7 June 2018 update: note that the application referred to in this article is actually part of the product in Studio 2015 onwards. So no need to download it!
 English spoken in Australia, Belize, Canada, Caribbean, India, Ireland, Jamaica, Malaysia, New Zealand, Republic of the Philippines, Singapore, South Africa, Trinidad and Tobago, United Kingdom, United States and Zimbabwe. Also known as en-AU, en-BZ, en-CA, en-029, en-IN, en-IE, en-JM, en-MY, en-NZ, en-PH, en-SG, en-ZA, en-TT, en-GB, en-US and en-ZW. These are the language codes used by Microsoft in their National Language Support (NLS) API Reference for the different flavours of English supported and this is what Studio bases its language support for English on… then it’s further complicated as it can also vary depending on the operating system of your computer (Win XP, Vista, Win7 etc.)
English spoken in Australia, Belize, Canada, Caribbean, India, Ireland, Jamaica, Malaysia, New Zealand, Republic of the Philippines, Singapore, South Africa, Trinidad and Tobago, United Kingdom, United States and Zimbabwe. Also known as en-AU, en-BZ, en-CA, en-029, en-IN, en-IE, en-JM, en-MY, en-NZ, en-PH, en-SG, en-ZA, en-TT, en-GB, en-US and en-ZW. These are the language codes used by Microsoft in their National Language Support (NLS) API Reference for the different flavours of English supported and this is what Studio bases its language support for English on… then it’s further complicated as it can also vary depending on the operating system of your computer (Win XP, Vista, Win7 etc.)
Of course this is English, or flavours of it. But there are differences and Studio always insists on knowing which flavour of any language is being used. So 16 variants… and it’s even more with Spanish for example where we have 20 variants.
So does it really matter that 23/08/2005 in the United Kingdom is written as 8/23/2005 in the United States, or that 1,234,567,890,123.45 in the United States is written in Spain (Spanish (Spain)) as 1.234.567.890.123,45?
Technically to make the most of the features in Studio yes it does. For example Studio can automatically transpose these like this:
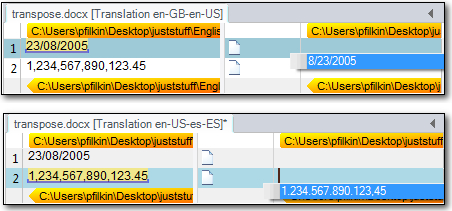
Notice how the date and number have a solid blue line underneath them? This means Studio recognises the format based on how dates in the United Kingdom and numbers in the United States are written, and can then transpose them to a date and a number as written in the United States and Spain respectively. We call these placeables.
To achieve this I opened the document with these two segments in them first using a translation memory created for en-GB to en-US and then again using one for en-US to es-ES.
What would happen if I opened the same file with translation memories for en-US to en-GB or en-US to es-MX (Spanish (Mexico))? I’d see this:
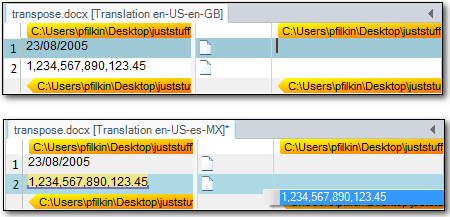
This time the date is not recognised at all because it’s written in the wrong format according to the rules being used, and the number is transposed without any change to the notation (ie. not in es-ES format). So clearly English is not always English, and Spanish is not always Spanish!
The effect this has in Studio is that if you, as a translator, work for customers who work in variations of en-GB, en-US to es-ES, es-MX then you might have to maintain four translation memories if you only translate in one direction, or eight if you work in two. That is of course if you want to get the advantage of allowing Studio to manage dates, numbers, units, variables etc. that are all associated with choosing the correct flavour of translation memory.
Of course whilst these technical variations in language flavours may be different, and the actual spelling, vocabulary and grammar rules may be different, and even the use of colloquialisms in each country, there is still considerable gain to be had in mixing the translation memories you build for each language pair.
So you could, and many translators do this, export your translation memories for each job to TMX and import them into the others so that they all contain the same content. This works… but aside from the obvious unwanted results through merging your translation memories into one like this (duplicate translations, non recognised placeables, spelling differences for example) you also have a considerable overhead in maintenance. We just looked at a couple of flavours in English and Spanish… but consider the possibilities and level of work as this increases?
So what’s the best approach here? Adding a non matching language pair would normally result in this:
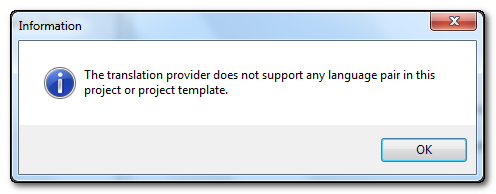
What will work however is Any TM!
Contents

There is a new application on the OpenExchange called AnyTM and this will allow you to select any translation memory at all for your project in read only mode. Get it here. This means that you might still have to create a translation memory for each pair of flavours you work in, but now you can add the others for additional leverage and never have to keep them all up to date with export/import routines and mixed flavours in each one.
How do you do this… simple. You can add the non-matching Tms as you work, but perhaps it’s worth using project templates for each language pair you work in containing all the translation memories you need. So if we take the example mentioned earlier of a translator who has to maintain four translation memories for translating English to Spanish then the project templates would look like this:

The rose coloured language pairs would be the translation memories that you updated and the green would be for lookup only using the AnyTM plugin. Once you set these up you would then select the appropriate template to suit the job that came in and no matter which template you chose you would always be able to reference the work you had done before irrespective of flavour, benefiting from the time saving features built into Studio as a result of its reliance on the Microsoft National Language Support API and language specific variables and you would not have any of the negative aspects of mixed translation memories or the associated maintenance to keep them up to date.
Creating Project Templates
You probably already know how to create a Project Template in Studio, and there a few ways to do it, but here’s what I’d do to get started. First I would right-click on one of my existing projects and then select “Create Project Template…”:
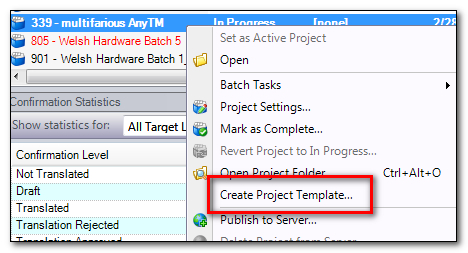
This will bring up a dialogue box where I can save the template with any name I choose. I’m pretty conservative so I choose the language pair as the name so it’s easier to tell the difference in future, especially if I have more language pairs for this procedure:
The project templates can be saved wherever you like but I like to keep them all in one place in the Studio 2011 folder in “My Documents”. Once I save it the Project Template dialogue box comes up and as you’ll see it looks just like the Project Settings window:
I can now make sure that I have all the TMs I need for this. So I open the Translation Memory settings in Language Pairs and add the AnyTM provider, selecting the other three language pairs as I do so… you might not have a long list like this so don’t worry if you think something’s missing… I like to play with lot’s of stuff:
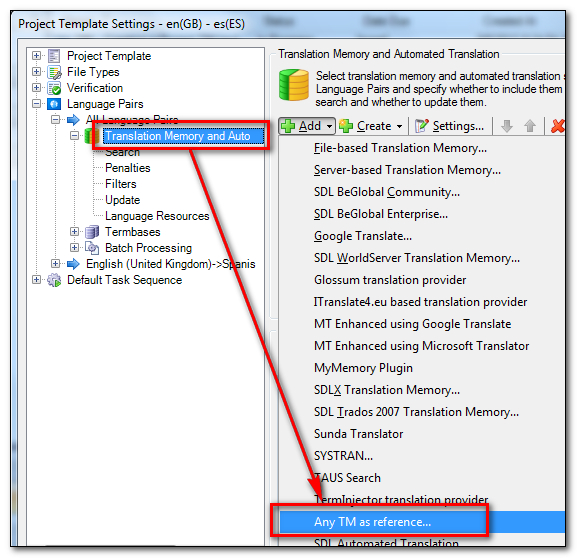
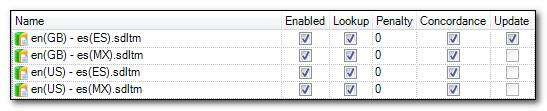
I can then select the translation memories I need by adding “Any TM as reference…” and when I’m finished I should something like this where the TM I will actually update (and take benefit from placeable recognition etc.) is at the top and checked for update. The three coming through “Any TM” are below and are for look up only :
The next part would be to replicate this for each of the four templates you need. I did this by copying the project template from the folder they are saved in and renaming them:
Then I edited the TMs and languages in the Studio UI here:

So I now have these templates after importing them in this view and editing to suit the appropriate combinations of translation memories:

This means that I can start a new Project based on the language pair by using the appropriate template like this:
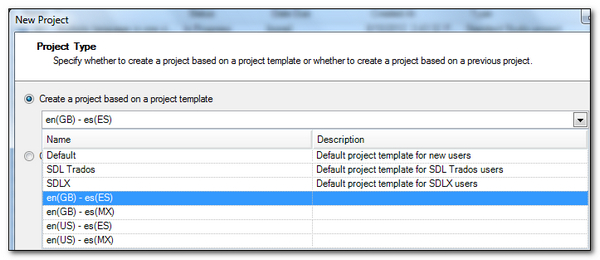
And now I have all four TMs already selected, plus any termbases I added in as well, or any other special settings for QA etc. that I like to use so all I have to do is add the files for translation. I can now get results from the three language pairs that I would otherwise be unable to use… a great new application on the OpenExchange.
Hi Paul! Thanks for sharing this, the AnyTM Translation Provider sounds great. I am wondering whether it also works with server-based TMs?
Hi Christine, I guess if you export the server TM to a file based one then yes you could as this is only for file based TMs. I guess a similar facility would be possible for server based TMs too… why not email the developer and ask? Good idea!
Hi Paul! Thanks! However, I’d fully support Simon Cole’s comment/question below why SDL did not simply (allow to) disable the program error checking for TM language codes: Then we’d be able to directly take advantage of this feature not only for file-based TMs, but also server-based TMs – and possibly other translation providers that are available in Studio by default or via OpenExchange, like WorldServer TMs, legacy Trados 2007 TMs (via the corresponding OpenExchange plugin), etc.
One additional minor comment: I have downloaded the AnyTM installer from OpenExchange and, during installation, the following path is suggested: C:Program Files[developers name]CodingBreeze AnyTM Translation Provider. Well, that’s an unusual path; where would you suggest to actually install it?
Hi Christine, I think it may just be a temporary folder that is created and removed again as I cannot find this on my machine. I did have a test version to write the article before he released it so I didn’t use the installer, but on testing it just now I had the same message and then afterwards no sign of this folder. So my guess is that it’s temporary. I dropped an email to the developer but for now I think you’re safe.
Hi Christine, just to add to this after speaking to the developer. He confirmed that the path asked for here is actually completely ignored, but the simple installer technology used for this application didn’t allow for this step to be skipped. I think he’ll change this when he gets time to look at something with more control. In the meantime he’s updated the current version to show something less concerning in the dialog even though it gets ignored because studio needs the plugins to go to a specific folder in the Studio installation anyway. So no need to worry, or update your installer… just install and use.
Hi Paul! Thanks for checking this! I have meanwhile also found out that the CodingBreeze.AnyTM.sdlplugin is installed in the “normal” plugin folder under C:Users[User]AppDataLocalSDLSDL Trados Studio10PluginsPackages.
Hi Paul
Very interesting reading – thanks for highlighting this. Looks like a great applicaiton.
Just one question: why did it take an external developer to come up with this?
Surely, SDL could have done this in moments by disabling the program error checking for TM language codes and simply allowing other flavours of the same language pair. In your examples, all EN flavours and ES flavours. Clearly, error checking would remain useful if you tried to attach a German language variant to this sample project.
Simon
Hi Simon, a good question. I think historically this has never been allowed with Trados so whilst something like this is probably on the development backlog somewhere it never reached the priorities at the top. It is a great user enhancement and does highlight the power of the Studio platform where we allow any developer more interaction with the core program than ever before. So there is a good opportunity for people to do the things they see as important for them without distracting the SDL developers from the things they need to focus on that are quite strategic in terms of the work being completed for the massive SDL product range as a whole. SDL have around 30 core products (not counting the old ones) now and all of them can be intertwined with each other. The development work for this is quite an intense undertaking so sometimes the things that might seem simple to you and I, are not so simple in terms of the effort required to consider the knock on effect with testing and interoperability throughout the product range. An OpenExchange plugin that’s optional and only interesting for some users is a good way to handle it.
Hi, This looks like a great app. I bought it and have been trying to install it since March 2013!! But, I got this error at install with Studio 2011 and now with Studio 2014:
“Error Writing to File: C:UsersEveAppDataLocalSdlSDL Trados Studio14PluginsPackagesCodingBreeze.AnyTM2014.sdlplugin. Verify that you have access to that directory.”
I am at a loss and kind of frustrated. I know you did not create this app, but the developer is not answering ;( This path does not even exist on my computer. Any ideas? I’d LOVE to use it since I paid for it. Thanks! ~ Eve
Hi Eve, it certainly is a great app and you’ll be even more excited when you see the improvements due shortly. But of course all of this is only good if you can install it in the first place! The developer is normally very responsive but I do know he’s been away for at least a week so I guess he’ll be back to you as soon as picks up his email.
In the meantime, it sounds like a permissions thing… so maybe you can try installing with admin rights? So right-click and install as admin?
Thanks, Paul! The developer did reply today in detail and give me a work around. Hopefully that will work and if not, he said he’d email me directly when he makes the update. Thanks for your assistance!
Thank you Paul, this is just what I need! 🙂