 I believe this interesting quote can be found in “Prometheus Bound”, a play by a Greek dramatist called Aeschylus. I haven’t read the play, but I like the quote, and it certainly lends itself to the importance of memory… even when we refer to a Translation Memory rather than your own built in capability. It’s because your Translation Memory is such an important asset to you that you need to regularly maintain it, and also reuse it wherever possible to expand the benefits you get from it.
I believe this interesting quote can be found in “Prometheus Bound”, a play by a Greek dramatist called Aeschylus. I haven’t read the play, but I like the quote, and it certainly lends itself to the importance of memory… even when we refer to a Translation Memory rather than your own built in capability. It’s because your Translation Memory is such an important asset to you that you need to regularly maintain it, and also reuse it wherever possible to expand the benefits you get from it.
Studio does have some simple features for helping you to maintain your Translation Memories, but there are things you might want to do that go beyond the capabilities of search and replace, creating and editing fields and attributes or exporting subsets or complete copies of your Translation Memories… let’s refer to these as TMs from here on in.
- check your TMs for consistency and other QA requirements
- export subsets of your Translation Memories based on complex queries
- stripping out fields, attributes and other translation unit information
- convert to other formats (xliff, xml, csv etc)
- enhance TM with the translatable content of tags
If you wanted to do these sorts of things to help you properly maintain your TMs or use them for other things then you would have to use tools that operate outside of Studio… but not necessarily outside the Studio platform. So I’m talking about the SDL OpenExchange (now RWS AppStore) of course. This platform and the capability that is available for anyone who has the knowledge to do their own programming is not provided by anyone else. It really is a well developed and supported tool in it’s own right. A good example of how this can be used is by another Hellenic, although this time a developer and not a dramatist 😉 Costas Nadalis has developed four applications for the OpenExchange and is one of the most prolific developers creating applications for others to benefit from:
All of these are really useful applications and all of them are applications that centre around the wisdom of maximising the use of your TMs. The one I want to focus on with this article is SDL TmConvert as this is the most recent application Costas has submitted and it allows you to do all of the things I mentioned at the start and more. The application itself looks like this (the control part of the screen anyway):
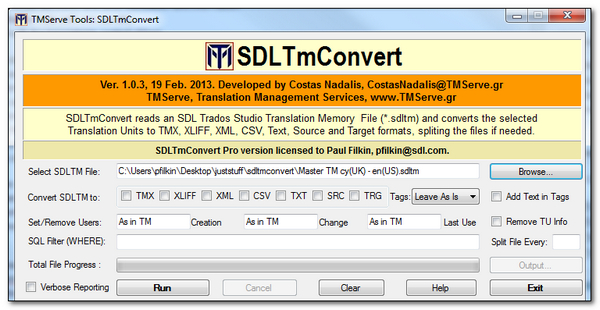
You can immediately see this is a very compact application filled with some excellent features, and you’ll also see there is some licensing information too. This application has a free version that allows you to work with TMs containing up to 50,000 Translation Units. To work with TMs greater than that you need the Pro version which is €35… but this is a bargain for the functionality we see.
I’m not going to run through everything this tool can do as there is an excellent help file that explains how to use the features and also what they may be useful for, but I will pick out a couple of things that are interesting for me.
First of all the ability to convert your TM to XLIFF. This is an option you need to be careful with if you’re working through your own TMs because once you do this and create a new TM with a QA’d XLIFF then you will lose all the context information that is held in the TM but not in an XLIFF… so information related to Context Match, TU information and custom fields. But the process of converting your TM to XLIFF files, adding to a project and QA’ing them is not insurmountable… you just need to be careful and Costas kindly provides good information in his help file explaining the process. In a nutshell this is what you’d do.
Convert your SDLTM to bite sized XLIFF files (say 500 TUs at a time for example). This is simple as you use this option:

This is pretty quick, less than 7 seconds for 42 thousand TUs, and at the end I get a report in the bottom half of the window ending like this:

Then I create a project in Studio with all of the XLIFF files and add the SDLTM I just converted and any other resources I want to help me with the QA checks I intend to run. This part could take a little while depending on the size of your TM, so you could also select to do this in bite sized chunks too and create several projects until you finish the job. It took 5 – 10 minutes to complete the project creation for me with some 600K words split into 84 files. But now I can run whatever QA checks I have in mind to verify that my TM is sound:

The trick now is to NOT “Confirm Translation” as you work. So use the arrow keys instead if you wish to move between segments, or alternatively a better solution is to uncheck the “update” box in your Project settings so even if you do confirm by mistake there will be no harm done:
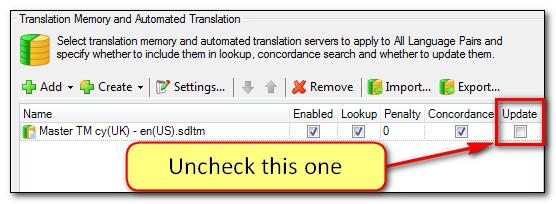
Then if you have to make any changes to correct something in the TM you do this in the TM Results window to ensure you don’t lose any of the important information you hold for context matching etc. So if I right-click in the TM results window as I work through the file I can edit or delete the TUs directly inside the TM and thereby retain all other important information that might be incorrectly changed if I confirmed the changes through the Editor instead:
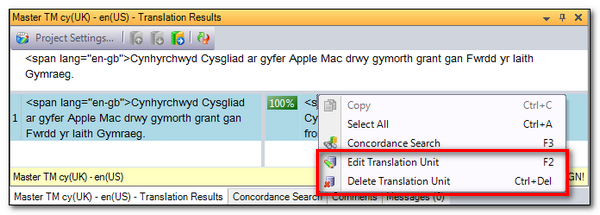
So if I remove the html code that is in this TU and I don’t want it then I now see this where I get an 86% match as the XLIFF I opened still contains the unwanted tags but my TM does not:
You could easily set up QA checks to find all the TUs with HTML tags in them, ordinary spaces where non-breaking spaces should be used, verify against your word lists for incorrect spellings, use the terminology verifier to correct the use of terms, where source was the same as target etc etc… but the important thing being DO NOT UPDATE THE TM BY CONFIRMING THE TRANSLATION IN THE EDITOR
Once you’re done don’t finalize or run any batch tasks either (if you uncheck the box above this won’t effect it anyway)… so probably good to tackle this work when you have a good bit of time to get used to the rhythm of working, and don’t fall into the trap of confirming changes rather than editing them directly in your TM. This is a maintenance exercise.
Another useful thing to do as you prepare the project could be to create a file containing frequently occurring segments:
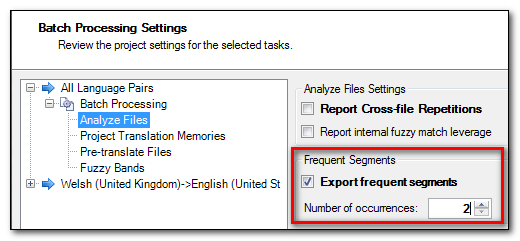
This option, which you set when you prepare your project will create an SDLXLIFF file that contains segments, or in this case Translation Units, that are duplicated at least twice (I set this to 2). So I can then add this file back into my Project and immediately see whether I can improve this situation a little. So with this TM I had two segments that were duplicate source, and looking at the results I can see this second segment has four duplicate translations, each getting a penalty of 1% so in effect reducing my possibilities for a 100% match:
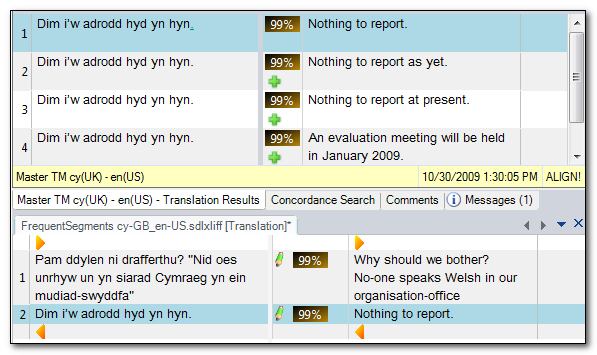
I could delete the ones I don’t want in the TM results window… quite a neat feature I think.
So an excellent way to QA TMs from others and for checking on the status of your own from time to time. Despite having 600K words in this relatively small TM I would hope that the vast majority would not need too much work, so this process is a very useful one.
The other thing I wanted to mention is related to preparing your TM for use elsewhere. So in creating AutoSuggest Dictionaries, or for training Machine Translation Engines. Neither of these things need to have all the tags and superfluous TU information that you get in an SDLTM. It’s all relevant for translating, but just adds unnecessary processing for other uses. This is where Costas added a really neat feature to this application that allows you to strip out all the superfluous information at the click of a button.

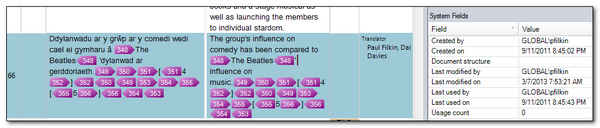
If I take as an example the same TM I have a TU in here that looks like this with quite a lot of tags, system fields and a couple of custom attributes:
If I export this to a TMX through Studio in the normal way I will get a TU that looks like this:
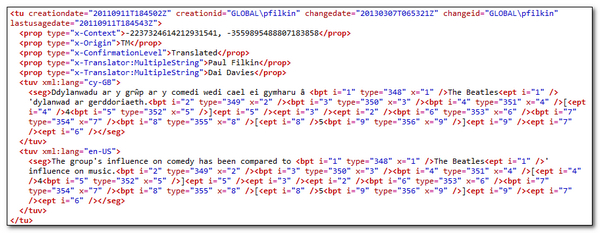
If I use the SDLTmConvert application set up to strip out all of the superfluous information I’m not interested in it looks like this… and took less than 5 seconds to do it (it did take 9 minutes to do the 1.9 million TUs TM I used this on… but the subsequent ASD generation with maximum extraction was possible where it failed before I did this):

That looks much cleaner, and is much more suitable for using to generate my AutoSuggest Dictionary or feed into my new BeGlobal Trainer for my customised machine translation solution.
Costas really does epitomise what the OpenExchange is all about… providing people with the ability to create applications that can add value to the solutions you have purchased by helping them to work together more efficiently, and at the same time improve the ability to get more use from the resources you already have. I think all the tools he has developed so far have been good, but this one is really good!
A great way to keep your TM clean is – to delete it 🙂 You can create very clean TMs by importing bilingual files into a new, empty TM. Just be careful to set the right field values, as they often cannot be retrieved from bilingual files.
A good point in time to do this is after you finished a project. By importing all final, maybe already reviewed TUs into a fresh TM guarantees that the TM only contains these TUs. Such “final project TMs” can then be merged into a “clean master”.
The “final clean project TM” can also be used to identify any translation ambiguities. In theory, when you create a TM out of a project’s final bilingual files, and use that TM to analyze the project source files against this TM (and only this TM), you should almost exclusively get context matches. If you don’t, there may be penalties (such as multiple translations) kicking in, indicating translation inconsistencies you may want to investigate further (assuming there were no splits/merges). In the analysis/prepare report, it’s easy to identify all files which haven’t been “context matched” fully, these are the ones to look at.
This consistency verification is particularly useful if you are a project manager and didn’t deliver the translations yourself. If multiple translators worked on a project without using a shared TM, there is no guarantee that the same segments were translated the same way. Creating a TM from all the delivered translations, and analyzing/pretranslating the source files against this TM will quickly reveal inconsistencies.
You can create TMs from bilingual files, but not the other way around. Keep these files, they are extremely valuable assets for future reference, as they provide much more context than the TM can track.
Good advice Oli… although I’m not sure how many people keep all their bilingual files in reality. I’ve seen in practice a few times now where bilingual data from older formats provided a much better upgrade route when it came to improved leverage for some filetypes. So using the bilinguals instead of upgrading the old TMs.
Regards
Paul
How feasible is this app for a TM that contains say 500k or 1M TUs? I see you have broken up your TM into 500 TUs, which would be 80 files for 40k units. That would be awfully unwieldy for larger TMs, or no?
This was just an example. If your TM was larger then use bigger chunks! You could just as easily have 100 files with 5000 TUs in each one. Generally I like to keep the file size small because it’s more comfortable when working with smaller files in the Editor, but I often see files with more than 25k TUs in them so it’s really down to what works best for you.