 I’ve been talking about this image for around a year in various presentations where we talked about the plans for Studio 2014. As of today to be able to finally present it as a fait accompli feels good… in fact it feels wonderful! Whilst this is a good headline it’s not everything you get with SP2 and there are some other things in here well worth a mention. I’m not going to cover them all but I will pick out the headliners that I’m pretty sure people have been asking for. But let’s start with terminology because after nearly 8-years of reading about Java problems, and that’s just my time with SDL and the Trados based software, this is a historical moment worth relishing. Quite a nice 30-yr birthday present for Trados too!
I’ve been talking about this image for around a year in various presentations where we talked about the plans for Studio 2014. As of today to be able to finally present it as a fait accompli feels good… in fact it feels wonderful! Whilst this is a good headline it’s not everything you get with SP2 and there are some other things in here well worth a mention. I’m not going to cover them all but I will pick out the headliners that I’m pretty sure people have been asking for. But let’s start with terminology because after nearly 8-years of reading about Java problems, and that’s just my time with SDL and the Trados based software, this is a historical moment worth relishing. Quite a nice 30-yr birthday present for Trados too!
Contents
MultiTerm/Studio improvements
Did I mention that Java has gone? Well it has, so in addition to no more Java errors I can now do this in Studio with the MultiTerm integration:
- Select the termbase viewer and it instantly appears. No more shuddering windows.
- I can add a term with a single click or keyboard shortcut, so no need to follow up the add term with F12, or save. This is possible with the new “Quick Add New Term” option:
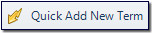
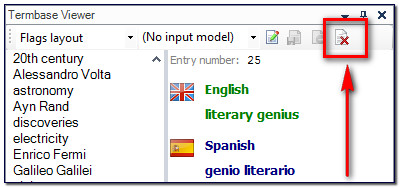
I can still add terms the normal way so if I have more fields I wish to add detail for then this is possible. But if I’m just collecting terms for my simple glossary and to use with AutoSuggest then this is perfect. - I can also delete terms I don’t want in my termbase directly from within Studio which is also something we have not been able to do before. So when you mistakenly add the wrong term as you whizz through with the new “Quick Add New Term” you’ll be able to immediately remove it without having to resort to opening MultiTerm and doing it in there:
- And if I’m also using the Glossary Plugin from the SDL OpenExchange (now RWS AppStore) then my terminology experience is complete! Create a new termbase, import a spreadsheet to create a termbase or export to a spreadsheet… these and more are things I can do for my projects in just a couple of clicks.
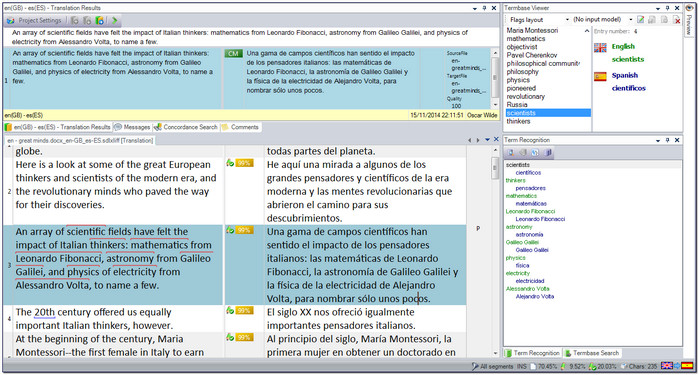
I think I can honestly say that the terminology experience in Trados related products has just gone from less than satisfactory to way above average. Oh yes… did I mention that Java has gone? I’ve also found that moving my windows like the example below is quite a neat and easy way to work giving me complete flexibility over what I think is useful to see and what I need to get access to when working with terminology in Studio. So I have the term recognition window on the bottom right as the list could be long, and then the termbase viewer on the top right. If you’re not sure how to move the windows around maybe review this article when you have a minute or three.
Automatic recognition of Alphanumeric characters
How often have you had product codes like these “NOM-072-SSA1-2012” (Example quoted from a tweet by Emma Goldsmith) throughout a document and would like Studio to be able to handle them all easily as placeables? This is what this feature is all about and for the most part it does a good job without you having to do anything clever at all… it just works! So you see this kind of thing in Studio where each placeable is now recognised with the blue line under each one (obviously I doctored the image as you will only see one at a time in practice!):

This is great because now you’ll only need to confirm one of them to your TM and you’ll get 100% matches for all the rest without having to do any additional work at all. I have tested this with as many examples of product codes and other similar types of things as I could find in ProZ and other forums, and on the whole I think this is a long awaited improvement that works well and is very good to see. However, now take a look at these two that I have made up… well the first is kind of made up, but still based on a real code I came across on a website, and the second is a real code I found in a medical product database:
![]()
Here we see the sort of problem we used to see for the first three. This is because there are exceptions. This is what we see in the updated release notes (the originals were wrong as noted by some of the comments below):
- must not start or end with underscores, hyphens or full stops
- must not contain both dashes and full stops
- must contain at least one number and one letter
- must not contain lowercase characters and dashes
In these last two cases I think we’re also seeing some mixed results based on Acronym recognition and the new Alphanumeric recognition. So not perfect by any means, but still a step in the right direction and will probably resolve placeable issues for the majority of users. The actual rules in the release notes are these:
- Studio now recognizes as tokens (placeables) any strings made up of combinations of:
- Letters (lowercase and/or UPPERCASE) + numbers
- Optionally with:
- underscores: NAME_4001_co
- full stops: BVO.mxm.072.531
- Optionally with:
- UPPERCASE letters + dashes + numbers
- Optionally with:
- underscores: 17620-ZY8_003
- Optionally with:
- Letters (lowercase and/or UPPERCASE) + numbers
I ran a few tests in Studio with a few examples to make these a little more clear (I hope). You can see the results here:
So how can these be handled in Studio? Well you have a couple of options. The first would be to use the TermInjector which I’ve written about in the past so I won’t do this again now, and the second is to use something like Regex AutoSuggest which is a new application available on the OpenExchange from last week. This is very clever and extremely flexible allowing me to handle these last two codes like this for example:
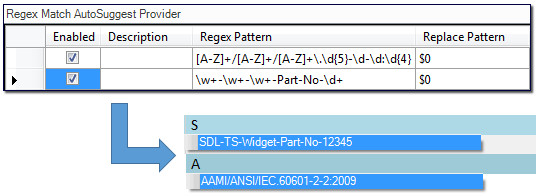
I won’t get the benefit of placeable matching as I do with the Alphanumeric recognition feature, and also with the TermInjector, but I do have a very flexible and instant solution to being able to quickly match the patterns and make use of the Studio AutoSuggest capability for these things. I did this quickly and without trying to refine the expression as “economy of accuracy” is key here. Get what you need quickly and with the minimum of fuss. If you don’t know how to use regular expressions take a look at these articles which are appropriate for Studio.
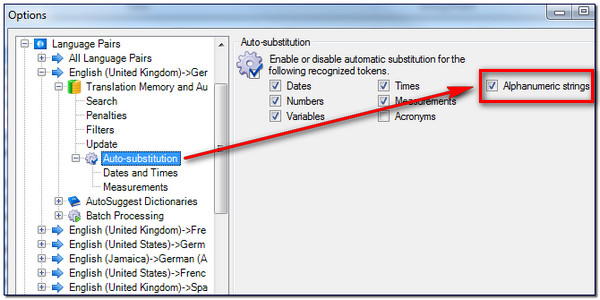
A couple of things I didn’t mention, the first is where do you find this option for using the new alphanumeric string recognition. This is not a global setting, so you won’t find it under All Language Pairs. It’s under the Auto-substitution rules for each specific language pair you work with which allows you to have finer control on a multilingual project. For example, you can see it here under my specific en(GB) – de(DE) language pair:
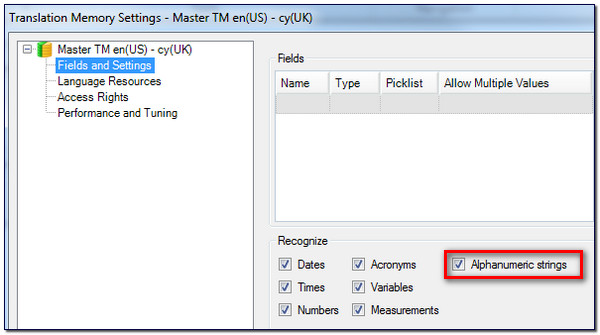
The last but important point to note is that your existing Translation Memories will need to be re-indexed to take advantage of this new capability. So if you install Studio and find that you don’t get any recognition for a placeable that should be recognised then this is most probably the reason. The way to handle this is simple, just go to the Translation Memories View, right-click on a TM and select Settings. Then select Fields and Settings and make sure that Alphanumeric strings is checked:
Finally go to Performance and Tuning and click on Re-index Translation Memory… :
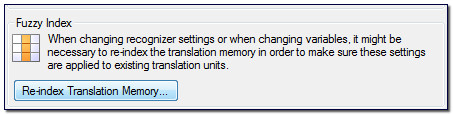
This takes around 20 seconds to do a 50,000 TU Translation Memory on my laptop so the time will vary depending on what you are using. But after this all alphanumeric variables in your translation file that meet the criteria will be recognised with this TM.
UPDATE: There is a small tool available on the SDL OpenExchange (now RWS AppStore) that can do this for you in batches. I did a test with 100 TMs, each containing approx. 50,000 TUs. This took 65 minutes on my laptop. To do one of these TMs manually takes me approx. 1 minute 10 seconds. So assuming I was able to sit there and consistently manually do these one at a time back to back it would take almost 2 hours. But of course I wouldn’t do this so the saving is significant in time and effort. Well worth taking a look if you have a lot of Translation Memories to re-index.
Edit source for (almost) all supported filetypes
This doesn’t need much of an explanation. In the previous version you could edit source for a couple of file formats only; Word and Powerpoint files. SP2 allows you to edit source for all file formats apart from one. That one is ITD which is the bilingual format provided by SDLX. During testing I believe it proved to be too much of a risk as it had the potential to cause problems when returning the files to SDLX, so it has been disabled for this format only. Fortunately this format is on the decline so I don’t see this as a problem.
You still need to allow “Edit Source” on the Project:

But once done, activating Edit Source is simple. Just right-click and select “Edit Source” or use a keyboard shortcut. The default is Alt+F2. This places a gold outline around the source segment and now it can be changed as you see fit. This is another much requested item so hopefully it will be well received:

Sort Translation Memory results by date
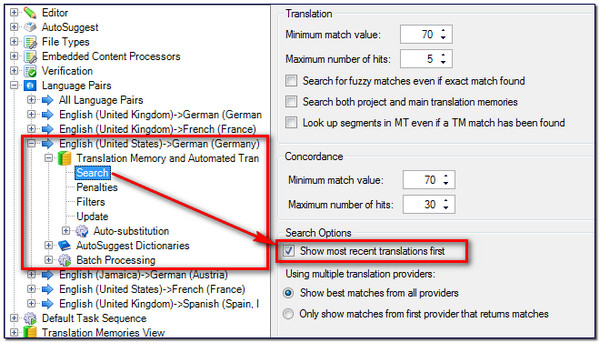
A fairly common posting on the public forums is “How do I show the most recent translations first?”. Seems a fairly straightforward thing to be able to do, but in earlier versions this was not possible. The default behaviour of Studio is now to sort the results by the match value first (CM -> 100% -> Fuzzy value), then by the last edited, and finally the last added translation unit. So this option will ensure that the very last Translation Unit you worked on in your Translation Memory will always come first.
If you want to revert to the old behaviour then you can do so by unchecking the option for this in the Search options for your specific language pair. This can be a global setting on All Language Pairs or set specifically for just one of the language pairs you work with. For example, if I have these six different language pairs set up in my Options and I wanted this setting on only en(US) – de(DE) then I could do this here and this will only effect this one language pair. If I wanted this to be my default setting for all language pairs I worked with then I could make the change in All Language Pairs instead:
Tag Verifier no longer a separate setting on each filetype
If you worked on a Project that contained multiple file-types and you wanted to change the default verification settings for handling tags then you would have to enter the settings for each file-type and change them in each location. SP2 has changed this behaviour and now these are available in a single location as a global option under the verification settings, either in your File -> Options or your Project Settings.

The options themselves remain unchanged, but this is a welcome change making it far easier to control the error messages that are reported as well as moving them to the Verification settings which is a more logical location that on the file-types themselves. In case you have never looked at these before they allow you to control the reporting for these kind of things either as you work or when running a verification check (default keyboard shortcut F8):
- Tags added
- Tags deleted
- Tag order change
- Ghost tags (the greyed out incomplete tag shown here)

- Spacing around tags
- Ignore formatting tags
- Ignore locked segments
- Ignore difference between normal and non-breaking space
Summary
For a complete list of the enhancements in SP2 you should take a look at the release notes that are installed with the release and are also available in the SDL knowledgebase. I think there is a some good stuff in here that will really make the lives of translators a lot easier, including the removal of Java which has been without a doubt the single biggest thorn in the side of our users and support teams for years! If you’ve been wondering whether to take the plunge and upgrade to Studio 2014, or even wondered whether this is the software for you, then there has never been a better time to consider it!
Finally, Java scrapped! Thank God!
I think this calls for a celebration – farewell Java! Next up Nalperion…
Currently the SP2 download link is redirecting endlessly on both http and ftp links.
Hi Daniel, I checked to see if we were getting any reports in support of this being a problem. But we’re not. Drop me an email if this continues and I’ll send it onto an appropriate person to check into it for you.
Oh yes… nearly forgot. SP2 also includes SafeNet which is an alternative for Nalpeiron. So you can replace it now if you were a sufferer of some of the inadequacies related to license servers. So both types of licensing work for now.
Excellent!
Hi, Paul
Thank you for mentioning my application.
I use it regularly as a translator and find it quite useful, so I hope that it will be of a little help for other translators, too.
I’m also happy to hear that Java will be finally removed!
I’ve just realized SP2 can be downloaded from the account page. Can’t wait to use it!
You’re welcome Junya… the Regex AutoSuggest is a fantastic application. Will be very handy for all the budding regex specialists and will encourage many more to learn a little too I think. It’s amazing what you can accomplish with a few simple rules!
Hi Paul, I just finished reading this interesting and informative article following a link on ProZ. So to be able to use Regex AutoSuggest, I would need to enable the AS function in Studio, right? (I remember being told the reasons why AS does not work well with character-based languages, and I have disabled the AS function in Studio since then.)
Yes… but you can then enable only AS for this feature. They are all controlled separately, so if you have less success with one try the other. This app was developed by a Japanese translator so I reckon he gets good use from it and he does show character-based regex on his site. It’s also worth noting that AS comes from multiple sources so whilst the AS Dictionary may not perform perfectly the other do better and you can benefit from these.
Great news Paul! I’m looking forward to being able to add a new term without experiencing motion sickness! (I get terrible motion sickness when that window slides out – I have to look away from the screen… ;)).Jane
Me too… but you could always lock it into place so it’s stationary. This is better, it’s too fast for motion sickness… but I’d still lock it I think!
Thanks – I did try that but the screen I do most of my work on is just a little small to have this locked in place comfortably. So I went back to the motion sickness option. 😉 I’ll experiment with SP2 later in the week.
Glad you liked my alphanumeric string, Paul! It really was very exciting to see it working for the first time, and worth Tweeting about.
Re: the sliding termbase viewer. I think the animation has been removed, so there’s no slipping and sliding any more at all. Good move.
Indeed.. on both counts!
Hi Paul,
I’ve successfully downloaded the SDL Studio SP2, Installation Guide and Release Notes. I will be installing it later today after I’ve delivered my current job.
I’ve also downloaded the SDL MultiTerm 2014 SP2 Installation Guide and Release Notes, but unfortunately I cannot download the SDL MultiTerm 2014 SP2 Desktop Installer. When I click the “Download” button I get the error message below:
*Fehler: Umleitungsfehler
Die aufgerufene Website leitet die Anfrage so um, dass sie nie beendet werden kann.
*
* * Dieses Problem kann manchmal auftreten, wenn Cookies deaktiviert oder abgelehnt werden.*
When I try the “Alternative download via FTP” I get exactly the same message.
Do you have any suggestions how I can down load the MT SP2?
Best regards, Ben
Hi Ben, it does sound like a browser issue and the implementation of cookies. If you can’t resolve it drop me an email and I’ll see what I can do to help you.
Oh, boy! The future is bright indeed. Thank SDL for this update. I love it how you can continue having new things incorporated to the software you’ve already paid for. That’s just amazing. And truly useful things also.
Thank you, Paul, for this enlightening post.
Thank you for fixing the Java issue.
Among various improvements in SP2, there are also “disprovements”:
11. Improved word count and search logic for words containing apostrophes and dashes
Studio 2014 SP2 uses an improved algorithm for processing words that contain dashes (-) or
apostrophes (‘). This improvement translates into:
*Lower word count*. Studio no longer treats apostrophes and dashes as word separators, but as
punctuation marks that link words together. This means that Studio counts elements like “it’s” or
“splash-proof” as one single word.
—
My first reason was WTF: “It’s” is very clearly two words: “It” and “is”.
I can see why a sleazy translation agency would consider this as an “improved” algorithm, and welcome such a misfeature (just another way to pay those pesky translators less). But why should translators consider this as an improvement?
Hi Riccardo,
A sleazy translation agency!! You do have a way with words 😉 I think the first thing to note is that we are always reviewing the feedback on wordcounts because these are an emotive thing and it’s hard to please all the people all of the time. So if we find these are simply inappropriate in some way we’ll review them again in the same way we reviewed them this time. The changes we made are based on customer feedback (not yours clearly!).
An interesting thing here is that the word count is now more consistent across our products and even some competitors products. We have over the years changed this back and forth, and this time it was required to make it more consistent with WorldServer, while at the same time improving fuzzy matching as we will still consider the apostrophe/dash in the matching algorithm to find matches. The most important thing is that we have tried to eliminate differences between work giver and work doer, and we do this with this change. Most importantly, this probably won’t be a final decision either because even the Unicode consortium for example is unsure what to decide – is an apostrophe a word divider or not? I see the point that in some target languages you’ll need two words, but this is a measure based on the source that has to be equally as fair as possible for all target languages.
As a software vendor we do our best, based on customer feedback, to make such changes and to try and provide as much consistency as we can, at least across our own products! When we do, we try to make sure our customers are informed and we have done this down to the details in the release notes. This allows our customers to decide when and how to adopt a new release such as this one and to make any necessary changes to their processes and working habits.
So this is unlikely to be a final solution and we do always have the door open to make further changes if something is simply not working.
Hi Paul,
I’ve run a short test on a short MS Word file (I have it available):
The results are as follows:
Baseline: manual word count: 195 words
Trados 2007 wc: 198 words (+1.5% difference)
Studio 2011 wc: 195 words (0% difference)
memoQ wc: 190 words. (-2.6% difference)
MS Word wc: 190 words (-2.6% difference)
Studio 2014 SP2 wc: 188 words (-3.6% difference)
As you can see, a translator who used to be paid based on a Trados 2007 word count would concede to the translation agency a 5.1% discount just by using 2014 SP2 instead.
What seems to happen with words that may be counted differently
A subset of the file I used for the word count contains the following:
It’s
mid-16th century
Prince-electors
The others who were left in the keep—men, women and children—were killed.
According to my manual word count these are 21 words (I count two words each for “it’s”, “mid-16th”, “Prince-electors”, and of course I count as separate words “keep”, “men”, “children”, and “were”.)
According to MS Word, these are 18 words (it counts as single words “it’s” and the two hyphenated terms, but, of course, it counts as separate words “keep” and “men”, “children” and “were”.
According to Studio 2014, however, these are 16 words: Studio 2014 is not only counting as single words “It’s”, and the two terms that are separated by an hyphen (“mid-16th” and “Prince-electors”), but it also counts as single words those that are separated by an m-dash.
“splash-proof”, of course, does not contain a dash. It contains an hyphen, and the difference is important, especially when not knowing the difference between a dash and an hyphen result in a lowered word count.
Hello Riccardo,
I wanted to clarify a couple of things in here. First of all I changed the apostrophes in your test file to straight apostrophes and ran the comparison again.
2011 – 188 words
2014 – 188 words
I also reran the test with your file in the latest build of 2011 (using a default TM with no custom segmentation rules). This actually reports this:
2011 – 193 words
2014 – 188 words
The reason this happens is because the only change that has been made between Studio 2011 and Studio 2014 SP2 is that curly apostrophes are now treated the same as straight apostrophes. This is to ensure that we have consistency between all of our products (and closer to others too) and in the way these characters are treated. So in your text these are now one word instead of two:
It’s
It’s
Godesburg’s
Cologne’s
region’s
“It’s” will continue to be a hotly debated topic as we know. But what about the last three? Are these two words too?
Unfortunately the release notes were incorrectly written and these will be changed. Studio is still handling hypens/dashes as it always did so there are no changes here at all. I should also mention that there are inconsistencies here too so we can expect to see further improvements to allow us to provide as clear a wordcount as possible. This will all be done with feedback from our Beta testers, from our users, and you Riccardo to ensure we are as fair as possible.
In terms of the actual changes to the overall analysis we have of course added alphanumeric handling which will affect the placeable count and I will update my article at some point soon to reflect the changes there. But generally I expect the alphanumerics to make life easier overall.
So I think the problem here is mostly caused by us getting the release notes wrong, and then this change to ensure handling of apostrophes is consistent has affected the wordcount depending on the content. Fairly or unfairly? I don’t think it’s quite as clearcut as you suggest and comparing to the old Trados that did so many things wrong is also not the right thing to do either. I think most tools will show a lower wordcount than the old Trados so making it sound as though it’s all Studio SP2 is more than a little unfair!
In general I think the benefits to translators in this release are significant, and the improved handling of placeables will reduce the effort involved for text of this nature quite considerably.
Is “man’s” in “The man’s dog” two words? I think it is very clearly not. A word count is just a way of getting an estimate of the work involved it is not an absolute measure of the work to be done. So if the word count comes down up your price to get the same result.
Dear Paul
Java has also often given problems in successive versions of Multiterm Extract. Would you know if Java has been ditched in this module of Multiterm, too?
Best regards
Joost
No it hasn’t. The only applications so far where Java has been removed are the 2014 SP2 releases of Studio and MultiTerm.
Hi Paul, I have some problems with ‘Regex Match Service Provider’ and SP2. Seems that the App doesn’t run. Do you know something about it?
Grazie
Luca
All works well for me… drop me an email and we can look. Maybe it’s as simple as not having checked the rule to make sure it’s enabled, or not having the regexmatchautosuggest provider enabled in the autosuggest options?
Sorry! only seems it does not autosuggest if the ‘code’ start with _
Try using Ctrl+Shift+F12. This is a flaw in the autosuggest that doesn’t pick up escaped characters. The developer provided this workaround until Studio resolves this (if it gets resolved),
Hi, Luca
I am the developer of that plug-in.
As Paul said, use Ctrl+Shift+F12 to pick up string starting with a symbol like “_”, “^”, or “[“.
AutoSuggest does not kick in when these symbols are typed by the user.
You can also leave a comment on my blog if you have any questions.
http://translator-banks.blogspot.jp/2014/11/regex-match-autosuggest-provider-plug.html
This is great news! One of our LA users was having trouble with this recently due to the Java requirements for some of our other software.
Quite a lot of improvements, especially ones I was waiting for. I’m a little curious why “must not contain both dashes and full stops” would need to be an exception though.
I’m sure the developers were working hard to get SP2 out, but I was also hoping to hear some news about an update to the SDL SDK. Is there any chance of getting an update in the near future?
Java “just works,” regexes only work in controlled environments.
There may be over 200,000 people who wouldn’t agree with this statement 😉
Hi Paul, the new recognition option for alphanumeric strings must be enabled for existing TMs, after which the TMs must be re-indexed. However, the Upgrade Translation Memories feature in SP2 (“Output Translation Memories Settings” > “Settings” tab) does not include the new recognition option for alphanumeric strings. This means that we can’t use the TM Export tool in combination with the Upgrade Translation Memories feature to enable this recognition option for a (large) batch of existing TMs.
Hi,
First of all, thanks for yur post, as clarifying as always.
Also just checked that “abc1” and “abc1def2” can be treated as placeables as well, even if they’ve got only lowercase letters (plus numbers).
Are you sure about the uppercase letter thing?
I checked also the uppercase letters requirement in the Relase Notes. So I’m not sure if I’m doing something wrong…
Regards,
… Jesús Prieto …
I answer myself, in case it helps anybody reading the blog:
Just attended te webinar “Discover SDL Trados Studio 2014 Service Pack 2”, and at the end of it I asked the same question to the speaker and he said that the Release Notes are to be edited/ammended.
So be tuned!
Regards,
… Jesús Prieto …
Hi Jesús, I just ran through some tests and can confirm as per this image. Hope this is clear. The release notes will get updated.
Thanks, Paul,
I wasn’t sure I was missing something…
Btw: a really thourough test of yours!
Regards,
… Jesús Prieto …
Hi again, Paul. I’ve just come across a potential issue with variables and alpha-numeric strings. I suppose this situation may be quite rare, but I wanted to share it with you anyway. For Volvo, model names such as “S60”, “V40” and “XC90” are now recognized by Studio as alphanumeric strings, and hence as placeables. Our Variables List, however, also includes the product name “V40 Cross Country”. If both Recognize Variables and Recognize Alphanumeric Strings are ticked, Studio will not recognize “V40 Cross Country” as a variable, but only “V40” as an alphanumeric string. It would seem to make more sense, however, to give variables priority over alphanumeric strings, and not the other way round. Best regards, Lieven
Hi. And on the subject of variables (apologies for diverting from the original subject), should the analysis of a document containing “This is a test for VariableOne.” and “This is a test for VariableTwo.”, with “VariableOne” and “VariableTwo” specified as variables in the TM, not result in 6 words No Match and 6 words Repetition, instead of 12 words No Match (auto-localization penalty = 0, text replacement penalty = 0)? After all, after translating the first segment, the second one is a 100% Match and is automatically translated. Should the results not be the same as for numbers, where “There are 2 sentences.” and “There are 3 sentences.” are shown as Repetitions in the analysis results? Best regards, Lieven
Hi Paul,
This is regarding your answer to my question on Regex AutoSuggest. (I didn’t see a Reply button in your answer.) Just wanted to say your answer has given me some hope to try AS again, at least to try the Regex AutoSuggest app. It’s good to know that the developer also works with character-based target language.
Thank you for sharing all of the information!
Chunyi