 The most viewed article I have ever written by far was “So how many words do you think it was?” which I wrote in 2012 almost ten years ago. I revised it once in 2015 and whilst I could revise it again based on the current versions of Trados Studio I don’t really see the point. The real value of that article was understanding how the content can influence a word-count and why there could be differences between different applications, or versions of the same application, when analysing a text. But I do think it’s worth revisiting in the context of MT (machine translation) which is often measured in characters as opposed to words… and oh yes, another long article warning!
The most viewed article I have ever written by far was “So how many words do you think it was?” which I wrote in 2012 almost ten years ago. I revised it once in 2015 and whilst I could revise it again based on the current versions of Trados Studio I don’t really see the point. The real value of that article was understanding how the content can influence a word-count and why there could be differences between different applications, or versions of the same application, when analysing a text. But I do think it’s worth revisiting in the context of MT (machine translation) which is often measured in characters as opposed to words… and oh yes, another long article warning!
For example (and at the time of writing), DeepL offer 500,000 characters per month for free, (unless you use it with a CAT tool and then you always pay). I’ll stick to months to make the comparison a bit more meaningful…. and do I mean “a bit more” as each provider offers various features so the overall price won’t be apples for apples, but it will illustrate my point. Language Weaver offer 600,000 characters for free (with a CAT tool); Google offer 500,000 characters for free (with a CAT tool); Microsoft Translator offer 2,000,000 characters for free (with a CAT tool); Amazon Translate offer 166,667 characters for free (with a CAT tool) for 12 -months only. Not all MT providers work this way and some just charge from the moment you start, but the main point is character counts could well be very important to you if you are working with machine translation through one of these popular providers. So let’s not get hung up on the prices and get to the point…
![]() My point is that if you have a free allowance, or if you pay for characters from the start, then the number of characters you use will be very important for you. Knowing how to use your CAT tool to minimise the number of characters you use is something I’m sure you all know about too… but just in case you don’t I’m writing this article to look at how Trados Studio manages this for you. I’m going to use Language Weaver for this example as I want to use the out of the box solution for MT first as this could well be what most users take advantage of. But I’ll also address a couple of plugins for other engines mentioned here as well.
My point is that if you have a free allowance, or if you pay for characters from the start, then the number of characters you use will be very important for you. Knowing how to use your CAT tool to minimise the number of characters you use is something I’m sure you all know about too… but just in case you don’t I’m writing this article to look at how Trados Studio manages this for you. I’m going to use Language Weaver for this example as I want to use the out of the box solution for MT first as this could well be what most users take advantage of. But I’ll also address a couple of plugins for other engines mentioned here as well.
Contents
My Document…
I’m going to conduct this test using a document that contains 592 characters in total according to Trados Studio. My first test is to do a pre-translate of the entire document and just see how this affects my allowance in Language Weaver.
If you want to try this out yourself, and eat into your valuable allowance, then here’s the source material I used (generated by this website and to my horror American English but I only noticed this after nearly finishing the article so won’t be changing it now!):
I've traveled all around Africa and still haven't found the gnu who stole my scarf. He wondered why at 18 he was old enough to go to war, but not old enough to buy cigarettes. He wore the surgical mask in public not to keep from catching a virus, but to keep people away from him. Swim at your own risk was taken as a challenge for the Trados AppStore Team. The elephant didn't want to talk about the person in the room. The opportunity of a lifetime passed before him as he tried to decide between a cone or a cup. I'd rather be a bird than a fish. He never understood why what, when, and where left out who. I may struggle with geography, but I'm sure I'm somewhere around here. Little Red Riding Hood decided to wear orange today.
Language Weaver reports that I have used up 724 characters. Herein lies the first important piece of information illustrated by the following table which we can use for reference in this article. Oh yes, just in case… we are always talking about source counts here and not target!
| Segment No. | With spaces | Without spaces | Spaces |
| 1 | 83 | 69 | 14 |
| 2 | 91 | 72 | 19 |
| 3 | 104 | 84 | 20 |
| 4 | 76 | 62 | 14 |
| 5 | 62 | 51 | 11 |
| 6 | 94 | 76 | 18 |
| 7 | 33 | 26 | 7 |
| 8 | 59 | 49 | 10 |
| 9 | 70 | 59 | 11 |
| 10 | 52 | 44 | 8 |
| TOTALS | 724 | 592 | 132 |
Trados Studio doesn’t count spaces, but Language Weaver does. So… all explainable but very important to note since relying on your Trados Studio analysis to keep track of your usage could be around 20%… ish off the actual allowance and when you spot this it won’t be erring on the side of caution!
It’s probably a good time to see where you can find the Language Weaver allowance and reporting as this is something that every Trados Studio user with their own licence will have access to. The link will only work if you are able to login, but I think it’ll help anyone who didn’t know and does have Trados Studio: https://translate.sdl.com/reports/dashboard
I started with a fairly fresh account I use for testing and haven’t used any MT on it at all until today, so my graph is pretty boring! But it does provide all the information I need to know and updates in realtime as I work in Trados Studio:

Some translation…
For this exercise I’m going to start with my file un-translated. I’ll just open the file and activate MT with only the first segment active. I might expect to see 83 characters taken from my allowance, but I don’t, I see a lot more than that. Now, there will be many of you reading this who may expect to see 278 characters and that would make sense given my default Trados Studio settings use the “LookAhead” feature here:

This is actually a pretty cool feature as it speeds up the work when working with MT by caching three segments at a time so the retrieval of the result is faster after the first one. So, 83+91+104=278. Makes sense… but this isn’t what’s returned (Trados Studio 2022 version 7.0.1.11652 at the time of writing). I actually get 556 characters taken which is double the amount. To understand what’s happening I used Fiddler to look at the results and with this tool I can see this in order of the six calls made:
- segment #2 : translation is returned (91 chars)
- segment #2 : translation is returned (91 chars)
- segment #1 : translation is returned (83 chars)
- segment #1 : translation is returned (83 chars)
- segment #3 : translation is returned (104 chars)
- segment #3 : translation is returned (104 chars)
After this the results all make sense (insofar as the mathematics) and my MT allowance is taken as follows:
| Segment No. | MT Character Count | Deducted From Allowance |
| 1 | 83 | 556 |
| 2 | 91 | 76 |
| 3 | 104 | 62 |
| 4 | 76 | 94 |
| 5 | 62 | 33 |
| 6 | 94 | 59 |
| 7 | 33 | 70 |
| 8 | 59 | 52 |
| 9 | 70 | 0 |
| 10 | 52 | 0 |
| TOTALS | 724 | 1002 |
This time not really explainable… other than this is clearly a bug that needs to be resolved. If the count was corrected to 278 characters then the overall allowance working in this way would remain the same, and whilst the difference for this file with only ten segments looks stark I think that in real-life this is unlikely to be a significant factor in exceeding your allowance. But nevertheless it needs to be addressed.
A more important point is how does LookAhead work when you are working in real-life? It’s unlikely you start from one end of the file and work logically from start to finish without ever going back. More likely you’ll use filters and try to reduce your effort by working on as much of the file in one go as you can; you’ll perhaps realise you need a different translation for parts of the document you now have more context for so you’ll go back over the parts you did before; you’ll save your edited MT into your TM; you’ll have queries you’re waiting for a response to etc. So your movement up and down the document is very likely to be erratic for all but the most simple translation jobs. How does LookAhead affect your count when you do that?
Let’s take a crazy example and just work through the document in a different order to illustrate the point… as shown in this table:
| Segment No. | MT Character Count | Deducted From Allowance |
| 1 | 83 | 556 |
| 5 | 62 | 189 |
| 10 | 52 | 52 |
| 2 | 91 | 76 |
| 6 | 94 | 59 |
| 9 | 70 | 122 |
| 3 | 104 | 62 |
| 7 | 33 | 70 |
| 4 | 76 | 0 |
| 8 | 59 | 0 |
| TOTALS | 724 | 1186 |
Clearly a difference, based on me confirming each segment as I worked but not working through the file sequentially. Every time I enter a segment that has two more untranslated segments following it then the use of LookAhead will cause each look up to take the sum of all three segments from my allowance. So when I move to segment #5 then the characters used will be 62+94+33=189 (sum of segments #5, #6 and #7). When I get to segment #3 then the characters used will be 104+76+62=242 (sum of segments #3, #4 and #5)… but wait!! Segment #3 only takes 62 characters from my allowance… the reason of course is because LookAhead has cached segment #3 (from segment #1) and segment#4 (from segment #2) so only the count from segment #5 is taken which is 62 characters. I know this is a little confusing, but hopefully once you read this a few times it’ll all make sense. The point being of course that I have now taken 1186 characters from my allowance which is 184 more than I did when working sequentially.
But there’s more… if I had a long document I probably wouldn’t keep it open all the time so what might happen to my count if I’m opening and closing the file during the course of my work? Let’s take a look!!
| Segment No. | MT Character Count | Deducted From Allowance |
| 1 | 83 | 556 |
| 5 | 62 | 189 |
| 10 | 52 | 52 |
| 2 | 91 | 632 |
| 6 | 94 | 186 |
| 9 | 70 | 70 |
| 3 | 104 | 559 |
| 7 | 33 | 59 |
| 4 | 76 | 0 |
| 8 | 59 | 284 |
| TOTALS | 724 | 2587 |
This time I did the first three segments (in the order above, #1, #5, #10) and then closed the file; then opened the file and did #2, #6, #9 and closed the file; then opened the file and did #3, #7, #4 and closed the file; finally opened the file and completed #8. The total deducted from my allowance this time is significant for this small file as the count is nearly four times more than expected! The reasons are two fold:
- the bug affecting the count in the first segment is multiplied for each time the file is opened;
- the cached results from LookAhead are lost when you close and open the file so you lose this particular benefit of the feature
It’s obviously skewed heavily because of the bug in the first segment, but I think the point is clear. It’s pretty easy to use a lot more of your allowance than you think if you are not fully aware of how Trados Studio works and the way its features can impact the drawdown of your free character allowance. So let’s take a quick look at the features in question before we address a work practice that might prove more beneficial in more ways than one!
Relevant features…
There are two default settings in Trados Studio working in your favour, and one working against you (in my opinion…).
For you…
Under File -> Options -> Editor -> Automation, a global setting, you have an option to “Perform automated translation lookup on confirmed segments“. This is disabled by default which is a good thing!
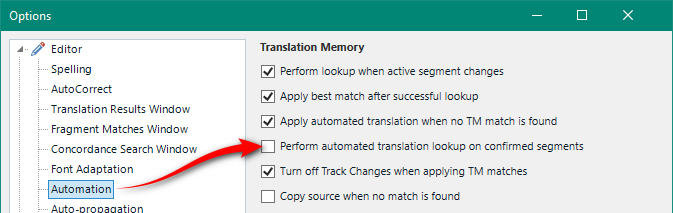
Since this is disabled the MT will not be applied, nor will the allowance be reduced, for any segments that are already confirmed. It may be useful if you are reviewing work and wanted to use the MT as an additional resource, but in general segments that are already translated and confirmed probably don’t need to be sent off for MT.
And in your Project Settings -> All Language Pairs -> Translation Memory and Automated Translation -> Search, a setting that can be specific to a particular project, you have an option to “Look up segments in MT even if a TM match has been found“. This is also disabled by default and it’s also a good thing!
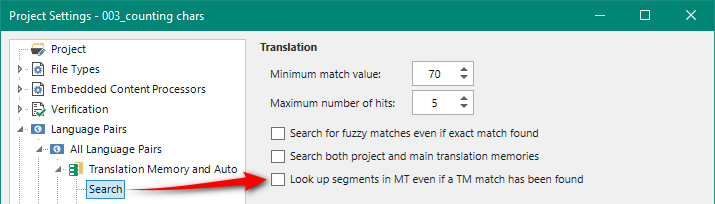
I covered this ten years ago in an article called “There’s more than one way to skin a CAT“, but to summarise this is really only useful if you are translating interactively with MT and you would probably use this in conjunction with the minimum match value setting. The idea is that you should set the minimum match value to something that makes sense for you. So if you feel that a TM match of 70% will be better than MT then leave the default 70% (Minimum match value), but if you think MT is going to be more relevant and closer to 90% (for example) then change the minimum match value to 90. If you think that MT is always on a par with anything that might come from you TM AND you only want 70% or above (for example) from your TM then you could enable the “Look up segments in MT even if a TM match has been found” and then you’ll always get MT in addition to your TM matches.
Against you…
Back to File -> Options -> Editor -> Automation, so a global setting, you have an option to “Enable LookAhead“. This makes it sound as though you can enable it, and that would have been a good thing, but it’s already enabled by default… which in my opinion is a bad thing!

Why do I think it’s a bad thing? Here’s a few reasons why:
- it takes unnecessary characters from your allowance when using MT;
- it can cause unwanted side effects when working with translation memories and termbase’s because the caching of additional segments can prevent a new entry from being available for a couple of segments while working interactively;
- … and I’m going to say it! It has been attributed to performance and instability issues for some users. I cannot be 100% on this being the cause, but I certainly see the advice on more than one occasion from an experienced user, Ali Field, to switch it off and this almost always resolves the problem. There’s rarely smoke without fire!
So for me… I think the default should be disabled, not enabled, and then the description “Enable LookAhead” would also make sense. In particular when we look at a suggested way to work to get more value from your MT without burning your available character count.
A suggested workflow…
At the start of this article I pre-translated the document for my tests. I did not work interactively, and as we saw throughout the tests afterwards the pre-translation used less characters. If I had a TM attached, and there were good results coming from my TM then the pre-translation would have used even less characters from my allowance. So here’s a couple of thoughts to illustrate ways in which you can benefit from this.
Use a Project TM…
When you create a project in Trados Studio, and I mean a Studio project as opposed to a single file project, the default task sequence is to “Prepare without project TM“. There is another option that used to be the default many versions ago called simply “Prepare“:

The default was changed because this concept of a Project TM was always misunderstood by translators in particular who felt it was over complicating the task of creating a project and caused confusion when their big mama TM wasn’t getting updated. So these days it tends to be used by Project Managers who see the value in this, especially when working with large TMs or when creating project packages. For most translators it’s true that it’s probably not necessary. Well now I’m going to explain why you probably should think about using this option if you work with MT.
When you create a project with this option you’ll see something like this happen in your Project Settings: When you prepare the project you’ll have this:

After the project is created you’ll see this:
 Notice how I now have 004_counting chars_ro-ro.sdltm added underneath the en-ro.sdltm I used? This new TM is my Project TM that was created automatically because I used the “Prepare” task sequence as opposed to the “Prepare without project TM” task sequence. This is basically named using my project name with the TM appended to it. I would imagine many users see this in their project settings when working on packages created by their client.
Notice how I now have 004_counting chars_ro-ro.sdltm added underneath the en-ro.sdltm I used? This new TM is my Project TM that was created automatically because I used the “Prepare” task sequence as opposed to the “Prepare without project TM” task sequence. This is basically named using my project name with the TM appended to it. I would imagine many users see this in their project settings when working on packages created by their client.
When you create your projects in this way the idea is you want your file to be pre-translated with 100% matches (or less if you feel lower value matches are more useful than MT) and everything else from MT. So in my pre-translate settings I use this:

- I use the “Prepare” task sequence to make sure my Project TM will be created;
- my pre-translate from my TM is set to 100% so I only get 100% matches from my TM;
- when there isn’t a 100% match use MT from my Cloud Resources (Language Weaver).
I will then end up with something like this in my file:

The entire file is pre-translated, I have 100% matches from my TM and anything else has been provided by my MT. Now, I opened the file to demonstrate what happens in my file but in practice I wouldn’t do this. All I would do now is the following:
- Disable my Cloud Resources so I will not be using MT directly from Language Weaver anymore for this project:

- run a batch task to “Update Project Translation Memories” making sure I check the segment status “Draft” as MT results in the translation (see image above) are all draft status:

- Now I will have all the MT results stored in my Project TM and I won’t need to go back and get them from my Cloud Resources anymore, which of course means I will not be using up my allowance.
- Lastly I would also disable the option to “Confirm segment after applying TM matches“. You’ll find this in your global options under File -> Options -> Automation. The reason for doing this that the MT results added to your TM will now be treated as if they are a TM match. They will have the NMT status so you can see they were MT matches, but as they are now in the TM they will be automatically confirmed as soon as you click into one of these segments in your file unless you disable this option:

And that’s it… simple enough and it took me more effort to explain it than it actually takes to do it! Maybe two more things to explain before I move onto another idea… the first is where you’ll find this “Project TM”. If you navigate to the location of your project in windows explorer you’ll see there is now an additional folder called “Tm”:

In there you’ll find a language folder for each target language in your project and in the language folder you’ll find the Project TM. The reason it’s important to know about this brings me onto my second point.
When you work through your translation project using a “Project TM” you will only be updating this TM. Your Main TM will remain untouched. This is the part that confused so many translators when Trads Studio was first released many years ago as they thought their TM was not being updated as they were looking in the wrong TM! This is also important because you do not want your Main TM filled with unedited MT matches. So using a Project TM in this way means you will never do this and only the completed translation will be updated into your Main TM. This can happen in two ways at the end of your project:
- you can run the batch task to “Update Main Translation Memories“;
- you can run the batch task to “Finalize” your project which will update the Main TM and also create your target files.
Create your own “Project TM”…
This time, instead of automatically creating a Project TM as explained above you can create your project using the default task sequence which is “Prepare without project TM“. The steps are similar as follows (I left out the images so refer to the steps above if needed):
- I use the “Prepare without project TM” task sequence to make sure I am not creating a “Project TM;
- my pre-translate from my TM is set to 100% so I only get 100% matches from my TM;
- when there isn’t a 100% match use MT from my Cloud Resources (Language Weaver);
- once the project is created I disable my Cloud Resources so I will not be using MT directly from Language Weaver anymore for this project.
At this point I do something different. I now create a new TM just for this project, which sounds similar but it will actually be (in Trados Studio Terminology) another Main TM. So now I might have something like this:
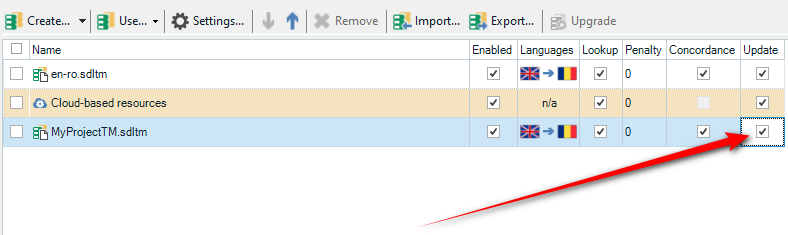
I created a new TM called “MyProjectTM”, and because I already had a TM in there it actually gets added without the “Update” checkbox enabled… so don’t forget to do this! Then do this simple task once:
- disable the your real main TM (en-ro.sdltm). So now my settings actually look like this and the only active TM is my new TM that I created just for this project:

- run a batch task to “Update Main Translation Memories” making sure you ONLY check the segment status “Draft” as MT results in the translation are all draft status. This is important because in this workaround I only want MT results in this TM. I do not want to pollute it with matches from my real TM (I’ll explain why in a bit…):

- Now my new “Project TM” will only contain MT matches.
It’s important to note that when you create a project using the “Prepare” batch task the “Project TM” that is automatically created will also contain matches found in your Main TM which is fine. But it’s also important to note that if you wanted to penalise the MT results so they were not treated like 100% matches, which they will be, then the penalty will also apply to every entry in your TM which means you will never get the true match value, it’ll always be lower by whatever penalty you set. That’s why I’m going through this second example to create my own TM just for this project containing only MT results as now I can penalise them like this:

The reason I would do this is because now these MT results saved in my TM will never get confirmed automatically even I don’t disable the option to “Confirm segment after applying TM matches“.
The other advantage of this method is that I don’t need to work with a TM that is different to my main TM and I won’t need to run the “Update Main Translation Memories” batch task at the end. So in many ways it’s more intuitive to anyone who doesn’t completely buy into the concept of real automated “Project TM’s”.
I also mentioned right at the start that I would address a couple of other plugins for MT that have features that might be helpful when working with MT. I’ll keep this short and just address the features.
Language Weaver
I know I just addressed Language Weaver in this article, but there is a plugin for it on the AppStore. This plugin has some interesting options:
- By default the plugin will resend MT to segments that have already been translated or have a draft status. This is default because a large number of users working with this plugin have Enterprise accounts for MT and the allowance is less of an issue than it is for free users. So if you use this plugin don’t forget to disable this option!
- It also has a language mapping feature which you can access by clicking on “View Language Mapping” at the bottom of the screenshot above. It won’t help with your character counts, but I wanted to mention it because it may be helpful if you are working with an unsupported language where an MT lookup for a language that is similar could still be helpful, or even if an unsupported language gets added but the Language Weaver team use a language code that isn’t recognised. This feature will allow you to tell Studio what to do and get an MT result despite these differences.
MT Enhanced…
This plugin provides you with the ability to work with Google Translate or Microsoft Translator for your MT. The settings for this plugin both provide and option, disabled by default (so a good decision for most users!), to “Res-send draft and translated segments”:

So if you want MT all the time even if you have already had a result then you’ll need to enable this checkbox.
DeepL…
There isn’t actually a setting in the DeepL plugin that will help here and the reason for this is that you always pay for DeepL. The use of DeepL in a CAT tool is currently a flat rate so you pay immediately and don’t get a free allowance. It is based on a fair usage policy so if you are a heavy user then the workarounds using a project TM might still be helpful as you’ll reduce the chances of abusing the allowance you pay for.
Summary
I know this is another long article, but I hope it’s helpful and you’ll find something in here to help you when working with MT, particularly if you have a free allowance and want to maximise this to the best of your ability.
Before I wind up I think it’s worth a quick recap so you can see at a glance my findings:
- Language Weaver includes spaces as characters in the count, Trados Studio does not.
- If you have Lookahead enabled in Trados Studio then you should expect to see an increased number of characters taken from your allowance depending on how you work through the file.
- Trados Studio has a bug that makes duplicate calls to an MT provider for the first segment (at least).
- You can reduce the amount of MT characters you use on a translation project by working smarter and putting the MT results into a TM so you won’t keep looking them up from your allowance after doing it once.
- Most plugins for Trados Studio do have an option that might be helpful in terms of reducing the character count when needed.
One final point. Working interactively used to be something many translators preferred to do as they had some control over the MT by working with autosuggest. Today, with the improvements we see in neural machine translation the quality of the MT is much better and that same process may not be as practical as it was. Whilst it does depend on the language pair you are working with, and obviously depends on the nature of the translator (I’m well aware some are very opposed to using MT), I do think more and more translators today are finding that post-editing rather than interactive translation can be more productive and profitable at a time where everyone is feeling the pinch!.
Paul, this is a wonderful post, very useful for MT plugin devs. So, will the LookAhead bug be fixed? 🙂
Hi Gergely, LookAhead itself doesn’t have a bug. But it does have a flawed design (in my opinion) and it’s easy enough to work around when working with MT. The bug relates to the sending of MT twice (or potentially first three if you use LookAhead) from the first segment only. This I’m sure will get resolved, but I couldn’t tell you when.