
I’m back on the topic of PDF support! I have written about this a few times in the past with “I thought Studio could handle a PDF?” and “Handling PDFs… is there a best way?“, and this could give people the impression I’m a fan of translating PDF files. But I’m not! If I was asked to handle PDF files for translation I’d do everything I could to get hold of the original source file that was used to create the PDF because this is always going to be a better solution. But the reality of life for many translators is that getting the original source file is not always an option. I was fortunate enough to be able to attend the FIT Conference in Brisbane a few weeks ago and I was surprised at how many freelance translators and agencies I met dealt with large volumes of PDF files from all over the world, often coming from hospitals where the content was a mixture of typed and handwritten material, and almost always on a 24-hr turnaround. The process of dealing with these files is really tricky and normally involves using Optical Character Recognition (OCR) software such as Abbyy Finereader to get the content into Microsoft Word and then a tidy up exercise in Word. All of this takes so long it’s sometimes easier to just recreate the files in Word and translate them as you go! Translate in Word…sacrilege to my ears! But this is reality and looking at some of the examples of files I was given there are times when I think I’d even recommend working that way!
But there were files I saw that looked as though they should be possible to handle in a proper translation environment. We tested a few and the results were more often than not pretty poor. So even though we could open them up it was still better to take the DOCX that Studio creates when you open a PDF and then tidy up the Word file for translation. At least this is some progress… now we’re able to handle the content in a translation environment and not have to recreate the entire file. But it would be even better if the OCR software could make a better job of it. And this is where I want to get to… better OCR!
SDL Trados Studio 2017 continued to provide the same PDF filetype that uses technology from SolidDocuments in earlier versions of Studio, and this does a fairly good job of extracting the translatable text with OCR for many files. But it could use improvement. SDL Trados Studio 2017 SR1 has introduced another option for OCR using a software called ReadIris that is part of the Canon Group.
Out of the box, according to the documentation, Iris supports 134 languages for OCR which is pretty impressive. They don’t quite match the languages supported by Studio however, but a rough count and compare suggests there are some 95 shared languages… and they even support Haitian Creole which Studio does not as we know 😉 Still impressive however and it easily beats the 14 languages supported by Solid Documents in Studio 2017 prior to the introduction of Iris. Additionally this opens the possibilities for handling scanned PDF files in Asian languages, Arabic, Hebrew and many others that were previously difficult, if not impossible, to handle.
Using the new options
So let’s take a look at where you can find this new option and how you use it. First of all you need to go to your options:
File -> Options -> File Types -> PDF
Then navigate down to “Converter“. Down near the bottom you’ll see the “Recognize PDF text” group as shown below and the option to activate this new feature is at the end:
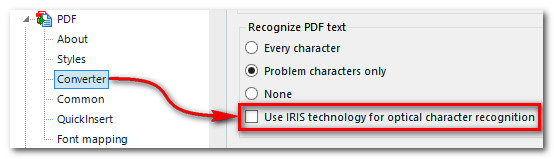
Check the box and you’ll be presented with this screen:

It’s an App! You may be wondering why you need to do this and why it was not just integrated into Studio? The reason is simple… not everyone will want this option and the underlying software requires a 150Mb download which would have increased the size of the Studio installer to over half a gigabyte. So it was made optional. If you want it you click on the “Visit AppStore” link in the message above, or the one I just wrote, and download and install the plugin just as you would any plugin from the appstore. If you don’t do this then Studio won’t be using the software. There are no warnings, and the option remains checked, but you won’t be using it. So when I open the Chinese PDF I just created by copying some text as an image and saving it to a PDF all I’ll get is this:
![]()
None of the text is extracted for translation at all. But if I install the plugin and try again I see this:
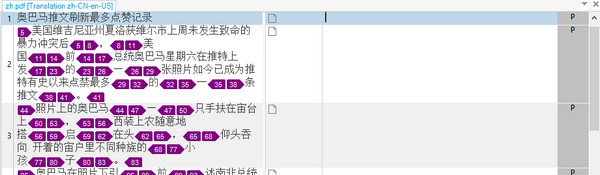
Now we’re cooking! Would be useful to get rid of the tags though as these seem to be aesthetic only, just colours and font changes where the OCR picked up a few minor differences and then introduced tags to control them. As these are formatting tags only I could just ignore then, or press Ctrl+Shift+H to hide them in the editor. But if I want to remove them altogether I can do this with another app. called Cleanup Tasks that I have written about before. These three options do the job for this file:
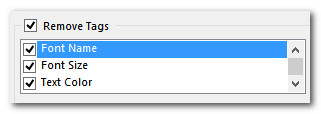
Now I have this and can translate without any tags at all:

Nice… and if all of that sounds complicated it wasn’t really. I created a short…ish video below putting this all together so you have an idea of how it works.
Approx. length : 16.26 mins
After all of that I don’t want you to get the impression I’m a converted believer in the possibilities of PDF translation… I’m not. We’re unlikely to see the back of PDFs for translation any time soon, so I am happy to see the technology to support this workflow improving all the time. I also don’t want to give the impression this is going to help with every PDF you ever see. It won’t! The problems of PDF quality don’t go away because of the way they been created in the first place, so source is always best. You’re also quite likely to find PDFs you can’t handle even with Iris, and you might even find that the more basic option without Iris does a better job of your PDF conversion. So it’s horses for courses… you have the tools and can apply the most appropriate one for your job.
If you have any questions after reading this post or watching the video then I’d recommend you visit the SDL Community and ask in there… or just post into the comments below.
unfortunately, the sound is so low and undistinct, that I hardly can hear anything of this video
Sorry to hear that. The video is on youtube and when I turn up the sound in the video and my speakers it’s not too bad at all… too loud for full volume in fact. Perhaps you should just check that you are not listening to the video with some of the audio options set too low?
Hello,
Could you please explain when/why/how “the more basic option without Iris does a better job of your PDF conversion”?
Thank you!
I’m afraid I have no idea. But don’t forget this was the plain text conversion and not the scanned image PDF where the basic conversion extracted nothing at all. I think all converters have their quirks and I’m no expert in conversion technology. For me it’s enough to know that there are a couple of choices and I’d use the one most suitable for the task.
In fact, what part are you referring to? The EN PDFs are all better with IRIS. Is the ZH text based PDF better with the basic OCR tool?