 I love to see technology being used to help provide a clean environment for us to live in and to bring up our children. This topic regularly comes up in our household as my wife and son support the ethos behind this ideal wholeheartedly… actually I may even be understating this point a little!
I love to see technology being used to help provide a clean environment for us to live in and to bring up our children. This topic regularly comes up in our household as my wife and son support the ethos behind this ideal wholeheartedly… actually I may even be understating this point a little!
But this isn’t the clean environment I want to talk about today. I’m interested in a clean editing environment when you use a translation tool.
What I mean by this really is the ability of the tool you use to provide a clear view of the translatable text and to maximise the value you get from a translation by handling the tags for you. I started to think about this more after reading, and participating, in a thread on ProZ that you can review here if you’re interested : http://goo.gl/C1AsD
So for example, I don’t want to see lots of tags when I translate, I’d rather see clear text as much as possible, like this:

In that image you can see a segment created from a Microsoft PowerPoint file and then opened in Studio 2011. First of all I displayed the tags and then I turned them off (ctrl+shift+h) so that you have a cleaner way of working. The tag-free image does look better of course, but it is very important to understand that these tags are still there even if you can’t see them. You can read more about handling the tags in the Studio editor in this article:
Simple guide to working with Tags in Studio
Studio is pretty good at keeping the environment clear of tags to help you make sense of the text, and it’s good at easily showing the tags again so you can correctly place them into your target translation. But what I’m interested in now is how well does the translation of the text get reused across different filetypes where the tags could be represented in a different way?
This question arose in the same ProZ discussion so I started to take a look at this with Selcuk Akyuz, a Deja-Vu user, who kindly provided a few DTP test files and a PO file that I could add to the MS Office, HTML and XML files I created. This allowed me to create a Project using these files, and I merged them together so it was easier to see:
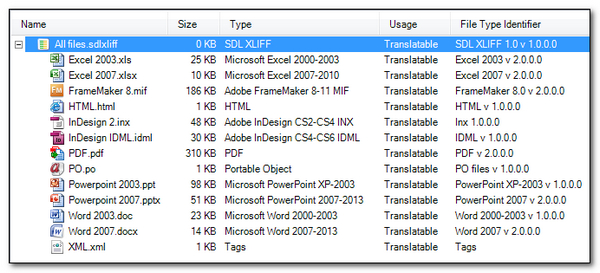
When I open this in Studio I see something like this:

Interestingly the Excel files show the tags whatever I do so I’m stuck with the tags in this format, but the other files are rendered perfectly making it more pleasant to translate in all of these formats. Now, the interesting part is what can I expect in terms of matching? Well before I look at this I think it will be useful to look at the tags and see how they are actually offered in the Editor because they are still there even if I can’t see them. So I press ctrl+shift+h and now I see this:
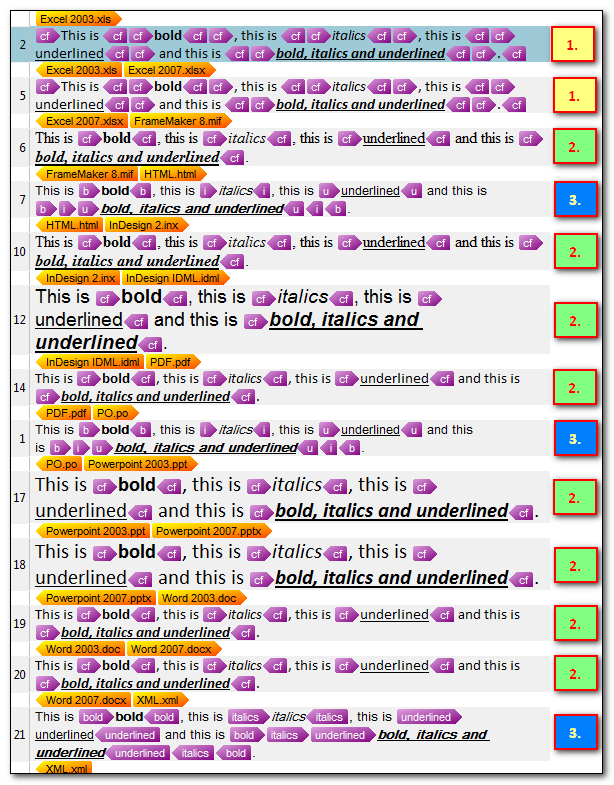
The coloured numbers at the right represent the “type of tagging” that the filetypes extract for these filetypes. So for each of these thirteen different filetypes, each containing exactly the same translatable text, I would really need to have three “different” translations if I wanted to be able to pretranslate this project and achieve a 100% match for all of them. So after adding each one as a different TU I now have this in my Translation Memory where each tag is a placeholder for the content rather than the actual content itself:

I said “different” translations, but really the translation is the same. The problem is that each filetype has its own way of adding tags and if this results in more tags in one than another then you will get a formatting penalty that prevents a 100% match. So Type 1. contains 18 tags, Type 2. contains 8 tags and Type 3. contains 12 tags.
The content of the tags themselves are irrelevant, so for example in Type 2 I can translate the HTML file and I get 100% autopropagated matches for the PO and XML. I used another nice feature of Studio to show the tag content here so you can see the differences… each of these segments could be translated without showing any tags at all as shown at the start:

With Type 3 I can translate the FrameMaker (MIF) file and get 100% autopropagated matches for the InDesign (INX and IDML) files, the PDF and both flavours of Powerpoint and MSWord:
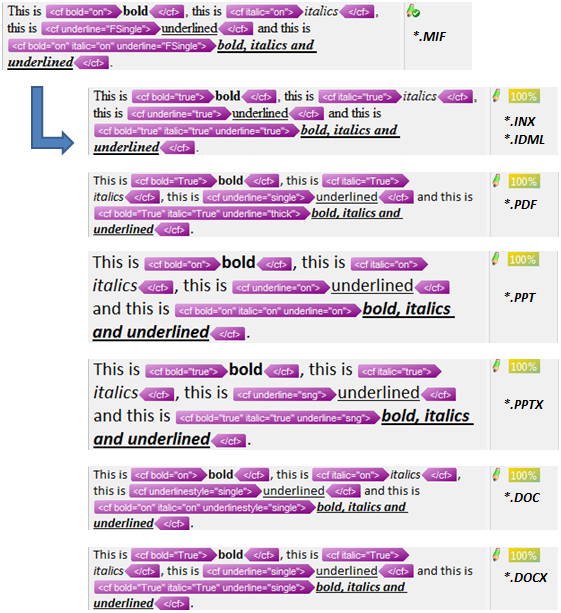
The two Excel files (XLS and XLSX) would be matched with a single translation and really I think should handle the Office format better so that only two TUs are needed to completely translate the whole file rather than three. But I hope from these examples you get the idea and can see how Studio nicely uses the principle of placeholder tags in the Translation Memory to ensure that you get more leverage from your Translation Memories when handling similar text in different filetypes.
To end this matching review just another idea… you could also remove the formatting penalties from the TM in here:
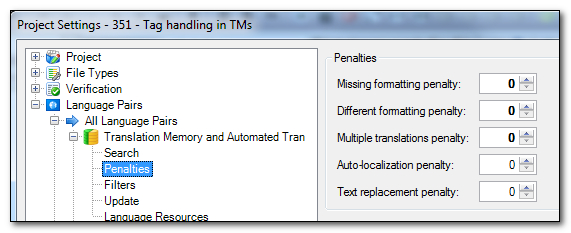
When you do this you only need two TUs in the TM because Type 2 and Type 3 are both translated 100% without the penalties for formatting being applied. The Excel filetype should work like this as well… so something to be fixed in the future and then you’ll only need one! (But please use this idea with care to avoid missing tag problems when saving the target document… or make sure you run the QA check – F8)
If you’re interested to see how your CAT tool handles these files and provides you with a clean editing environment whilst retaining the ability to maximise reuse of the translatable text I have placed the files I used here on dropbox:
The Test Files
Finally, I thought it would be interesting to see how other types of tags that are perhaps not so simple as bold, italic and underline are handled. So not simple formatting. To do this I took a few word documents all with the same translatable text in Word, but all containing “hidden” stuff… like hyperlinks and index entries. So in Word all three documents look like this:

Simple… but when I open all three in Studio and translate the first one I see this where Studio extracts these entries altogether marking them in the right hand column so you know what type of information they represent:
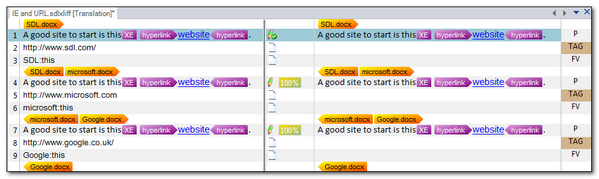
In doing this Studio enables the ability to get a 100% match for the translatable text in all three files even though the URLs were different and the Index Entry with Sub Entry was different in each case. In addition you can still translate the URLs and the Index Entries if necessary… quite a sophisticated feature I think.
I added these files to dropbox as well just in case you were curious how well your CAT handles this sort of thing:
Test Index Entries and URLs
Have fun… and maybe share your experience with this in the comments.
Just a random collection of things I thought it might be useful to know, mostly about translation technology….
Striving for a clean editing environment is of course great. But in some respects Studio has taken it to an extreme. Leaving parts of a tag pair out of a segment does not work for example, since the word order is often changed in the target language. If your sentence above was
Bold this is.
the first part of the tag would be left out of the source segment, if I am not mistaken. In SV, this would be for example
Det här är fetstilt.
Hence I need to display all content and copy the tag to get it into the target segment. Or is there a better way?
There will be an idea about always displaying entire tag pairs on an idea site near you soon.
Hi Daniel, in your example the full tags would be shown as these are internal tags. The tags are only moved outside if the entire segment is between the tag pair. I think if the filetype was TTX and you didn’t use smart tag pairing then maybe this could happen using the example you provided as both tags would be placeholders, but with smart tag pairing it never would.
Thanks for the answer. I will check this out. It might only have occured with TTX files, haven’t thought about that. That was a simple example of course, but would it work the same way with cross references, for example?
I don’t know… if you have some examples I’ll happily check them with you. Any placeholder, as opposed to tag pair, at the start of a segment could do this. In XML you can define the tags to always be inline, but some of the predefined formats don’t have this capability. Best to address it if you see it again I think.
I will definitely keep an eye on when it occurs, for which file formats etc., etc., and see if it can be fixed in those instances. At least I have enabled smart tag pairing for TTX’s now, so maybe the problem will just disappear.
That problem will… but please keep in mind that using smart tag pairing is not the best approach for a workflow where you need to maintain 100% consistency with the original TTX prepared in 2007. Sometimes the smart tag pairing approach can cause problems for the 2007 user if they try to clean up the TTX. These legacy workflows can be a little tricky… so if you do get a problem just try pre-translating the original TTX with smart tag pairing disabled.
OK, thanks for that tip too. Always helpful.