 Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Target Language Segmentation
The first place to start is probably a discussion around target language segmentation as I think most users won’t be aware this is even possible… unless of course I was the only one who didn’t know this! When you create a Translation Memory, or a Language Resource Template you are always given the ability to select the source OR the target language when you set up your segmentation rules. It’s not technically AND/OR but you can set rules for both… and shame on me for never realising this.

This is incredibly important to know because when you align files, or retrofit files you always segment the target language files too, and the segmentation rules will be based on the Studio defaults unless you specifically set them in the TM being used for your project, or for your alignment. Actually for me this is big news because one of the problems of dealing with the current alignment module is poorly aligned files, so getting the segmentation rules right in the first place could really go a long way to improving its use. To illustrate this I’ll take a small example of a poorly prepared source file that required custom segmentation rules to begin with.

Here the author didn’t use Word automatic numbering and has manually added the numbering, so as a result the numbers are brought in with each sentence when you use the default rules. So I created a custom rule for the source and this separated the numbers so I can copy source to target, confirm them and lock them, then just hide the locked segments so I have a nice clean document to translate. If you wondered how I did that part perhaps watch this video… it is Studio 2011 but the process is the same. So now let’s jump to the future where the translation is complete and look at a couple of examples of what happens when you don’t know about the ability, or need, to use similar custom rules on the target language part of the TM.
Alignment
Starting with Alignment, let’s try and align my translated file with the original source using the TM that only contains the custom rules on the source language which could well be the norm for most users creating segmentation rules for their Translation Memories:
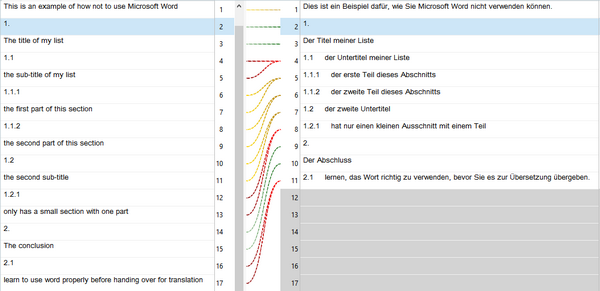
The alignment is going to be tricky because you end up with no custom segmentation applied to the target file at all and no way to split the segments and correct them in the editor. You could delete the unwanted numbers in the target and only align the text but this is all going to be a time consuming exercise.
However, if you apply the same segmentation rules to the target language and then run the alignment you achieve this:

This is altogether a better experience and I believe probably accounts for many of the difficulties users have aligning files that should be similar, but required custom segmentation rules to properly prepare the files before adding them to a Translation Memory.
I’d also add at this point that I tested this in Studio 2015 and the custom rules are not taken into consideration at all. So both the source and the target are segmented with default rules. You at least get everything aligned correctly, but you still have to deal with numbers that you don’t really want in your TM. So Studio 2017 SR1 is really a big improvement for this operation.
Retrofit
The other example I wanted to look at was Retrofit since this is another process taking advantage of the alignment module. There is a slight difference because what we are doing here is aligning the target with an updated target, and not source with target. But it is project based so I would have assumed that the same TM used to create the original project would also be used for the retrofit alignment. To test this I created a project, using the same poorly formatted source file, and a Translation Memory containing my custom segmentation rules applied to both the source and the target language. I then translate the file and save the target, finally making some minor edits in my target file.

The original target is already segmented and I believe this is taken from the SDLXLIFF; but the updated target file is segmented based on default target language rules and not the custom rules I have in my translation memory. So the segmentation choices for Retrofit are not the same as those used for Alignment . This knowledge is useful because it’s often just as important to know why something will not work as expected and be in a position to address it. In this case by making sure you use this option to review the results in the alignment editor when retrofitting you can correct it where necessary:

Now, in this case I not only made a minor correction to the text, I actually added a new bit of structure. This results in the alignment failing when it reached segment #9 in the source. So I try again, this time lowering the quality threshold to try and “force” the file to get aligned to the end:
![]()
This gets me to segment #13:

But I still have two problems:
- The red “tolerant” alignment is actually wrong
- it’s not possible to correct it as the unaligned segments are simply not editable
This exercise seems to deliver some good news, around the Alignment module if you have source and target files, and some bad news around the Retrofit alignment. But I wanted to use this to note the importance of not making changes in the target documents for Retrofit unless they are minor edits to the text. It was not designed for handling structural changes, and if additional lines are added you’ll have nothing in the source to map them to anyway. So it might be better to translate the target file against your TM using AnyTM and add the new translations for the source, then import the SDLXLIFF into your original TM to update it as required (you can import an SDLXLIFF file with a different language direction into your TM as Studio will put the right languages in the right place).
If I only made minor textual corrections then I might see something like this:

Now the entire file is aligned. The segmentation is incorrect in the target as expected since I used custom rules for the original source and we know that Retrofit alignment doesn’t take them into account; but the alignment is actually correct. So now I can update the SDLXLIFF and everything is happy days… not quite. I now have a new surprise waiting for me:

My SDLXLIFF file has been resgmented to match the updated target and this means that when I update my TM I won’t get an updated TM that matches the segmentation of a new project using an updated source file in the future. At least I’ll only get fuzzy matches for the updated segments.
Conclusion
So the news for Retrofit isn’t great if you’re using custom segmentation rules in your TM. If you’re using the defaults it’s a great feature, but the solution for updating your TM if you used custom segmentation rules and had a lot of changes is to do the retrofit more manually and align the original source (or preferably an updated one) with your updated target file making sure you apply the custom rules for segmentation to the source and target language. I’ve no doubt there will be a fix to improve this in the future but until then forewarned is forearmed!