 AdaptiveMT was released with Studio 2017 introducing the ability for users to adapt the SDL Language Cloud machine translation with their own preferred style on the fly. Potentially this is a really powerful feature since it means that over time you should be able to improve the results you see from your SDL Language Cloud machine translation and reduce the amount of post editing you have to do. But in order to be able to release this potential you need to know a few things about getting started. Once you get started you may also wonder what the analysis results are referring to when you see values appearing against the AdaptiveMT rows in your Studio analysis report. So in this article I want to try and walk through the things you need to know from start to finish… quite a long article but I tried to cover the things I see people asking about so I hope it’s useful.
AdaptiveMT was released with Studio 2017 introducing the ability for users to adapt the SDL Language Cloud machine translation with their own preferred style on the fly. Potentially this is a really powerful feature since it means that over time you should be able to improve the results you see from your SDL Language Cloud machine translation and reduce the amount of post editing you have to do. But in order to be able to release this potential you need to know a few things about getting started. Once you get started you may also wonder what the analysis results are referring to when you see values appearing against the AdaptiveMT rows in your Studio analysis report. So in this article I want to try and walk through the things you need to know from start to finish… quite a long article but I tried to cover the things I see people asking about so I hope it’s useful.
But first things first… is it free or do you have to pay for it? The answer is yes and no because there is a free plan as well as several paid depending on how much machine translation you intend to use. I’m just going to mention the free stuff, so here’s what you get:
- 400,000 machine translated characters per month
- only access to the baseline engines, so this means no industry or vertically trained engines
- 5 termbases, or dictionaries, which can be used to “force” the engine to use the translation you want for certain words/phrases
- 1 Adaptive engine
- Translator… this is basically a similar feature to FreeTranslation.com except it’s personalised with your Engine(s) and your termbases
The paid versions step up through four levels, Basic, Advanced, Expert and Specialist before you get to an option to train your own engines that can be used with Language Cloud. Prices start at $10 per month for the Basic, and go up to $90 per month for the Specialist. The custom engines need a qualified quote based on what you’re looking for so you would contact SDL for that one.
Now that we’ve got that out of the way I’ll just mention that these prices won’t be set forever, and the websites change from time to time, so I’m going to suggest you check on the SDL Trados website by looking in the Products section and SDL Language Cloud. There will always be updated information in there.
Now, if you’re only interested in the reporting and analysis then scroll down to the bottom… otherwise I’m going to take you through what you get with a Language Cloud account as a new user.
Contents
The process in Studio!
Your account
Now we think we’re good to go so let’s take a look at what’s in Studio. When you first purchase Studio and have never taken advantage of SDL Language Cloud before you should go to your File -> Language Cloud where you’ll see the details of your account. If you’re a new user it’s going to look something like this:
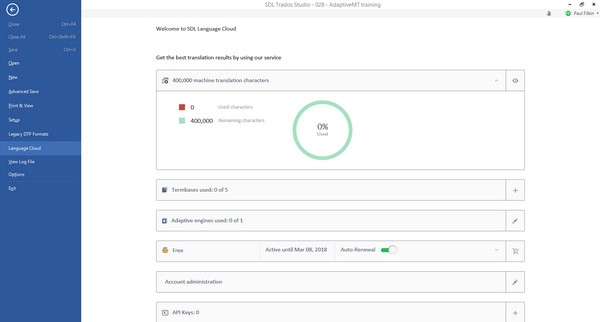
I know the image is small, but basically what it’s telling me is that I’ve got the Free package. I can expand this in Studio and at the time of writing with a brand new account you can see what this gets me:
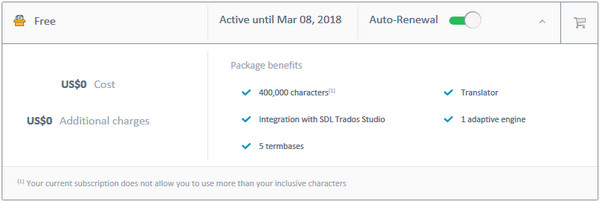
The overall dashboard is quite nice, shows me all the things I need to know in a simple way and from within Studio. If I want to see more detail and interact with the account I can click on any of the little icons on the right of each item and I’ll be taken to the SDL Translation Toolkit where I have a number of interesting views, or I can go to languagecloud.sdl.com and see the same thing:

I’m not going to go into these in detail in this article, so I’ll just summarise what each view gives you:
Dashboard
This is basically a mirror image of what you see in Studio. You do get a couple of additional items:
- Translator: this is your personal web translator similar to Google Translate or DeepL, but it uses your personal trained engines and termbases. It’s quite handy because you can throw whole files in there and get them back translated for a quick gist without having to run through Studio. This will use up your character allowance so keep this in mind if you find it useful, and you might because it’s surprisingly fast! Nice opportunity though if you have a client who provides material based on quality work you do for them and occasionally just wants a quick gist for less important material. You can charge less, drop it through your engines, and in seconds give them machine translated documents that could well be good enough. An interesting way to supplement your income and keep your clients happy too.
- Application Keys: if you are developing applications that use the engines in your account then the applications would use the unique Application Keys that you create for identification.
- Sandbox mode: this switches your account into one that can be used to test applications you have built as a developer, so you can test them without eating into the allowances you have for your business
The rest are the same as in Studio and quite explanatory. I’ll just mention the API Keys though. The free account allows you to create one API key which is a very useful feature you may not have known about. When you log into LanguageCloud it’s possible to do this using an API key instead of your account details. This means you can share your trained engines with others by allowing them to log in with your key(s). Very nice! You can find more information on how to do this in this KB article.
Resources
- Termbases: in here you can create new termbases/dictionaries, edit them, see all the termbases you’ve got, what languages, who owns them, who they are shared with and you can of course purchase the ability to increase the number you own
- Machine Translation Engines: gives you access to your Adaptive engines, Industry engines and the Baseline engines all depending on the type of account you own
This is probably a good place to mention the language pairs available. At the time of writing this article (9th Feb 2018) this is what’s available in the Baseline engines:
Western Europe: 69 pairs
Eastern Europe: 15 pairs
Middle East & Africa: 10 pairs
Asia: 11 pairs
In the Industry specific engines:
Automotive: 14 pairs
Electronic: 10 pairs
IT: 8 pairs
Life Science: 7 pairs
Travel: 13 pairs
Printer Hardware: 4 pairs
For AdaptiveMT I’m going to list them as this is what the article is all about and I often see people in the community wondering why AdaptiveMT is not available in their language pair. So this is what’s available today, 16 pairs:
English <-> French
English <-> German
English <-> Italian
English <-> Spanish
English <-> Dutch
English <-> Portuguese
English <-> Japanese
English <-> Chinese
Sometimes we English speakers don’t know we were born! If you want to keep upto date on this you need to check the SDL websites. Currently you can find this information, including the specific languages I didn’t mention for the Industry and Baseline engines in the Language Pairs page.
Analytics
On this part of the page you’ll find interesting ways of analysing your usage. Very useful if you’re wondering why you ran out when you don’t think you used it much at all! It’s broken down into two tabs:
MT Character Usage: allows you to chart your use between specific dates, specific API keys (essential if you allow others to use your account), specific Engine, specific domain, specific language pair. The results are instant on screen, but you can download the reports as a CSV or a PDF.
Other stuff
Just to finish this section of the article, you’ll also find links to your account, different language UI in the usual SDL languages, the Translator and help! The help is good for users and developers alike. All in all this is quite a handy view and worth checking this from time to time as I expect to see more features being added over time as the Language Cloud becomes more of a hub for everything SDL provides in this sector. This article from Daniel Brockmann makes an interesting read if you want to know more about the future… or depending when you read this to see if he was right! But back to the present…
Using AdaptiveMT in Studio
The first thing is you just add it as a Translation Provider either through File -> Options or your Project Settings depending on what you are trying to achieve. As long as your language pair is a supported Baseline Engine then you’ll be take to a screen similar to this:
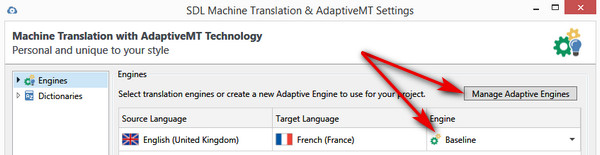
The drop down by the Baseline allows you to switch to one of your customised or Adaptive engines. As a new user this is going to be empty until you create one, and to do that you click on Manage Adaptive Engines. I’ll come back to that in a minute because I also wanted to mention that you can also select your preferred Termbase/Dictionary in this screen by clicking on Dictionaries:

Mine are empty because I’m new! It’s worth noting however that if I did have a Termbase in my list then I can also use this with the baseline engines so even if my language pairs are not supported for AdaptiveMT I can still customise the results from the Baseline engines in this way. I’ll also mention that the amazing Glossary Converter on the appstore has an option to create the termbases/dictionaries in the format you need with just a drag and drop.
Back to AdaptiveMT… to create your engine click the button that says New Adaptive Engine and give your engine a name, and select the correct language pair:

Note that selecting English (United States) doesn’t mean you can only use it for this variant. The engines don’t care about the 94 variants of English in my version of Studio… English is English! It’s the same for Chinese, Dutch, French, German, Italian, Japanese, Portuguese and Spanish… interestingly Japanese is one of the few languages these days with only one variant. But guess this proves that Mox is wrong as it would explain where English gets all it’s words from and we better start to see variants in the MT too 😉
Once you’ve done this and clicked on OK you can select your new AdaptiveMT engine from your settings:
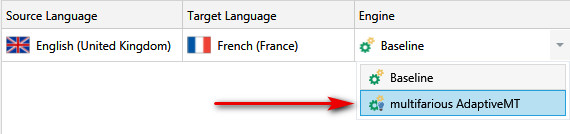
Note that it has a little lightbulb next to the icon. This lightbulb will be next to the AT symbol in the Translation Results window indicating that the translation has come from your Adaptive engine. It doesn’t appear if you are set up to use AutoSuggest from the machine translation… but don’t worry, the results are coming from your AdaptiveMT engine:
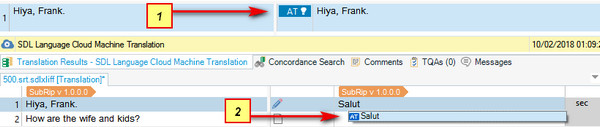
At this point I have not done any translation at all, so the results I’m seeing are coming from the Baseline engine. This is my starting point and as I translate, correcting the Baseline results simply by confirming the work after editing the target, my Adaptive engine should start to adapt, and should learn from the changes I’m making. The theory being that in time the results I’m presented with will require less editing. Normally with a non-adaptive engine it goes on making the same mistakes time and time again and never learns at all. Perhaps we should call these non-adaptive engines “academically challenged” engines!
So, how does it learn? It starts from here as you’ll notice that normally it’s not possible to update the MT providers in your settings. When you use an AdaptiveMT engine you can choose to Update or not. Obviously it’s not going to learn if you don’t update it, but there may be times when you want to work with your Adaptive engine and not send your corrections to train it:
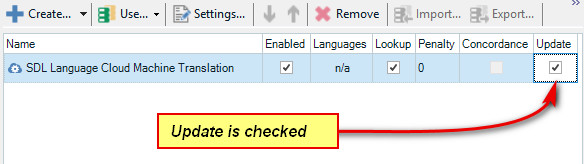
I’m sending my corrected translations to the cloud!!
Questions that come up quite often are how secure is this, can anyone else benefit from my work, is SDL going to benefit from my work? All good questions and I’ll answer the last one first. If you have a paid account then yes, SDL will benefit financially for providing you with these machine translations and a feature capable of learning to improve your productivity. I think that’s a fair deal! But to answer these questions specifically I’ll quote what it says on the SDL website:
Is my content safe with Language Cloud Machine Translation? With SDL Language Cloud Machine Translation you can rest assured that your content is safe. SDL guarantees that your data is not saved or used outside of the scope or timeframe that is necessary to provide you with the service. For more information, please refer to the SDL Language Cloud Terms & Conditions.
What content is used to train the SDL baseline engines? SDL uses data available in the public domain and the data used is never reproduced in its original form. The MT vertical engine is created from a derivative of the original parallel segments data. As this is a derivative of the original data, it does not infringe on any Intellectual Property. The data is neutralized before the vertical is created to remove product names and other client-specific references, thereby maintaining neutrality.
I often think that a more pragmatic answer is why would SDL use the data updated by translators they don’t know, for subject matter that is unclassified by domain and completely unreviewed? If they did, the risk of lowering the quality of the baselines engines could be quite high.
I’m not going to go into the details of how you use it when translating as that would be something more related to using Studio in the first place, or a discussion around whether it’s better to post-edit or to use the MT interactively through autosuggest. All interesting topics for discussion amongst translators, but outside the scope of this article. Suffice it to say that you use the AdaptiveMT engine in the same way you would use a Basline engine, Google Translate, DeepL or any other MT provider in Studio. The difference being that this one learns from the work you do.
Using previously translated material
Before I get to the analysis this brings me onto another interesting topic. If you’ve got hundreds of thousands of previously translated projects can you use them to train these engines? This topic has come up fairly often, and in recent months there was a fair bit of interest in trying to write an AutoHotkey script to achieve this capability. Well the short answer is no you can’t do this out of the box and this is because Adaptive engines were built to train interactively. So there is no import mechanism for adding previously translated bilingual files or Translation Memories. Attempting to solve this problem via AutoHotkey to automatically confirm translated segments that were in existing projects as if you were doing the work from scratch proved very difficult because of the need to wait for a response from the engine and various other things that required a deeper integration than mimicking keystrokes.
 I’ve no doubt that an accomplished AutoHotkey developer could have done it in time, but we decided to take a different approach and develop a plugin that can handle this for you. You can find this on the SDL AppStore along with a description of how it works. It’s called the AdaptiveMT Trainer.
I’ve no doubt that an accomplished AutoHotkey developer could have done it in time, but we decided to take a different approach and develop a plugin that can handle this for you. You can find this on the SDL AppStore along with a description of how it works. It’s called the AdaptiveMT Trainer.
The plugin supports you choosing multiple projects from the Projects View in Studio and selecting a command from the right-click menu. Once started the plugin will systematically work through each file one at a time, working through all the files and all the projects until complete. At the end you are able to train your Adaptive engine without having to sit there manually working through file after file of things you’ve already translated.
The only drawback is that if your projects are large you probably need to leave this running on a different computer or do them overnight. A simple guide to help with deciding how many to train in one session, or to estimate how long it will take, would be this:
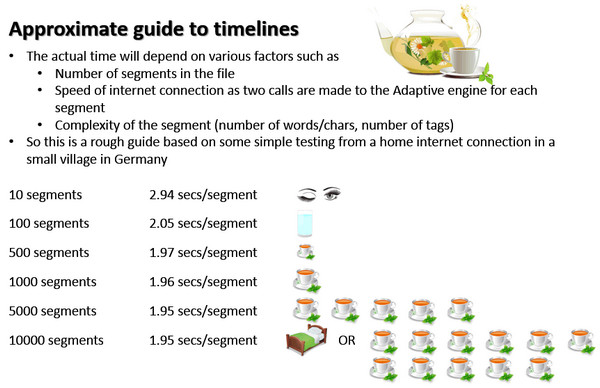
Best to review the details in the appstore, but I’d be interested to hear about your experience with this plugin? You can also find a very useful wiki article in the SDL Community created by the appstore team which has more information on this plugin and some “geeky” bits!
Update 07 Feb 2019
To avoid any misunderstanding if you have not understood what this means. The AdaptiveMT Trainer app is mimicking the manual process. So it will deduct characters from your allowable quota as it works.
Finally… we can talk about the score!
I analysed my test project after training my Adaptive engine with the AdaptiveMT Trainer plugin from the appstore, no Translation Memories in use, only the Adaptive engine. The analysis results were as follows:
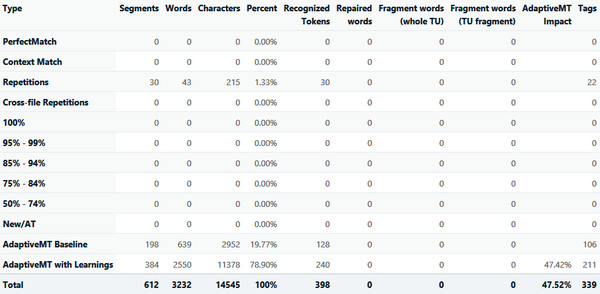
There were some repetitions in the file and these are reported, but everything else is empty apart from the last two rows. You may wonder why the New/AT is empty and this is because it’s reporting anything that is not found in your TM that will need translating by the Translator manually or through the use of machine translation and it only gets populated in this scenario if you are not analysing the “effectiveness” of the AdaptiveMT. So in this example if I ran the analysis without the Adaptive engine and just used the Baseline then I would see 612 segments in the New/AT row as opposed to 198 in the AdaptiveMT Baseline and 384 in the AdaptiveMT with Learnings rows.
You’ll also note that there is an additional column relating to AdaptiveMT called AdaptiveMT Impact. So three new things in the analysis (I say new, but this has been around for some months already… I’m a bit late with this article!) and I think it makes sense for me to try and explain the principle of this analysis and then their meanings will probably, hopefully, just fall out!
The principle is that the analysis is trying to give you an idea of how much impact your AdaptiveMT engine is going to have on the amount of post-editing required. It is of course assuming that the changes made by the AdaptiveMT engine will be better, and there is no guarantee of that, but lots of lots of testing and practical applications of it suggest that in general it is improving the output so I think it’s a good indicator and allows you to see whether or not the work you are doing on a daily basis is contributing to it. The more you translate and review, updating the engines, the higher the impact should be.
Now we understand that let’s look at these three things more closely.
- AdaptiveMT Baseline: when the file is analysed the segments that are not changed when comparing the result from the Baseline MT with AdaptiveMT are reported in this row
- AdaptiveMT with Learnings: when the file is analysed the segments that are changed when comparing the result from the Baseline MT with AdaptiveMT are reported in this row
- AdaptiveMT Impact: this is the calculated impact that the adapativeMT engine has had on this project. It’s calculated by using an edit-distance approach that identifies how many changes were necessary to adapt the result from the Baseline engine into the one from the AdaptiveMT engine on a segment by segment basis. The results are then used to calculate a percentage that can be used as an indication of how effective your Adaptive training is in giving you a different result to the Baseline. The idea of course is that this different result will be better!
In my example the 47.52% impact is quite encouraging in terms of how much the Adaptive engine has adopted my translations for future work. Certainly it’s adapting!
Coming to the end of the article it all feels a little flat after I wrote so much on how to get started and so little on the scoring itself, but I hope I managed to clear a few things up for most users on how to use AdaptiveMT, how to train it from previously translated projects, and how the analysis report is read. I think if you have questions after reading this a good place to post them is into the LanguageCloud forum in the SDL Community as this will allow people far more qualified to answer the tricky questions than I am!
As always, your post is very interesting and useful. Since the free version only allows 400,000 machine translated characters per month, shouldn’t it have access to industry or vertically-
trained engines?
Surely the system would benefit from the work of independent specialized translators who own and have paid for the translation software that they use, professionals who don’t have corporate-type income that would allow them access to that feature.
SDL don’t use your translations so I’m wondering how the system would benefit from your work? Or am I misunderstanding your comment?
It was I who misunderstood, Paul.
It’s these long articles!!