 CAT tools typically calculate wordcounts based on the source material. The reason of course is because this way you can give your clients an idea of the cost before you start the work… which of course seems a sensible approach as you need to base your estimate on something. You can estimate the target wordcount by applying an expansion factor to the source words, and this is a principle we see with pseudotranslate in Studio where you can set the expansion per language to give you some idea of the costs for DTP requirements in the finished document before you even start translating. But what you can’t do, at least what you have never been able to do in all the Trados versions right up to the current SDL Trados Studio, is generate a target wordcount for those customers who pay you for work after the translation is complete and are happy to base this on the words you have actually translated.
CAT tools typically calculate wordcounts based on the source material. The reason of course is because this way you can give your clients an idea of the cost before you start the work… which of course seems a sensible approach as you need to base your estimate on something. You can estimate the target wordcount by applying an expansion factor to the source words, and this is a principle we see with pseudotranslate in Studio where you can set the expansion per language to give you some idea of the costs for DTP requirements in the finished document before you even start translating. But what you can’t do, at least what you have never been able to do in all the Trados versions right up to the current SDL Trados Studio, is generate a target wordcount for those customers who pay you for work after the translation is complete and are happy to base this on the words you have actually translated.
You could workaround this of course by running the target file back through the analysis, but it would be nice if you could just run a target wordcount after the translation was complete without having to resort to this workaround.
Another requirement for counting words we often hear about, especially in Switzerland and Germany is a line count. Some customers in these parts of the world like to pay for their work by lines. The standard line being 55 characters including spaces… although I believe Belgium sometimes uses 60 characters per line, again including spaces. You can work around this as well by taking the character count, adding the number of words to it (to account for spaces… one word has an equivalent space) and then dividing by 55 or 60… or whatever the requirement. That would provide a reasonable estimate.
Or you could use a tool like AnyCount of course which offers quite a range of options for analysis… but this may not be suitable for all the files you are translating as it doesn’t support as many formats as your translation tools, and it may not support customisation of the formats to manage non-translatable texts in the same way you can with Studio. And of course it does not support SDLXLIFF files in case you were working on a package and wanted to use a feature like this. In any event, it would be better to have this capability in your translation tool in the first place and then you would not need to run two applications to get your target wordcount, or line counts, for payment.
This is where the SDL AppStore comes in as there is now a neat plugin called “Target Word Count” developed by Jesse Good (a prolific and very helpful developer) that is capable of producing an analysis for the target wordcount or a customisable line count.
Target Word Count
The application works in the same way you run an analysis or a source wordcount… via a batch task. This one is installed when you download and install the sdlplugin from the SDL Appstore. If this screenshot looks different to yours it’s because I hid all the other tasks for clarity:

When you run the task you are presented with a rates table (I randomly filled these in and hopefully won’t start a discussion over rates!!) which you can optionally fill in, and you are also given the opportunity to save the rates you use. This is quite useful if you have different rates for different customers as you can easily load the correct rates for the job and save typing them all in again. You can also add in your characters per line for the linecount report if you wish, and optionally create a source count or separate any locked segments:
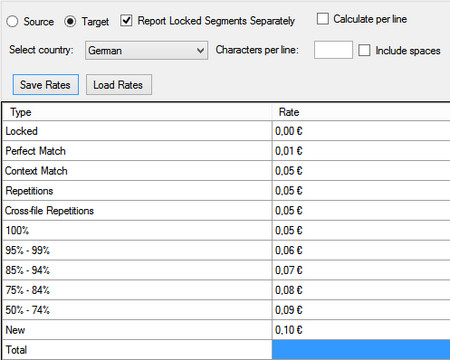
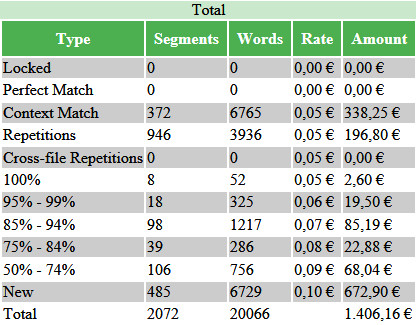
The reports can then be found in the reports view in Studio, summarised as shown below but also with a breakdown by file if you have worked on multiple files. The target wordcount looking like this:
Selecting the linecount offers a slightly different interface as you only need to complete the rates for the line:
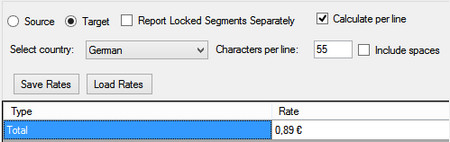
Then a simplified report:

Very straightforward, and probably the start of more to come as Jesse sees more use from an app like this. So simple, and yet so helpful!! You can also save the report in all the same formats as the out of the box reports from Studio… so Excel (XLSX), HTML, MHT and XML.
Nice work Jesse!
Jesse has been Good to us.:-)
Hi Paul, I am afraid that it looks like the final log is upside-down. The type of segment indicated in the first log is inverted in the second, but the rates are not. So you have 125 new words at Euro 0! Something clearly wrong.
But I would also like to add that I hope this “return to the past” or target count will not catch on. When translating in the 80’s I found it extremely unfair that I got paid less than colleagues translating the same material into other languages, e.g. French, because English is more concise!
Hello Juliet, well spotted!! I’ll report to the developer who I’m sure will resolve this quickly.
Will it catch on… I doubt it. I think this is just something some people already have to deal with and this just makes it easier for those who do. Perhaps it works better for others 🙂
Jesse resolved this quickly… I amended the images in the article accordingly. Thanks Juliet.
The plugin is on AppStore, which redirects to github, and the plugin is unsigned. Is this how it should be?
Your timing might be unlucky. Jesse just fixed the problem identified by Juliet in the comment below. I have signed it but perhaps you downloaded before he updated it.
OK so I will reinstall it not to be nagged by the Studio message. Will installing again on top of the existing version work?
Yes… if you use the plugin installer. So just double click it and the installer will remove the unpacked folder as well as the old plugin file.
Weird thing, thing, the plugin I downloaded from github was still unsigned, or running the installation again did not remove the old, unsigned version. Can’t tell which. Hiow do I remove the plugin completely before installing anew?
Hi Piotr, I just tested this and it is definitely signed. Maybe try a manual fix. First delete these two things:
c:Users[USERNAME]AppDataRoamingSDLSDL Trados Studio12PluginsPackagesTargetWordCount.sdlplugin
c:Users[USERNAME]AppDataRoamingSDLSDL Trados Studio12PluginsUnpackedTargetWordCount
Then install the plugin again.
I downloaded the plugin from github and checked it for signing. It is the same signed version we provided. You can verify this with the checksum (2dc2618405b670b07e8b4b762dbe93b57174de8b) This app allows you to verify checksums : OpenX Hash Generator
Problem solved. It simply refused to install on top of the already installed plugin. Had to manually remove the plugin first.
Hi Paul
when I run the batch task on multiple files, I only get a file by file breakdown and not project level (ie complete set of files which also shows cross-file reps).
I’ve downloaded the plugin this morning (latest release) and have run the batch task at both file and project batch task level.
Any idea what is going wrong or is this the expected behaviour?
thanks in advance
kate
Hi Kate, probably a limitation of the plugin. I would suggest you post this question into http://community.sdl.com/appsupport where the developer is very responsive to all questions around his apps.
Hi Kate,
Sorry for the trouble!
I’ve updated the plug-in to use at the project level.
https://github.com/jessegood/Leo.TargetWordCount/releases/tag/v1.1
Let me know if you have any other problems.
Another question on this. I downloaded the latest version from the app store (I downloaded in june 2017).
when I run the batch task (without having updated the starting project tm), the target analysis log on 3 files reveals fuzzy matching and context matching. I dont understand how this can produce these results against what is in theory an empty tm? Our target analysis should reflect the source analysis in reverse.thanks in advance
Me neither… I think it expects there to be text in the target when you run this task. Probably a good one to ask the developer.
Hi. What I’d like to see in TRADOS is a way to exclude locked segments from the Not Translated character count in Editor view. What’s important to me is how much work I have left, not how long the document is…
You could use the Work In Progress batch task which is designed for this purpose… fast and easy to use. You should also post your idea in the ideas site – http://ideas.sdl.com