rootelement and as you can see in the image it is already populated because I imported the XML into my filetype at the start. So all pretty straightforward… and at this point I can click on Finish… and that’s it. My custom filetype is complete… almost!
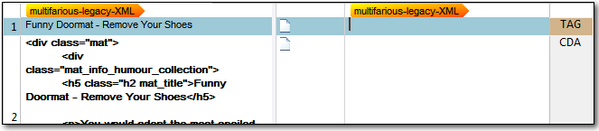
My attribute is being parsed this time so segment #1 contains the translatable text from the attribute value (note that this is also annotated as a TAG in the document structure column on the right because it is an attribute and not an element), and I have not got the product code which was extracted with the default AnyXML. So I’m nearly there. All I have to do now is tackle this embedded HTML in the CDATA section.
There are two ways to do this depending on which XML filetype you created, but I’m mostly interested in the new way with Studio 2014 SP1. However, I’ll take a brief look at the Legacy Embedded Content first.
XML (Legacy Embedded Content)
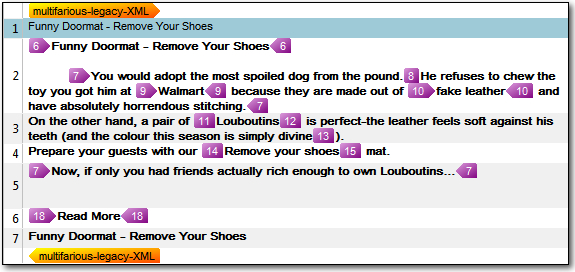
In both the Legacy and the new method for handling Embedded Content you have to first enable it. So for this legacy filetype I would do this and check the box:
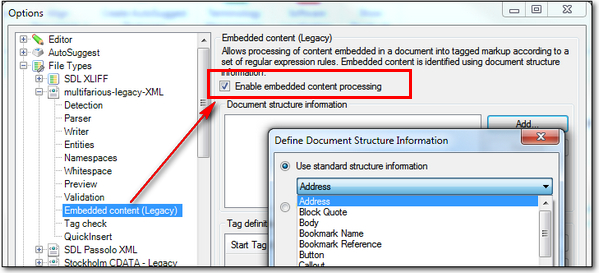
When I do this I can now add the Document Structure I want to be handled with the Embedded content processor. At this point you may well be asking what do I mean by this? Well, take the file we have so far. The right hand column, the one that appears when you open the file, contains this information, and you can expand it by clicking on it:
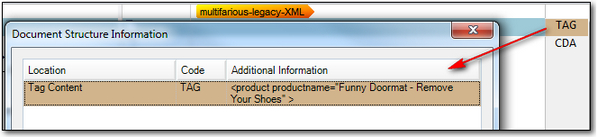
The Code you see here is the code you need to add into the list for any text that contains embedded content that you wish to treat with the embedded content processor. In this example TAG is the code, but I don’t want to use that one as there is no embedded content in this segment. It’s also worth noting that if there were I could not handle embedded content inside an attribute anyway… hopefully most users will never come across anything so poorly written as that! There is in the next segment however as this is the CDATA Section. Now, because these two types of Document Structure are also Studio codes and not custom codes that I created myself I can use the Location (Tag Content in the example above) to identify it in the list. So I actually want the CDATA Section which I can select like this:
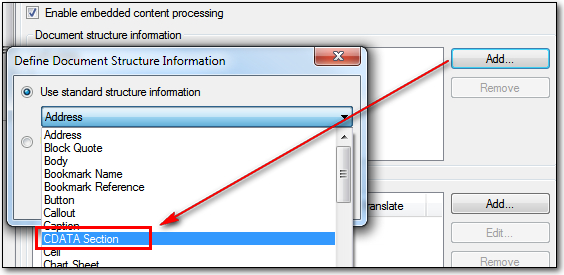
Once I’ve done that I need to create my Tag definition rules. Now this will be a similar process to the way you handle embedded content in a Microsoft Excel file which I wrote about in “Handling taggy Excel files in Studio…“. So I won’t write a lot more on this process for Legacy XML filetypes. Suffice it to say the finished rules for my filetype might look something like this:
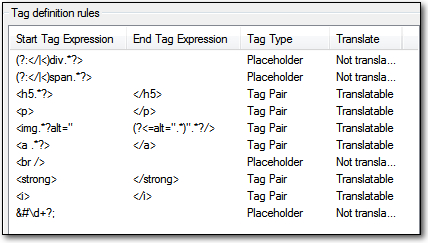
These take a while to create, are pretty rough and the finished article, whilst better than than the version produced by the AnyXML filetype, does still leave a bit to be desired. I could spend time working on this to make it more user friendly, but even after all of this it would only take a file to be provided that contained different markup and I might have to start changing the rules again. Using these rules I get this which protects things I wanted protected but also doesn’t really make for simple translating because everything is a tag including the entities, and the translator will have no idea about the context of the text because the embedded content rule with this method cannot hold Document Structure Information of their own. I would not say this has no place however, because there are some files where the ability to be able to use regular expressions to protect tags, and text you don’t want to be translated is a real plus. But there is a better way!
Ziad Chama also recorded an excellent webinar that is freely available called “How to create an XML File Type in SDL Trados Studio 2014” which goes through the process in detail. I’d thoroughly recommend you watch this if you have any interest in creating XML filetypes in Studio as it is very informative and Ziad is a real expert. It covers Studio 2014 prior to the release of SP1 which introduced a new method, so that’s what I’ll cover next.
You can also find a handy knowledgebase article here that is straight to the point!
XML (Embedded Content)
But now let’s take a look at the new method in Studio 2014 SP1. The first steps are exactly the same, but when you get to the embedded content section this is where you’ll notice the difference. It looks like this:
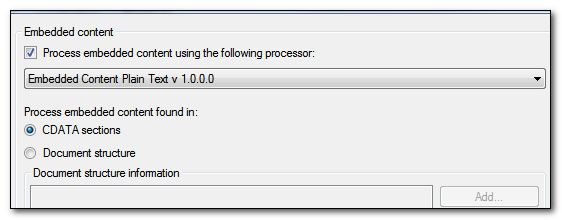
So two new things:
- There is a drop down box that seems to refer to completely different filetypes
- You can decide whether to apply the embedded content processing to CDATA Sections or any other named Document Structure Information (as before with the legacy filetype)
Selecting the embedded content processor to use
Let’s tackle point one first. This is a drop down box that refers to completely different filetypes. So you will probably already see that the concept here is to use a filetype within a filetype rather than have to create the regular expressions to handle the content as we did with the legacy embedded content processor:
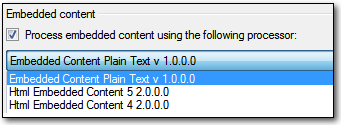
The defaults are the regular expression filetype, and the two HTML filetypes that come with Studio out of the box. But you can add your own which makes it possible to configure one of these filetypes so it does not use the defaults and then have different embedded content processors depending on the content of the work you are doing. So if I collapse my navigation menu I now see this in my options:
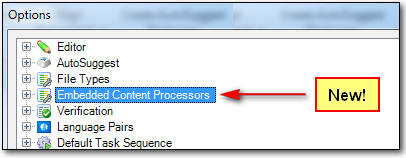
Expanding this allows me to take a copy of one of the three defaults and then configure it as I see fit. I don’t really have to do this for the simple complex example I have used for this article, but this is how you would do it! You click on the Embedded Content Processor node and you’ll see the three available filetypes. Select the one you are interested in; so in my case I picked the HTML 5 filetype, and then click on Copy…:
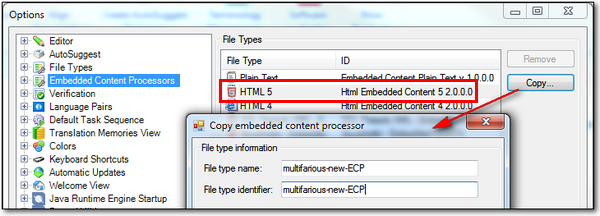
You get a small dialogue box where you can change the name of the File type and the File type identifier as before, and pay attention to the name because you cannot use the same identifier as you did for the main filetype as duplicate file type IDs are never allowed. Then click on OK and close the Options. You need to close them because if you don’t the list won’t be refreshed (a little issue I’m sure that will get resolved in a future release!) and then when you open the options again and go to the Embedded Content node of the new XML filetype you created you will be able to select your new filetype as an embedded content processor like this:

Identify where the embedded content is found?
This brings us onto my second point which is that you can decide whether to apply the embedded content processing to CDATA Sections or any other named Document Structure Information (as before with the legacy filetype). If the embedded content is in a CDATA section which is probably the most common usecase then now you do nothing more than check the CDATA sections checkbox as shown in the introduction to this part of the article. I can then open the file and see this without having to do any additional work at all:
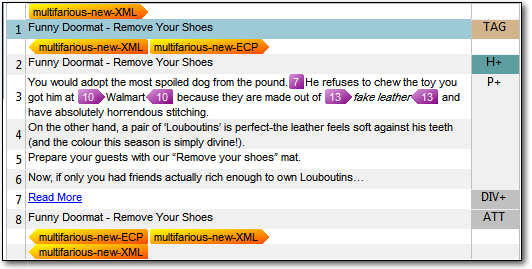
Much better… and easier! because I’m also still in TagID mode you can see the name of the files which are being used in the orange tabs, and the embedded content processor displays the correct Document Structure Information for this filetype which adds additional context for the translator. You’ll also note that the entity values are correctly transposed so I don’t have to deal with them as tags.
If the embedded content was in another type of Document Structure then it works in exactly the same way. You select the appropriate code and that’s it. No need to add a bunch of regex rules in here.
Sharing custom filetypes with others
I can’t leave this section without mentioning how you share your custom filetypes with others. This is done by exporting your settings, but now with Studio 2014 SP1 you have two lots of settings to share.
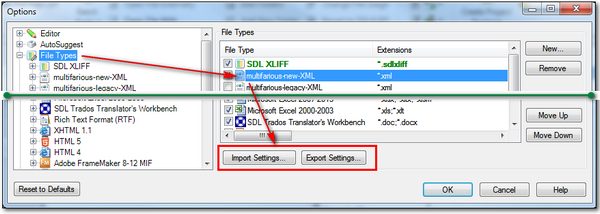
*.sdlftsettings
This is the settings file for the custom XML filetype you created. To export/import these files you click on the File Types node in your options and then select the specific filetype you wish to export from the list that now appears on the right. This will activate the Import/Export Settings… buttons:
*.sdlecsettings
This is the settings file for the custom Embedded Content Processor you created. To export/import these files you click on the Embedded Content Processors node in your options and then select the specific filetype you wish to export from the list that now appears on the right. This will activate the Import/Export Settings… buttons exactly as for above.
This is actually another good reason to always create a copy of your default Embedded Content Processor because if you are sharing custom XML files with a colleague then they may get unexpected results if you used the default HTML file and when your colleague used it the settings were different because they had a customised HTML filetype for example.
Checking your work!
At this point I think I’ve covered enough for you to get started and have a play. But seeing as I’ve written all of this I just wanted to mention Pseudotranslate and how this can help you to make sure your filetype is extracting everything you want, or possibly too much. Once you have completed your filetype to the best of your knowledge, it’s worth opening it quickly with the Translate Single Document approach and without a Translation Memory. Now run the Pseudotranslate batch task with these options:
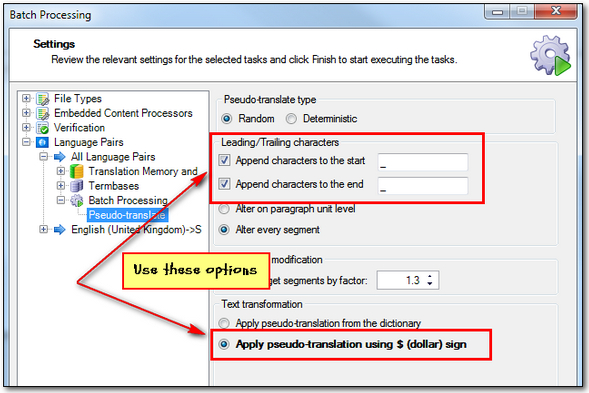
When complete you will see that the target column of your file in Studio is now full of question marks, so these stick out like a sore thumb! Save the target file and inspect the result with a text editor:

If you missed anything out that should have been translatable text it’s much easier to spot it in here and you can refine your filetype until it’s ready for production. But this looks good to go, as the only recognisable text that is between elements is the product code in the product element, and I deliberately excluded this with my custom filetype!
Gee, Paul, I can’t thank you enough for including a “get out quick” button from this article — I availed myself of the opportunity immediately and ended up in a close digital approximation of Nirvana. Have nothing to say about the rest of the text, but loved the unexpected bonus of calm.
Truly, thanks.
😉
Zakiya
Excellent… with any luck this post will have a little something for everyone!
Paul, the CDATA regex are terrifying, for this file you need just this two 🙂
<[^<]+?>
&#d+?;
Hi Juraj, of course there are always more than one way to skin a cat 😉 If you are happy to have every tag as a placeable, and not to extract the alt text on the image then these two rules would do it. Certainly catch all expressions have their benefits. But if you wanted to try and provide a better tag handling experience, have formatting on the extracted text or even different segmentation depending on the context of the tags, then you would need to handle them as separate expressions.
However, the point I’m making is using regex for this is sometimes terrifying indeed!
Excellent!!!
________________________________
Thanks Ali…
Wow thanks a lot for this long but very interesting post. I’ll be able to use Studio in a better way for my next XML+CDATA project. If only you had posted it 1 month sooner… it would have saved me a few hours 🙂
Nice shoot, thank you for clarifying the DSI stuff, and it will be much better if a thorough DSI explanation is provided, e.g. what do “Block Quote” and “Callout” use for in the screenshot of the section “XML (Legacy Embedded Content)”? Any links to refer to?
We don’t have any links for these as they are just a list of simple and common structures we recognise in other filetypes. So “Block Quote” would be referring to a block of text set off from the main text. Common in html and xml. The same for “Callout” which would be a bock of text used to annotate an image perhaps, or something like that. You don’t have to use the correct ones for the correct situation, and you could create your own custom ones. But if you were familiar with the creation of html or xml files, then you would probably be familiar with these terms.
But I kind of agree with you that it would be handy to have a list somewhere. I did come across this one for docbook which explains some, and if I find time I might validate a list of the ones we use as standard and see if we can publish them in a KB or something.
Thank you Paul, very suggestive, and reminds me of your blog on taggy excel which used the “cell” thing, hopefully a list could be summarized out for different DSI usage.
Hi Paul,
I will try to make it clear. In the XML file type, there is an entity conversion function (used in my case to convert the html representation of accented letters into a readable format and to restore it once the translation is done). Could you please confirm that, with the legacy mode, this conversion does not occur for content in CDATA sections ? However, it seems to be OK since version 2014 SP1 thanks to the new Embedded content processor.
Hi Nicolas, with the previous version this did not work because you only had regex at your disposal. So you could convert to tags, but not do a proper entity conversion. In Studio 2014 SP1 with the new processor this works fine for most cases.
Hi Paul,
One more question, I’m trying to use this new Embedded Content Processors on one file. I wanna lock a specific text (mod_1364893518685_2901.xml) using the “Embedded Content Plain Text v 1.0.0.0” I have created a new one, set the Inline Tags, the the newly created file type I have set the Document structure for the “body” but I cant get any reasonable output. Its basically still the same.
Kind of tricky to answer a question like this Juraj. Send me the file so I have some idea of what you are doing and what you are looking at. These comments are probably not the best place for a question like this without any qualification at all.
Hi Paul,
Thanks so much for putting all this together! Before I reinvent the wheel, I wonder if anyone here has had any experience translating wordpress content as xliff or xml. We have a multisite wordpress installation with the multilingual press plugin installed for German and English and our developers have created a custom xliff export function (which unfortunately exports xliff 1.0). I’ve set up a custom xml file type to just enable the target element from the xliff file for translation (that works) and I’m trying to convert into an internal tag and deal with short codes with translatable attributes e.g.
[/collapse]
[collapse title=”Philosophische Fakultät und Fachbereich Theologie” color=”gold”].
I’m not really sure of the best approach and I’d really welcome any tips or pointers. Should I be using the Embedded Content Plain Text processor for this?
Thanks,
Daniel
Hi Daniel, I encountered the same request for translating wordpress xliff files generated by a multilingual plugin wpml, and the solution for this scenario is Rainbow, an open source toolkit on the basis of OKAPI framework, and the wordpress xliff file could be properly handled by the filter XML stream, then work the file out using Tageditor or some other xliff editors rather than Studio, and convert back. Hope this helps.
@Paul:
Looking forward Studio could publish a new file filter to properly handle wordpress xliff file or alike thing.
Hi, I think this is a good opportunity for an openexchange filetype for this flavour of XLIFF, if anyone is interested to create one? Or I could find a developer for this if you guys wanted to share the cost?
Hi,
We moved away from WPML because of a bug in an earlier version with the language switcher but we export XLIFFs in a similar way. For anybody looking to process XLIFFs exported by XML it’s confusing because there seems to be some out of date information on wpml.org relevant to older Trados and Studio versions. We use Studio 2014 SP1 but when we used Studio 2011, trying to open the XLIFF files came up with an error message about the DTD due to the older version of XLIFF. I don’t think you really need Rainbow – you can just create a new file type based on the xml file type and create rules for embedded content in Studio or an ini file in TagEditor. WPML converts line breaks in the wordpress post to which makes for lots of tags in some posts… and these tags should be protected in your custom file type, it seems like WPML support aren’t really aware that these can be protected in Studio (http://wpml.org/forums/topic/sdl-trados-studio-tag-issues-with-xliff-0-9-4/). Unfortunately, I’m pressed for time at the moment and but if my file type helps anyone using WordPress and Studio, feel free to download it as an example from: http://mccosh.de/wpml.sdlftsettings — I just made the content within the element translatable and added a few example rules to deal with the line breaks and an example shortcode with a translatable attribute. I know it’s good practice to add //* into the XML parser rules but I kept accidentally making the CDATA untranslatable and ran out of time to work it out myself (I also don’t have a budget…). If we improve these settings, I’ll submit it to OpenExchange. Hope you enjoyed your film, Paul 😉
Regards,
Daniel
Hi Daniel
Do you still have the wordpress settings?
We encountered a WP file and I tried to use HTML5 for CDATA and excluding some elements from translation with a little of success, but would be quite interested to see your results and learn from them.
MTIA and best regards, Jerzy
Hi again,
Sorry, that was quite an involved question. I managed to find a solution by reading your other posts on embedded content and testing with RegExBuddy etc.
Best,
Daniel
Thanks for updating the post Daniel… this was something I saved for my flight back home this afternoon! Now I can watch a movie 🙂
Hi Paul,
I have a question on the Embedded Content Processor (ECP), it seems I have to create a new filetype to apply the ECP other than to any of the exist filetypes. So there will be no big help if I need to process xlsx, xliff or ttx file with a lot of CDATA content in it, and a bunch of regex is still needed to write by hand, am I correct?
I think SDL Trados users will be happy until the ECP extends its applying range, and it is indeed a half-product by now.
I wouldn’t call it a half product, but there is definitely room for further enhancements to make this easier. The new embedded content processor certainly makes it more comfortable for XML filetypes containing embedded content, and the plan is to extend this capability to more, but the biggest improvement will come when you can apply this principle to any filetype including the ones that currently cannot handle embedded content at all… such as the two you mention (XLIFF and TTX). TTX should probably be handled prior to becoming a TTX, but it would be useful to be able to make up for inadequately prepped TTX files too.
Hello Paul,
I work with wordpress posts exported as xml files. The outcome is an embedded file with HTML 5 code. I´ve followed your instructions on the new procedure in 2014 sp1 and it works like a charm! Well, almost…
There´s a block of code that Trados does´t extract correctly:
[caption id=”attachment_477820″ align=”alignnone” width=”984″]altimg class=” wp-image-477820 ” src=”http://whatever.png” alt=”blah blah blah.” width=”984″ height=”380″ /> BLAH BLAH BLAH [/caption]
Actually the problem is only on this part, which Trados thinks is translatable text:
[caption id=”attachment_477820″ align=”alignnone” width=”984″] [/caption]
I guess I can solve this problem if I tweak something in the parser rules section of the embedded content processor of my HTML5 filetype, but I have no clue how to do it.
¿Could you give me a little hint?
Hi, the problem you’ll have is that if you use the HTML filetype for embedded content then you cannot use regex to handle the script. So to be complete you will either have to use the legacy embedded content and define rules for everything, or use the SDK and create a filetype specifically for these files. The latter is probably a better idea but it does require developer skills.
Incidentally, to display the square brackets you need to write them as entity values.
I´ve tried the legacy way but it´s really sickening because there´s always something wrong when opening the file in Trados and I´ve no idea about the sdk. I thought I could tweak something in the parser rules of the embedded content processor.
Thanks very much anyway 🙂
The legacy is tricky because you have to be very careful about not creating duplicate rules that conflict with each other. I’m pretty sure there will be further improvements to the embedded content processor and also to the ability of the HTML filter to handle scripts. That’s the problem really I think… the square brackets are not being handled as scripts.
By the way, I´ve also two more questions regarding SDL Trados as I´m really new to it:
Do you know what I can do to get a style sheet to preview the content of this kind of file? Trados tells me there´s no preview for the custom file I created.
Is there something I can do to make the preview window show up quicker? When I click on preview it moves so slowwwwlyyyy..
On the preview… you have to create a custom stylesheet. I wrote an article on how to do this here : Stylesheets
On the slow preview window… not sure. Maybe dock it on a separate screen (if you use two) and then you won’t have to use it at all in slide in slide out mode.
Thanks very much!
Hello Paul, I´m still struggling with xml embedded content. I gave the legacy way (using regular expressions) another try and this time I could manage to get a clean translatable file, but still have a problem:
every time trados finds an html tag, it “breaks” the sentence and creates another segment. This way, it shows some sentences divided into two, three or more segments. Do you know If there´s a way to prevent this?
Hi, my guess is you are using some generic catch all expressions in addition to more specific ones. The problem with this is that you often duplicate rules and this can cause the effect you describe. So you need to be very careful and if you want a catchall in addition to a few specific rules then you need to make sure you exclude the specific ones in the catchall expression. So for example if you wanted a catch all tag pair expression that excluded br tags for example, then you could use something like this as the opening expression:
(?:(?!(<br))<[a-z][a-z0-9]*[^<>]*>)
And this as the closer:
</.*?>
Maybe that will give you some ideas that might help?
Hi Paul. I´ve tried your suggestion but still getting the same results, sentences “broken” at the beginning of a tag. I think the problem is that I´m not very good at regexp 🙂 If I come up with something positive I´ll let you know.
Thanks very much for your help.
Hi Paul,
JTLYK, if Trados 2014 UI is in Japanese on a Japanese Windows 7 OS,
an exception will be thrown when you click “Browse” on the “XML Settings Import” screen in your tutorial.
Here is the description of the exception thrown:
“Filter string you provided is not valid. The filter string must contain a description of the filter, followed by the vertical bar (|) and the filter pattern. The strings for different filtering options must also be separated by the vertical bar. Example: “Text files (*.txt)|*.txt|All files (*.*)|*.*”
Also the stack trace points to:
Sdl.FileTypeSupport.Native.Xml.WinUI.ImportRulesControl._browseButton_Click_1(Object sender, EventArgs e)
This bug can be worked around by changing the UI to English.
Thanks
Hi Jesse, thanks for letting me know. Best to report these things to support but I’ll send it in in case they don’t already know.
Regards
Paul
Hi Paul,
Love the article, but I can’t get this to work on my files. I turned off the Entity conversion because I need < and > to remain as is instead of , but now I would like the content between them to be non-translatable tag pairs. Currently, Studio makes each &;lt; and >: into individual placeholder tags instead of tag pairs. Furthermore, whatever is between them is translatable (since they’re placeholders). For example, “The cat is black” becomes “The cat is <b>black</b>” where each < and > are placeholders (4 in total) and the “b” and “/b” are translatable text. Is it possible to disable entity conversion for these two entities and then make them into non-translatable tag pairs so that “b” and “/b” cannot be modified? This would make the file much easier to work with.
Tommy
Hello Tommy, can you send me an example file… just a small representative sample? Will be easier for me to answer.
Hi Paul and Tommy. I have the same problem with the lt; and gt; tags. Did you were able to find a solution? Thanks in advance!
Hi Paul,
Sadly there is a bug in the HTML Embedded Content Processor (SDL reference 47280) which leaves the source text in attributes that have been translated – support say this is due to be patched in September. Just a heads up for anyone who is planning to use this and notices untranslated attributes. Quite unfortunate for us.
Thanks,
Daniel
Hi Daniel, correct but just to clarify that this is only for attributes in the embedded html and not in the xml file itself.
Similarly, there is a bug ID 46352 that prevents me from applying ECP to a tag content (in my case, the content of an attribute). I hope to get a fix for that soon…
Hi Paul, how are you?
I have a question regarding an xml file. I tried creating an xml filetype as you have explained but had no success. Also, I followed Ziad Chama’s instructions in the SDL ‘How to create an XML File Type in SDL Trados Studio 2014’ but still had no luck.
The problem is that I cannot help tags from appearing as regular text within each segment. Can I copy&paste part of the xml for you to help me?
Thanks a lot!
Cecilia
Hi Cecilia, why don’t you send me the XML file as it may be easier? You can send it to pfilkin at sdl dotcom.
Hi, Paul
Thanks for the article. I was wondering if you could help us with some XML issues we’re having for a game project.
The thing is, SDL Trados Studio 2014 won’t let us define inline patterns of tags for the following XML style.
Could you take a look and let me know if there’s a solution for this?
Best Regards
Anthony
Hmnn… if you want to put code in here you have to make sure you use entities for the tags. See this article… Disappearing forum posts!.
Sorry about that Paul,
Trying one more time.
<LocaleString Value=”[ffff00]Lv.{0} [-]{1} has joined the party.” Index=”Lobby.TeamSetting.JoinParty”/>
Presumably you want to extract “[ffff00]Lv.{0} [-]{1} has joined the party.” which is an attribute, and then protect these parts [ffff00]Lv.{0} [-]{1}.
Extracting the attribute is simple enough as I’m sure you figured out, but protecting the [ffff00]Lv.{0} [-]{1} is not so simple as I don’t believe the embedded content procesor will work on an attribute. I don’t know how complex all the files are or how much variation you have in this [ffff00]Lv.{0} [-]{1} or how often this appears? But your options are limited if you want to protect this.
– search replace that string in the XML with something easy to handle like XXX so it’s always picked up as an acronym (if they vary less useful)
– recreate the entire filetype using regex only, only practical if the file is not complex
Hi Paul,
I have a question regarding an xliff file. I succesfully blocked tags with this structure ” ” but I can’t block the tags with the “[xxxx] [/xxxx]” structure.
Is there any special instruction for these tags? I can send you the file for you to analyze if needed.
Thanks in advance.
Sebastián Martín.
Maybe worth reading this article quickly… helps to understand how to use code in these comments. I can’t see your code, but in general we don’t handle embedded content in XLIFF files yet… although I have a plugin in Beta you can test if you like?
Yes Paul, that would be great… please send me the plugin 🙂
Thank you very much.
Sebastián.
I’ll drop you an email to the address you used here.
Hello Paul,
This is very useful article for coming up with customized XML filetype!
What if we just want to show the content inside the tag? We don’t want to translate, but we just want to somehow see it in the Editor.
So, say in your example
can we somehow show “Funny Doormat – Remove Your Shoes” as non-translatable string?
Thank you!
Rieko
Hi Rieko,
You have three ways I reckon… although only the last one makes real sense:
1. View the content “inbetween segments” when using the “View All Content” option in the display filter (may also see stuff you don’t want)
2. View as content inside the tag (gets very purple)
3. Create a custom preview with a stylesheet – see this article
I’d go with the last option I think.
Regards
Paul
Hi Paul,
This was really helpful. Thanks for taking the time to teach us this stuff.
I do have a question, though. I made a custom XML file to process HTML code embedded in an XML doc enclosed in CDATA tags. All good till there is a sentence like:
<![CDATA[The file type works perfectly for all occurrences except when a line break appears result is Studio 2014 SP1 will exclude the whole string.]]>
The file type works perfectly for all occurrences except when a line break appears. Result is Studio 2014 SP1 will exclude the whole string and end file will have this line untranslated.
I used New File Type > XML (Embedded content) > Html embedded content 5 2.0.
I tried to find more info about this, but cant get the fie type to recognize the strings with line breaks in the middle.
Could you share some ideas?
Thanks,
Ignacio
I think something must have happened to the html file as it makes no sense to break in the middle of the string. Studio sees this as a new line and because the previous line only has an opening tag it’s getting ignored. I think a repair of the html may be your best bet.
Paul: Thanks for the timely answer. It is actually like that as if I remove the line break, or if I escape the angle brackets, Studio will read the string perfectly.
However, I thought that being inside the CDATA tag would make Studio read the as plain text, or that using the embedded content processor would just recognize the br tag as an inline tag and protect it. Isn’t it so? Would studio always read the br as a line break and ignore the whole string?
Thanks,
Ignacio.
If it is a br tag then it should not break the segment. But you can set whether this is inline or not on the html filetype you are using. I’m away on leave at present so don’t have my laptop to be more spexific.
Thanks again for your answer, Paul. It is indeed a <br> tag and for some reason it’s breaking the sentence. If I escape it, Studio segments the string in 2 translation units. If I remove it Studio considers this as a full string.
Again, the html code is enclosed in the CDATA section and the html embedded content processor is active, but the <br> tag is still in the way and if I leave it as-is the full string gets ignored.
Will keep on reading to see if I find the solution, if not a manual fix will have to do.
Thanks and enjoy the time off 🙂
Ignacio
Please try what I suggested. Check that the parser rule for the br tag in the html filetype you are using is correct and inline.
No luck, Paul: the rules for the <br> tag is OK in both the regular html 5 file type and in the Embedded content processor html 5 file type; but the tag isn’t correctly process and it makes Studio to ignore the full string. It seems this one is hard to handle.
Maybe you can email me the file? Pfilkin@sdl.com
Hi Ignacio,
If you find how to make tags not splitting the file, please share!
I want the exact opposite.. i would like to have different lines when a tag is found.. 🙂
trying to find out how to change this behavior!
Hi JC. The problem for Ignacio was segmentation rules and not tags. We changed the rule to not split on colon and he was sorted. If you want to split on a tag then you just need to make the tag structural and not inline.
Hi Paul, thank you for your reply!
i’ve tried to change the BR tag (Options – File Types – HTML 4 – Parser – BR) to Structure, but with no sucess.. it does not split the segments..
I’m trying with Regular Expressions on the Segmentation rules, but still no luck..
Not sure if the BR tag is the same as the tags that can be found on HTML documents…
Can you send me your file? pfilkin@sdl.com
Hi everyone,
After sending the file to Paul, he confirmed that it was working!
Which led me to the cause i was unable to split the segments by the break tags.
Since i was working on a project that was imported from an old version of Trados, it did not work.. after creating a new project, everything was working as i wanted.
so, basically the solution is the one Paul gave me:
Options – File Types – HTML 4 – Parser – BR – change to Structure (instead of inline)
Options – File Types – HTML 5 – Parser – BR – change to Structure (instead of inline)
Just to share! hope this helps!
A big thank you to Paul for his help! 🙂
Hi Paul,
I have a question about exporting a custom file type. If I create one on one computer and want to copy it to a different computer within a network, how do I get it there? Or if I install a programme that has its own file type, e.g. Excelling Studio, how do I get the file type to other machines without installing the programme on each one?
Thanks,
Vojtěch
If it’s a custom filetype you created via the UI (as opposed to using the SDK and developing it) then you export the sdlftsettings and then import this on your new machine. If it’s from the OpenExchange like Excelling Studio then you need to install it on each machine. However, if you have a lot and you have a clued up IT department then you could use an application called Octopus Deploy to push them out altogether. See this article.
it’s really fantastic way, i have applied it and worked successfully, but there is something not good with me, there is some entities that i don’t want it to be shown but i want to make it as tags , like > and < i tried to make it as embedded content with regular expression but didn’t work its content like the following:
so i make attribute in parser like //problem/@markdown to open markdown but gt and lt and #10 as i said to you.
Probably just need to make sure you have set entities to convert. Doesn’t sound like anything you need to handle with regex?
Hi, and what about to block the entire CDATA section? how can I do that?
Maybe something like this would work for you… I’m guessing your scenario a bit… so take a file like this:
<?xml version="1.0" encoding="UTF-8"?>
<rootelement>
<cdata>
<![CDATA[<p>I don't want to parse</p>]]>
</cdata>
<cdata>I want to parse.</cdata>
</rootelement>
I use these rules and it ignores the element with a CDATA section:
//cdata[contains(.,'CDATA')] Not translatable
//cdata Translatable but not in protected content
Hello Paul,
Thanks so much for such a detailed post. I am currently working on an XML file type definition for posts made using our CMS system, and your guide proved invaluable getting things to work.
There is one nagging issue I have not been able to fix, however — is there any way to get Studio to import text inside XML comments for translation? Apparently, our CMS has the annoying (and totally contrary to all best practices) habit of placing image captions within comments, and so far I have not been able to extract them from there.
For your reference, a typical image + caption combination in our CMS looks like this:
<div class=”umb-macro-holder mceNonEditable”><!– <?UMBRACO_MACRO macroAlias=”Image” imageImage=”23808″ imageCaption=”Image caption goes here.” /> –> <ins> <!– [if IE 9]><video style=”display: none;”><![endif]–> <!– [if IE 9]></video><![endif]–> This imports fine, but apparently it is the part inside the comment that actually gets displayed.</ins></div>
Any help would be much appreciated!
Thanks in advance,
Fran
Hmm, I just want the parser to stop creating a new TU at every typically terminal punctuation mark (. : and so on). This process seems very very thorough, but perhaps more than what I need to do? I just need to keep all text from each element in its own TU.
Hi, Paul!
I love your articles!!
I have a quick question regarding the settings used in Studio 2014. I would like to know where the settings for the file types (for example, Microsoft Word 2000-2003 or Microsoft Excel 2000-2003) are saved.
Thus, I would like to add a .sdlftsettings file and, in the case of Microsoft Word, I would like to preserve the settings without adding them into the current Microsoft Word settings but just renaming it (for instance, XXX_Microsoft Word 2000-2003). What I have done so far is export the default settings and save them on my PC, so as to count on a back-up just in case they get damaged I do not have to re-install the software.
For this, I would need to know the path to such settings, so as to just copy the filters and rename them.
Thank you very much in advance!
Kind regards,
David
Hello David,
The settings themselves are not available in the way you mention. You can save the customised part by exporting your settings for the filetype you customised and then it’s simple to back them up again that way… maybe this is really what you’re after?
You could also create a project template for your settings and then call that template when you create a project that requires the customised settings you want. This way you can have as many as you like all available within templates and these can also be saved and restored easily enough.
But beware of product updates because in settings or templates, an update to the filetype could mean you need to recreate them anyway… just depends on the amount of changes.
Paul
Hi, Paul,
very nice article about xpaths, but I have one problem with xpaths within Trados Studio 2014 which haven´t discussed.
I have XML file (xliff) contains:
….
Text
Text
Context: $lists[‘text’][“notrans”] Text
….
I tried to import only elements when elements don´t contain [“notrans”] string.
I found some xpaths like:
//trans-unit[not(contains(note,’notrans’))]/target
//trans-unit[note[not(contains(., ‘notrans’))]/target
…
But no one works. I´m not sure if the xpaths syntax are wrong (I don´t think so) or Studio doesn´t support “contains” expression. Please, could you help me?
Thank you very much.
Marek
Hello Marek,
Unfortunately I need to see the xml to help with this properly. You need to escape markup in these comments using entities as explained in this article.
In the meantime perhaps this article would also be useful as it’s specifically about XPath.
You could also try this community where there is a forum dedicated to the use of regex and xpath in Studio.
Paul
Does an “XML for dummies” exist? Came here trying to understand what is XML, but this, as you warned, was an onslaught. I know this ia very basic question, but why is the purpose of working with an XML? Is there an advantage to working with an XML vs. docx or html for instance?
Maybe the best place to start is here, w3schools. And here’s a good article on why use XML. Hope that helps.
Hi Paul,
Thanks for an extremely illuminating article! I’ve tried tinkering with my file type definitions but there’s one peculiar thing I haven’t been able to fix. I have a client who often sends me XML files where all tags are formatted using HTML entities (& lt ; b & gt ; – only without the spaces). Studio doesn’t recognize these as tags, seemingly no matter what I do. Could I use the above process to help Studio recognize these as non translatable content? Thank you so much in advance!
Best,
Ida
Hi Ida, Studio should recognise these if you use the html embedded content filter. So don’t use the legacy xml filetype. If use the legacy then you’ll need to create rules for these with regular expressions, where as the html embedded content processor should pick these up. If that is still not working then I’d recommend you post into the SDL Community and provide an example of your filetype so we can help you more efficiently.
Thank you!
Hi Paul
The basic way Studio works is that it replaces the content of a translatable element or attribute by the target text.
I now received an XML from a customer where the source text and the target text are in different elements, which means Studio would need to put the target into a different element. Is this possible?
Walter
Hi Walter, no this is not possible. The solution would be to use regex to copy the source text into the target elements and then set up the filetype to handle the target as translatable. The exception to this would be languages where you can automate the xml:lang attributes to be based on a target language.
Love the warning! 🙂
Hi Paul,
As somebody else said: Thanks for an extremely illuminating article!
I wonder if you could help me and send a link on where I could find a solution for my issue using a proper custom XML filetype, please.
Even after reading the whole article/deep explanations I couldn’t get a good and protected sdlxliff file to translate in my Studio 2014.
I received an xlm file where the only things I actually need to translate are the texts inside the section? Please, see example below.
I just need to extract and translate the content inside and protect everything else – including the html tags: , , etc which are inside the
I could try to explain all my attempts to create the custom rules but it would be too long.
Thanks a lot!
Walter
Using Cable Supports
Introduction to Cable Supports
Introduction to Cable Supports
<![CDATA[
In order for the cables to be run through a structure, they must be supported. This is where a cable support is advantageous. A cable support is a device that supports cables by equalizing tension throughout the cable.
The following are examples of cable supports:
Raceways
Conduits
Cable trays
J-hooks
Ceiling support
]]>
Hello Walter, I think you probably need to “fix” your code before posting into here. See this post. But you can email me the file if you like… pfilkin@sdl.com
Hi Paul, sorry I meant to send this:
<label>Using Cable Supports</label>
<metadata>
<file href="metafilesmetadata_4E9C20524153210B67531302001BF7E6.xml"/>
</metadata>
<children>
<item identifier="OutstartEvo_4E9C20524153210B676C130B001BF7F0" page="false">
<label>Introduction to Cable Supports</label>
<metadata>
<file href="metafilesmetadata_4E9C20524153210B676C130B001BF7F0.xml"/>
</metadata>
<children>
<description identifier="OutstartEvo_4E9C20524153210B69071301001BF7FA" >
<label>Introduction to Cable Supports</label>
<metadata>
<file href="metafilesmetadata_4E9C20524153210B69071301001BF7FA.xml"/>
</metadata>
<content><title><![CDATA[Introduction to Cable Supports]]></title><text><![CDATA[<P>In order for the cables to be run through a structure, they must be supported. This is where a cable support is advantageous. A cable support is a device that supports cables by equalizing tension throughout the cable.</P>
<P>The following are examples of cable supports: </P>
<UL>
<LI>Raceways</LI>
<LI>Conduits</LI>
<LI>Cable trays</LI>
<LI>J-hooks</LI>
<LI>Ceiling support</LI></UL>]]></text></content>
Hi Paul, I think I’m doing something wrong… I did all the steps but i have a little problem: the xml file doesn’t recognize the File Type Identifier when I open it. I tried with some root elements which appears in the file, but there’s no way.
Can I select the identifier on my own?
Hello Emilio. To be honest I don’t really understand your question. I think it would be better of you posted it into the SDL Community where you have better features for explaining the problem and I’ll have a better way to answer you too.
You’re a beast, Paul! Thanks so much for this lifesaver-post and for your ongoing extremely valuable contribution to the community!
Thanks Jan… much appreciated.
Wow, this has been incrediby helpful!! Thanks a lot.
I am encountering a little problem, though. I have some XML files which start with this line:
Yeah, utf-16 in 2020, right? I know, but it is what it is.
When I use the default XML analyzer the files are displayed in Trados’ editor correctly. However, if I use the newly XML analyzer created following this guide, when I open the file in the editor, all the characters are Chinese ideograms!
I have to change the encoding (the text in the xml tag) to “utf-8”, and load it again in Trados, for it to be displayed correctly.
Any idea why is happening this, and how to solve it (without having to manually modify the file)?
Thanks a lot.
Hi Marcos, on the missing example read this post. On the encoding problem… maybe the file is simply incorrectly encoded for the chars you’re working with in which case you’ll have no option but to change it. Perhaps this tool will be helpful as you can easily do hundreds of files in one go?
Ok, thanks a lot again, Paul. I needed both the CDATA html parsing and the attribute translation, so this has saved me a considerable amount of trouble.
I noticed the disappearing line, but I couldn’t edit the post.
Have a nice day!