 I wrote under this title back in 2013 and provided a bit of information about the Word filetypes in Studio. It was a pretty popular article and I always meant to circle back and do some more. Seven is a lucky number so now we’re in 2020, seven years later, I thought I’d do it again… and it’s also just as long, so grab a coffee first!
I wrote under this title back in 2013 and provided a bit of information about the Word filetypes in Studio. It was a pretty popular article and I always meant to circle back and do some more. Seven is a lucky number so now we’re in 2020, seven years later, I thought I’d do it again… and it’s also just as long, so grab a coffee first!
The message I wanted to leave users with after that article is that it’s always worth opening the options from time to time and just exploring the filetype options, particularly for the filetypes you work with often. You never know what you’ll find in there. If you did this there is one thing you’d find that we have not been making a song and dance about, and that’s embedded content options. What do I mean by this? If you take a quick review of this article where I covered the handling of taggy Excel files you’ll know what I mean. Embedded content (in the context of this article) is usually text, programming code, or markup, that has been added to your file in such a way that it will be extracted as translatable content, but you want to protect it from translation. So you want to “tag it” which is an “affectionate” name given to protecting the code from being changed during the translation process and at the same time make it easier for the translator to work around it.
The way embedded content is handled
Today, in Trados Studio 2021, you might not have realised that over 60% of filetypes do have the ability to handle embedded content. But they don’t all do it the same way or carry the same advantages, or disadvantages depending on what the content is. In fact there seems to be two different ways this can be represented and quite a few different ways of representing where this feature is in each filetype.
To try and simplify this I’m going to split this article into three:
- handling embedded content using tag definition rules
- handling embedded content using the Embedded Content Processor Filetypes
- handling embedded content in other ways
I don’t intend to show every configuration in the options but I have identified which filetypes support each type below.
Just with tag definition rules
This approach is the same as described in the article on handling taggy files from Excel. You’ll find it under some of the filetype options like this: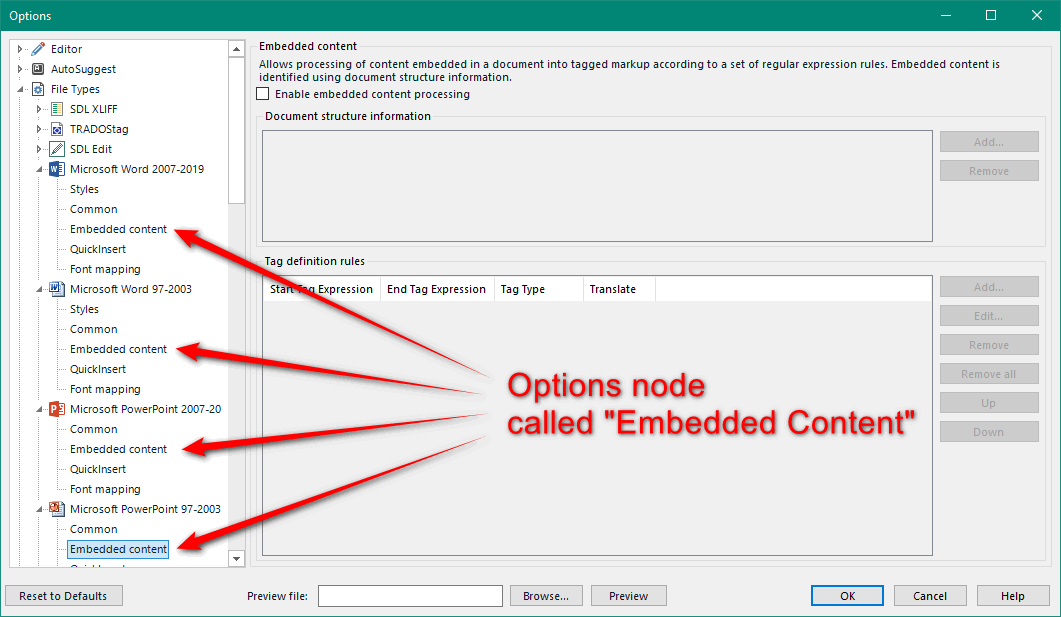
The use of this approach is quite simple. You activate the embedded content processing by checking this box:
![]()
Telling Studio which parts of the document your rules should apply to:
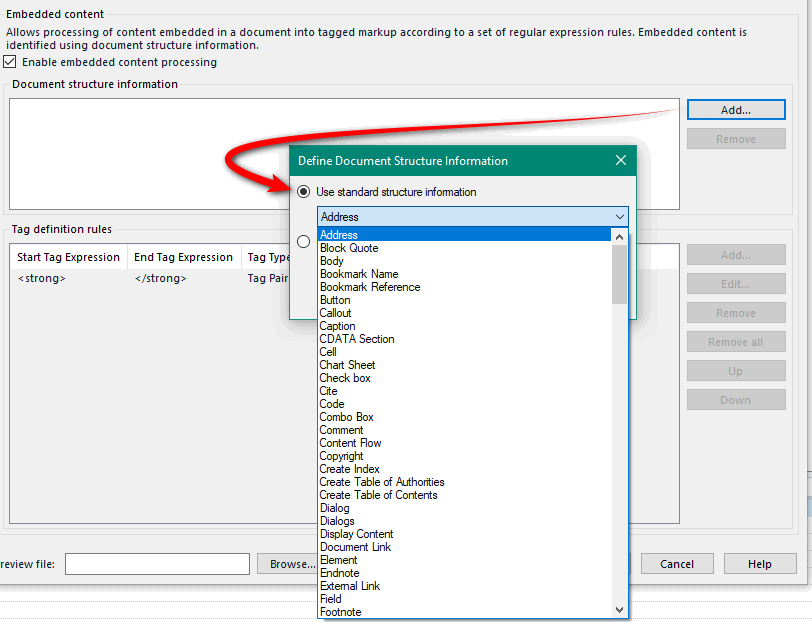
And finally adding your rules:
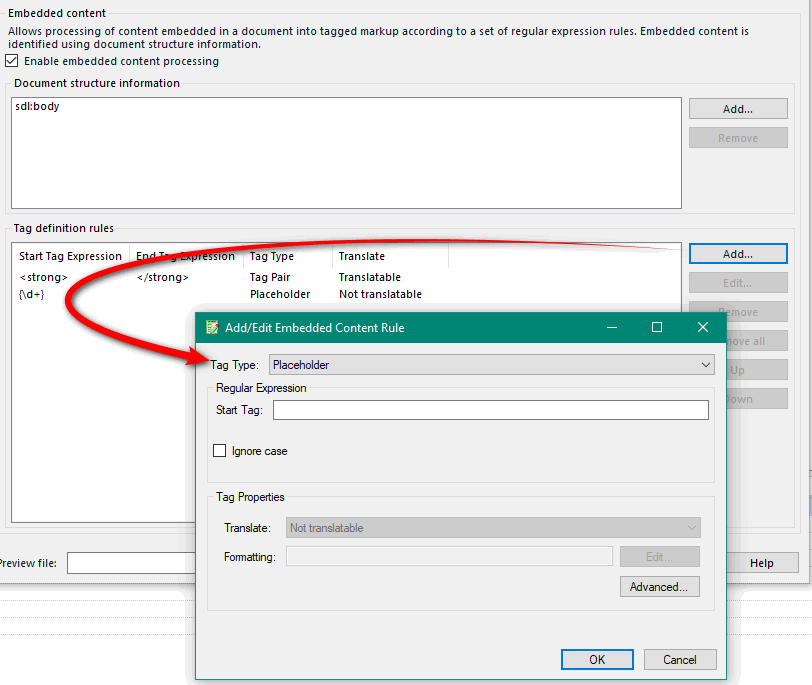
The rules can be used to define placeholders or tag pairs, and for tag pairs you can define whether the text between them should be translatable or not. So a reasonable amount of flexibility in here, but you do need to have some knowledge of regular expressions if you want to avoid having to create a lot of rules.
Affected file types
Which ones adopt this approach? These ones:
- Microsoft Word 2007-2019 (WordprocessingML v. 2)
- Microsoft Word 97-2003 (DOC v 2.0.0.0)
- Microsoft PowerPoint 2007-2019 (PresentationML v. 1)
- Microsoft PowerPoint 97-2003 (PPT v 2.0.0.0)
- Microsoft Excel 2007-2019 (SpreadsheetML v. 1)
- Microsoft Excel 97-2003 (XLS v 3.0.0.0)
- Bilingual Excel (Bilingual Excel v 1.0.0.0)
- XLIFF (XLIFF 1.1-1.2 v 2.0.0.0)
- XLIFF 2.0 (XLIFF 2.0 v 1.0.0.0)
- Java Resources (Java Resources v 2.0.0.0)
- Portable Object (PO files v 1.0.0.0)
- Subtitle formats (Subtitles v 1.0.0.0)
- XML: Author-it Compliant (XML: Author-it 1.2 v 1.0.0.0)
- XML: Any XML (XML: Any v 1.2.0.0)
- Text (Plain Text v 1.0.0.0)
- Custom filetypes
- Regular Expression Delimited Text (RegEx v 1.0.0.0)
- XML (Legacy Embedded Content) (XML v 1.2.0.0)
Using an Embedded Content Processor Filetype
More recent versions of Studio have gradually introduced the concept of chaining filetypes together. So you could open a file with one filetype, but handle the embedded content with another one. A good example of where this is really appropriate is when the embedded content is HTML with a lot of HTML syntax to create rules for. Using the HTML filetype as an embedded content processor means the markup is all handled perfectly and you don’t need to write any rules with regular expressions yourself.
This technique manifests itself in the filetypes in a few ways… so in the email filetype it’s like this under the “Common” node as opposed to “Embedded Content“:

In the XHTM 1.1 (2) filetype it’s under “Embedded Content” node:
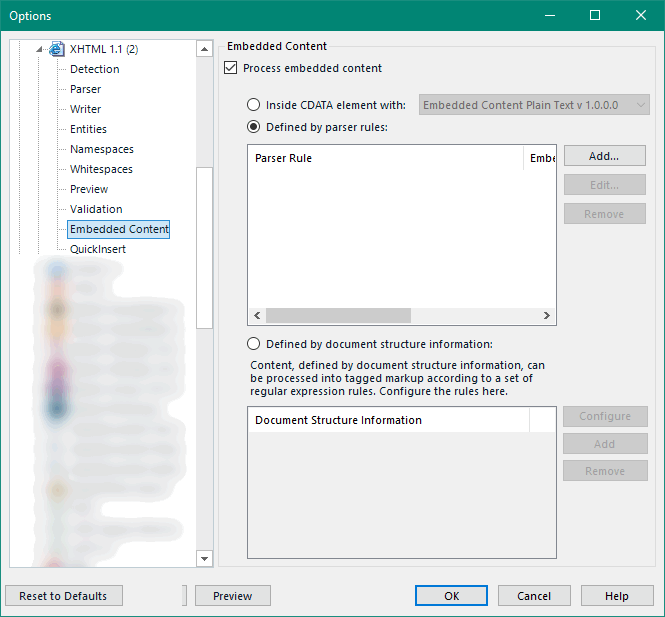
But in all cases the basic idea is the same. You select the filetype you wish to be used to process the embedded content from a drop down list similar to this:

By default you’ll see there are three options:
- Plain text
- Excel spreadsheet
- HTML
But you can have many more… as long as they are based on these defaults. To explain what I mean by this let’s close up the nodes and look again at the options:

Underneath the “File Types” you’ll see “Embedded Content Processors” where you can select and copy them to create as many as you need, like this for example:
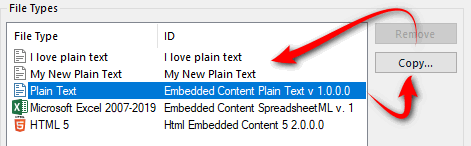
Each one of these can have different rules so that you can create your custom filetypes with unique rules to solve the particular problem you need for a particular situation. NOTE: after creating new embedded content processors they won’t be visible in the filetype for selection until you close your settings and reopen them again. But once done you see something like this:
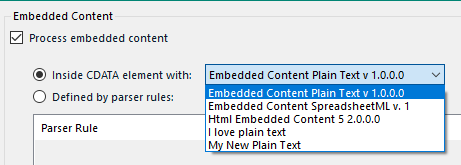
Now I can select the two new ones I just created when I’m configuring the XHTML filetype I referred to earlier.
Whilst the choice of filetypes to chain is quite limited, I think these three probably cover the majority of cases you’re likely to come across. Configuring them is simple:
- Plain text
- this is exactly the same as creating a regular expression based filetype.
- define the structure
- define the inline tags
- Excel spreadsheet
- exactly the same as described in the article on taggy Excel files
- HTML
- just refine the parser rules already provided to suit your usecase
- for most files you won’t need to do anything at all
I deliberately haven’t gone into a lot of detail here for two reasons. The first is because I think by now you’ll have got the idea and probably don’t need to know anything else, and secondly because I have covered these principles in some detail before. If you review this article on custom XML (scroll down to the sub-headings on embedded content processing) you should find what you need to know. But if there are specific questions feel free to ask in the comments below or post into the SDL Community.
Affected file types
Which ones adopt this approach? These ones:
- Email (EMAIL v 1.0.0.0)
- XHTML 1.1 (2) (XHTML 1.1 v 2.0.0.0)
- XHTML 1.1 (XHTML 1.1 v 1.2.0.0)
- HTML 5 (Html 5 2.0.0.0)
- JSON (JSON v 1.0.0.0)
- YAML (YAML v 1.0.0.0)
- Markdown (Markdown v 1.0.0.0)
- XML 2: Microsoft .NET Resources (XML: RESX v 2.0.0.0)
- XML: Microsoft .NET Resources (XML: RESX v 1.2.0.0)
- XML 2: OASIS DITA 1.3 Compliant (XML: DITA 1.3 v 2.0.0.0)
- XML: OASIS DITA 1.3 Compliant (XML: DITA 1.2 v 1.2.0.0)
- XML 2: OASIS DocBook 4.5 Compliant (XML: DocBook 4.5 v 2.0.0.0)
- XML: OASIS DocBook 4.5 Compliant (DocBook 4.5 v 1.2.0.0)
- XML 2: Author-IT Compliant (XML: Author-IT 1.2 v 2.0.0.0)
- XML 2: MadCap Compliant (XML: MadCap 1.2 v 2.0.0.0)
- XML: MadCap Compliant (XML: MadCap 1.2 v 1.0.0.0)
- XML 2: W3C ITS Compliant (XML: ITS 1.0 v 2.0.0.0)
- Custom filetypes
- HTML 5 (Html File v 2.0.0.0)
- HTML 4 (Html File v 2.0.0.0)
- XML 2 (XML v 2.0.0.0)
- XML (Embedded Content) (XML v 1.3.0.0)
A few gotchas…
Scope and specifications
Sometimes there is an embedded content option, but it can be restrictive in terms of the coverage offered. So you may need to do a little more investigative work to figure out why, if you can’t immediately see the reason, your non-translatable text is not being protected. A good example would be Markdown files (*.md).
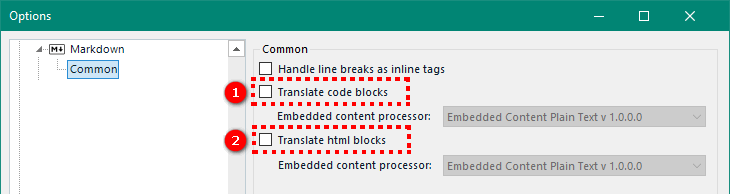
Here the only embedded content that can be processed is within code blocks and html blocks. So if you are trying to handle embedded content in a Markdown file and it’s not working you first need to check whether the content has been written inside one of these objects?
-
- If not then you have your answer… you need to handle the content some other way.
- if it has then you need to make sure that the Studio Markdown filetype understands these objects in the same way you do.
What do I mean by understanding the objects? The specification for Markdown is a little loose, and whilst I don’t believe we have documented this anywhere I think the one we follow would be this:
The rules for code blocks ( indented code blocks and fenced code blocks) and html blocks are quite well described in here. However, there is other documentation, equally valid:
https://www.markdownguide.org/basic-syntax/#code-blocks
But the problem here is that the rules in this other documentation are not as comprehensive and it’s very easy to create Markdown code that may work for the application intended, but Studio won’t see it that way. I saw a good example of this a week ago where the code block, an indented code block, worked fine where it was used. But because there wasn’t a blank line after the paragraph preceding it Studio didn’t see it that way and so the embedded content processor could not pick up the non-translatable elements.
This same “gotcha” can apply in other areas. The message I’m trying to get across being you need to investigate in more than simply Studio before concluding the embedded content processing just doesn’t work.
Document Structure
Another common problem I have come across when users try to use these features is the use of Document Structure. Studio uses the Document Structure to improve accurate leverage from your translation memory by adding context information to each translation unit you save. Take this simple example where I added some markup (<strong>multifarious</strong>) into a word document:

If I open this in Studio I see this in the Document Structure column:
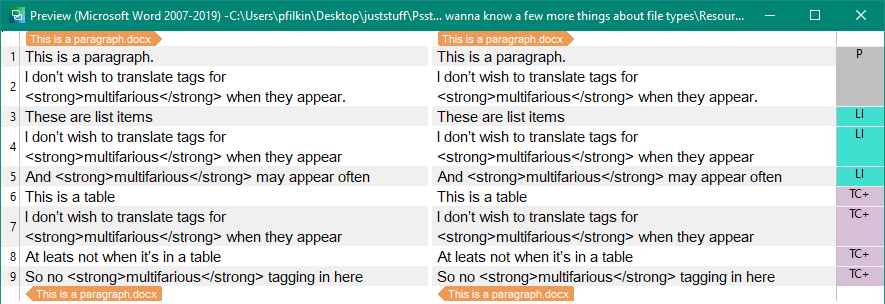
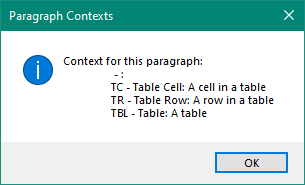
The right-hand column tells us what the Document Structure is… in this case a paragraph (P), list-items(LI) and table cells (TC+). The plus symbol after TC tells us that there is actually more structure associated to this one which I can see by clicking on it:
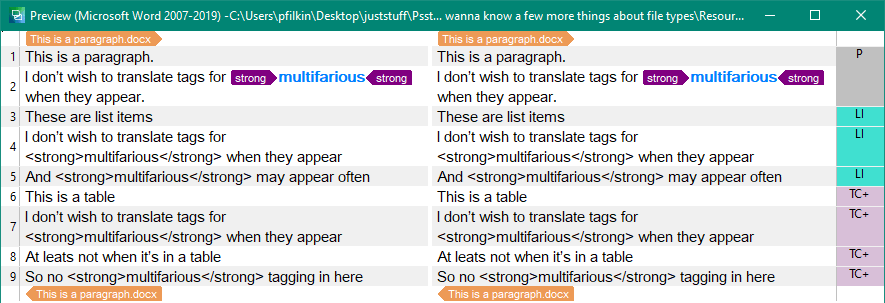
The reason this is all important is because if I create a rule for this markup I have to specify the relevant Document Structure. If I just create a rule for the paragraph then I get this:
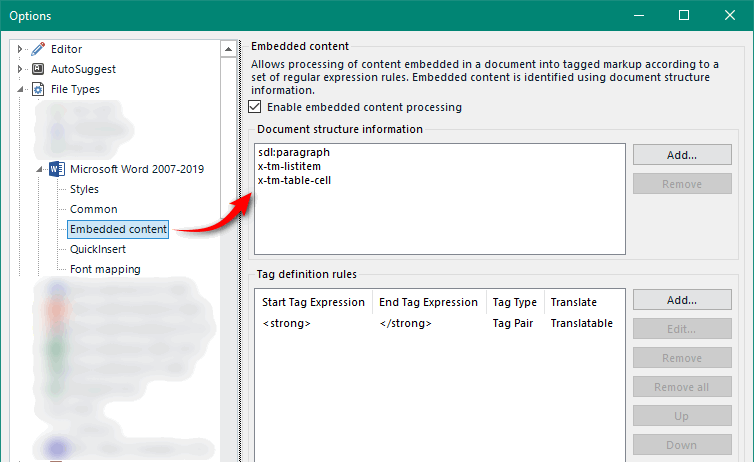
Only the segment with the Paragraph Document Structure is tagged. To get them all you need to add each applicable reference for the Document Structure:
When you do that the file will look like this:
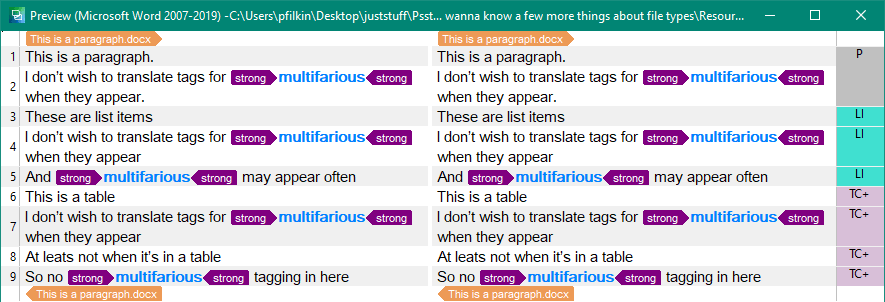
This creates two emotions in me… first of all one of relief because now I know why my embedded content processor didn’t work! And then a second emotion which is less positive because I don’t understand why there isn’t a catch all structure to ensure my rules apply globally and not just on specific parts of my file. I like that this granularity is possible because it does lend itself to more complex scenarios where you might only want to tag content in a specific set of circumstances (unlikely in my opinion… but lets be generous and enjoy the sophistication), however, let’s do something simple for the majority of use cases! I have tried testing against body and section which appear to be structural items in the underlying XML but these have no effect.
So vote for this idea! Clearly we thought it would be a good idea and it was added into the filetype options for Trados Live… so some consistency and parity across the tools would be good!
Filetype options versus Project settings
Ah yes… that old chestnut! Make sure, especially if you’re new to Trados Studio that you know where you are checking the settings you created. If you have already created your project then you cannot alter the way the text has been extracted and will need to create the project again. It’s worth reading this great article from Jerzy Czopik… Tea and Settings!
What about the ones that don’t?
If you have a need to handle embedded content in files that don’t support anything I’ve covered before then you have two options at least… translators and localization engineers have an unsurpassed ability to invent the most amazing solutions when needed so I’ll just cover the basics here:
- address the content in the source file
- use a plugin from the SDL AppStore
Address the content in the source file
One way you may be able to tackle this is through the use of non-translatable styles. By applying a specific style for content that should not be translated in the source file you might be able to use them in the file type settings to exclude the content from translation. For example:

This method isn’t always going to be helpful because you don’t have a lot of control over how the content should be handled. It’s all converted to structure tags. But if you only need to completely exclude blocks of content from translation then this can be a very effective and simple way to do it.
Use a plugin from the SDL AppStore
The best way to manage it (in my opinion), if you do need a little more control, is to address this after the project has already been created. Coupled with the improved filter capabilities in Studio this approach can be very effective. Worth noting that it’s probably not unusual to receive project packages where the person who created them had a very limited knowledge of how to work with filetypes and non-translatable content. So being able to address this after the project has been prepared is very useful indeed!
There are two applications freely available on the SDL AppStore to help with this:
My preference is for the Data Protection Suite simply because I think it’s a more robust and easier solution to use. But CleanUp Tasks does offer quite a few interesting possibilities including being able to work with tag pairs which isn’t possible using the Data Protection Suite. I don’t intend to cover these applications in this article… it’s already longer than I originally intended (my apologies, and thanks, if you’ve made it this far!)… so if you have any specific questions feel free to ask in the comments below or post into the SDL Community. I’d also be interested if there is anything related to the use of filetypes, or embedded content that you think could do with a separate article to clarify the details.
Affected file types
Which ones don’t handle embedded content using the methods above at all? These ones:
- SDL XLIFF (SDL XLIFF 1.0 v 1.0.0.0)
- TRADOStag (TTX 2.0 v 2.0.0.0)
- SDL Edit (ITD v 1.0.0.0)
- SDL Trados Translator’s Workbench (Bilingual Workbench 1.0.0.0)
- Rich Text Format (RTF) (RTF v 2.0.0.0)
- Microsoft Visio (Visio v 1.0.0.0)
- Adobe FrameMaker 8-2020 MIF V2 (FrameMaker v 10.0.0)
- Adobe FrameMaker 8-2020 MIF (FrameMaker 8.0 v 2.0.0.0)
- Adobe InDesign CS2-CS4 INX (Inx 1.0.0.0)
- Adobe InDesign CS4-CC IDML (IDML v 1.0.0.0)
- Adobe InCopy CS4-CC ICML (ICML Filter 1.0.0.0)
- Adobe Photoshop (Photoshop v 1.0.0.0)
- OpenDocument Text Document (ODT) (Odt 1.0.0.0)
- OpenDocument Presentation (ODP) (Odp 1.0.0.0)
- OpenDocument Spreadsheet (ODS) (Ods 1.0.0.0)
- QuarkXPress Export (QuarkXPress v 2.0.0.0)
- XLIFF: Kilgray MemoQ (MemoQ v 1.0.0.0)
- PDF (PDF v 3.0.0.0)
- Comma Delimited Text (CSV) (CSV v 2.0.0.0)
- Tab Delimited Text (Tab Delimited v 2.0.0.0)
- XML: W3C ITS Compliant (XML: ITS 1.0 v 1.2.0.0)
- XML 2: Any XML (XML: Any v 2.0.0.0)
- Custom filetypes
- Simple Delimited Text (Delimited Text v 2.0.0.0)
Conclusion
Like with so many of the articles I write I find that the more I start looking into a topic, the more there is to talk about and it’s really hard knowing where to stop. Certainly the labyrinth of Studio settings and file types can leave many users viewing it as a bit of a Pandora’s box. This is quite unfortunate because the best way to learn about the capabilities of Trados Studio is to explore these things. Just take a little bit at a time, and if you don’t understand something ask about it in the SDL Community. Discussions around these sort of things are always really welcome… it’s not just a place to go when you have a problem! And if you do this I can guarantee you’ll find your ability to work with any tool will be significantly improved.
Excellent article!
Thanks. Now I know why my Embedded Content for Word did not function correctly.