 Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Using segmentation rules on your Translation Memory is something most users struggle with from time to time; but not just the creation of the rules which are often just a question of a few regular expressions and well covered in posts like this from Nora Diaz and others. Rather how to ensure they apply when you want them, particularly when using the alignment module or retrofit in SDL Trados Studio where custom segmentation rules are being used. Now I’m not going to take the credit for this article as I would not have even considered writing it if Evzen Polenka had not pointed out how Studio could be used to handle the segmentation of the target language text… something I wasn’t aware was even possible until yesterday. So all credit to Evzen here for seeing the practical use of this feature and sharing his knowledge. This is exactly what I love about the community, everyone can learn something and in practical terms many of SDLs customers certainly know how to use the software better than some of us in SDL do!
Tag: translation memory
Spaces and Units…
 The handling of numbers and units in Studio is always something that raises questions and over the years I’ve tackled it in various articles. But one thing I don’t believe I have specifically addressed, and I do see this rear its head from time to time, is how to handle the spaces between a number and its unit. So it thought it might be useful to tackle it in a simple article so I have a reference point when asked this question, and perhaps it’ll be useful for you at the same time.
The handling of numbers and units in Studio is always something that raises questions and over the years I’ve tackled it in various articles. But one thing I don’t believe I have specifically addressed, and I do see this rear its head from time to time, is how to handle the spaces between a number and its unit. So it thought it might be useful to tackle it in a simple article so I have a reference point when asked this question, and perhaps it’ll be useful for you at the same time.
I have a background in Civil Engineering so when I think about this topic I naturally fall back to “The International System of Units (SI)” which has a clear definition on this topic:
More power to the elbow… upLIFT
 “More power to the elbow”… this is all about getting more from the resources you have already got, and in this case I’m talking about your Translation Memories. In particular I’m talking about enabling them for upLIFT. upLIFT, in case you have not heard about this yet despite all the marketing activity and forum discussions since August this year, is a technology that is being used in SDL Trados Studio 2017 to enable some pretty neat things. I’m not going to devote this article to what upLIFT is all about as Emma Goldsmith has written a really useful article today that does a far better job than I could have done. You can find Emma’s article here, called “SDL Trados studio 2017 : fragment recall and repair“. But a quick summary to get us started is that upLIFT enables things like this:
“More power to the elbow”… this is all about getting more from the resources you have already got, and in this case I’m talking about your Translation Memories. In particular I’m talking about enabling them for upLIFT. upLIFT, in case you have not heard about this yet despite all the marketing activity and forum discussions since August this year, is a technology that is being used in SDL Trados Studio 2017 to enable some pretty neat things. I’m not going to devote this article to what upLIFT is all about as Emma Goldsmith has written a really useful article today that does a far better job than I could have done. You can find Emma’s article here, called “SDL Trados studio 2017 : fragment recall and repair“. But a quick summary to get us started is that upLIFT enables things like this:
- fragment matching
- whole Translation Units
- partial Translation Units
- fuzzy match repair
- from fragment matching
- from your termbase
- from Machine Translation
Recording Translation Memory metadata
 Back in July 2013 I wrote an article called “Fields and Attributes in Studio” which was all about adding different types of metadata to your Translation Units every time you confirmed a segment to make it easier, or more complex depending on what you’ve done, to manage your Translation Memories. If you’re not sure what I mean by this take a look at the article as I won’t repeat a lot of that here… at least I’ll try not to! This capability in Studio is probably quite familiar to most users of the old SDL Trados 2007 and earlier, and was even essential to some extent because you could only use a single Translation Memory at a time.
Back in July 2013 I wrote an article called “Fields and Attributes in Studio” which was all about adding different types of metadata to your Translation Units every time you confirmed a segment to make it easier, or more complex depending on what you’ve done, to manage your Translation Memories. If you’re not sure what I mean by this take a look at the article as I won’t repeat a lot of that here… at least I’ll try not to! This capability in Studio is probably quite familiar to most users of the old SDL Trados 2007 and earlier, and was even essential to some extent because you could only use a single Translation Memory at a time.
Bilingual Excel… and stuff!
 I’ve written about how to handle bilingual excel files, csv files and tab delimited files in the past. In fact one of the most popular articles I have ever written was this one “Creating a TM from a Termbase, or Glossary, in SDL Trados Studio” in July 2012, over three years ago. Despite writing it I’m still struggling a little with why this would be useful other than if you have been given a glossary to translate or proofread perhaps… but nonetheless it doesn’t really matter what I think because clearly it was useful!
I’ve written about how to handle bilingual excel files, csv files and tab delimited files in the past. In fact one of the most popular articles I have ever written was this one “Creating a TM from a Termbase, or Glossary, in SDL Trados Studio” in July 2012, over three years ago. Despite writing it I’m still struggling a little with why this would be useful other than if you have been given a glossary to translate or proofread perhaps… but nonetheless it doesn’t really matter what I think because clearly it was useful!
So, why am I bringing this up three years later? Well, the recent launch of Studio 2015 introduced a new filetype that seems worthy of some discussion. It’s a Bilingual Excel filetype that allows you to handle excel files with bilingual content in a similar fashion to the way it used to be possible in the previous article. There are some interesting differences though, and notably the first would be that you won’t lose any formatting in the excel file which is something that happened if you had to handle files like these as CSV or Tab Delimited Text. That in itself mught be interesting for some users because this was the first thing I’d hear when suggesting the CSV filetype as a solution for handling files of this nature. Most of the time I don’t think this is really an issue but for those occasions where it is this is a good point.
Converting Wordfast resources… out with the old!
 This article is all about out with the old and in with the new in more ways than one! In the last week I have been asked three times about converting Wordfast translation memories and Wordfast glossaries into resources that could be used in Studio and MultiTerm. Normally, for the TXT translation memories I get I would go the traditional route and use a copy of Wordfast to export as TMX. Then it’s simple, but what if you don’t have Wordfast or don’t want to have to try and use it? Wordfast glossaries are new territory for me as I’d never looked at these before. But on a quick check it looked as though they are also TXT files so I decided to take a better look.
This article is all about out with the old and in with the new in more ways than one! In the last week I have been asked three times about converting Wordfast translation memories and Wordfast glossaries into resources that could be used in Studio and MultiTerm. Normally, for the TXT translation memories I get I would go the traditional route and use a copy of Wordfast to export as TMX. Then it’s simple, but what if you don’t have Wordfast or don’t want to have to try and use it? Wordfast glossaries are new territory for me as I’d never looked at these before. But on a quick check it looked as though they are also TXT files so I decided to take a better look.
Before I get into the detail I’ll just add that I’m not very familiar with Wordfast so I’m basing my suggestions on the small number of files I have received, or created, and the process I used to convert them to formats more useful for a Studio user. I’ll start with the glossaries as this is where I got the idea from, I better explain my opening statement too… this is because after I did an initial conversion using the Glossary Converter from the SDL Openexchange I was asked to explain how this would work with MultiTerm Convert. This of course made me think about the old versus the new… I wouldn’t compare Wordfast and Studio in this way at all 😉 Continue reading “Converting Wordfast resources… out with the old!”
Working with shared resources…
 One of the reasons SDL Trados Studio, and Trados before that, has been such a popular choice for translators and small teams is the ability to work with shared resources. Many Translation Environments require the use of a server solution in order to share work and if you only do this occasionally, or if you work with a couple of colleagues, then whilst the server solutions can offer a lot of additional capabilities they are often over the top for simple sharing needs and may even require you signing up for things you may not be interested in.
One of the reasons SDL Trados Studio, and Trados before that, has been such a popular choice for translators and small teams is the ability to work with shared resources. Many Translation Environments require the use of a server solution in order to share work and if you only do this occasionally, or if you work with a couple of colleagues, then whilst the server solutions can offer a lot of additional capabilities they are often over the top for simple sharing needs and may even require you signing up for things you may not be interested in.
Sharing resources at a simple level is pretty straightforward with Studio because they are mostly file based. So you have a Translation Memory (*.sdltm), and a termbase (*.sdltb) for example, both of which can be accessed by several translators at the same time. You may well have read that several times just to make sure this is what I actually said! If this is possible then why do we sell server solutions at all, as we have SDL GroupShare, SDL WorldServer and SDL TMS? The reason of course is that sharing a filebased resource like this has many limitations and it’s not a solution for serious Projects. Limitations like these that are detailed in KB Article #5098 in the SDL Knowledgebase:
Continue reading “Working with shared resources…”
The ATA55 in Chicago and the SDL OpenExchange (now RWS AppStore)… which apps?
 This year at the ATA in Chicago all the tool vendors who attended the event were given the opportunity to run a little “Tool Bar” where attendees could come and ask any question they liked. This was a great initiative, and despite the first day where we were perhaps mistakenly tucked away under the arctic air conditioning in the corner where nobody could see us, I think they were very well attended. Certainly from an SDL perspective we were non-stop from the moment we started till the end of each day. It was a great experience for us as we get to meet lots of new users and many we only speak to by email, or on twitter, and I hope it was an equally great experience for anyone who attended.
This year at the ATA in Chicago all the tool vendors who attended the event were given the opportunity to run a little “Tool Bar” where attendees could come and ask any question they liked. This was a great initiative, and despite the first day where we were perhaps mistakenly tucked away under the arctic air conditioning in the corner where nobody could see us, I think they were very well attended. Certainly from an SDL perspective we were non-stop from the moment we started till the end of each day. It was a great experience for us as we get to meet lots of new users and many we only speak to by email, or on twitter, and I hope it was an equally great experience for anyone who attended.
Continue reading “The ATA55 in Chicago and the SDL OpenExchange (now RWS AppStore)… which apps?”
Working with Studio Alignment
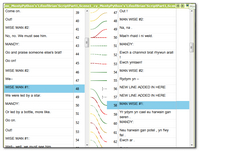 Note to the wise: This article is quite some years old now and the alignment tool has improved a lot with many more useful capabilities since Trados Studio 2021. But there may still be some value in this one so I’m leaving it here for posterity!
Note to the wise: This article is quite some years old now and the alignment tool has improved a lot with many more useful capabilities since Trados Studio 2021. But there may still be some value in this one so I’m leaving it here for posterity!
The new alignment tool in Studio SP1 has certainly attracted a lot of attention, some good, some not so good… and some where learning a few little tricks might go a long way towards improving the experience of working with it. As with all software releases, the features around this tool will be continually enhanced and I expect to see more improvements later this year. But I thought it would be useful to step back a bit because I don’t think it’s that bad!
When Studio 2009 was first launched one of the first things that many users asked for was a replacement alignment tool for WinAlign. WinAlign has been around since I don’t know when, but it no longer supports the modern file formats that are supported in Studio so it has been overdue for an update for a long time.
Upgrading your leverage
 I’m onto the subject of leverage from upgraded Translation Memories with this post, encouraged by the release of a new (and free) application on the SDL OpenExchange (now RWS AppStore) called the TM Optimizer. Before we get into the geeky stuff I want to elaborate on what I mean by the word “leverage” because I’m not sure everyone reading this will know.
I’m onto the subject of leverage from upgraded Translation Memories with this post, encouraged by the release of a new (and free) application on the SDL OpenExchange (now RWS AppStore) called the TM Optimizer. Before we get into the geeky stuff I want to elaborate on what I mean by the word “leverage” because I’m not sure everyone reading this will know.
Let’s assume you have been a translator for years (English to Chinese), and you always worked with Microsoft Word and Translators Workbench. TagEditor came along, but you didn’t like that too much so you kept working with Word and Workbench. It had its problems, but until Studio came along and in particular Studio 2014, you were still quite happy to work the same way you had for years. But now you wanted to buy a new computer, and you really liked the things you’ve been reading about Studio 2014 so you took a leap and purchased a license of Studio. The first thing you want to do is upgrade your old Workbench Translation Memories so they could be reused in Studio. You’ve got around 60,000 Translation Units in one specialised Translation Memory and you really need to be able to have this available as soon as possible to help with a job you know is just around the corner. You upgrade the Translation Memory and this worked perfectly!