 Update Sept 2016: You can find an excellent filetype plugin for JSON files on the SDL AppStore if you don’t want to tackle this yourself.
Update Sept 2016: You can find an excellent filetype plugin for JSON files on the SDL AppStore if you don’t want to tackle this yourself.
The JSON files… not really related to Jason Voorhees of course, but for some users who have received these file types for translation the problem of how to handle them and extract the appropriate text may well seem like an episode of Friday the 13th! I’ve seen a few threads in the last couple of weeks sharing various methods for handling these files ranging from opening them in MSWord and applying a hidden style to the parts you don’t want, to asking vendors to create variations on javascript filetypes. But I think Studio offers a much simpler mechanism for handling them out of the box.
So what are these file types and how can you handle them with Studio 2014, or even 2009/2011? In this article I’m going to look at the regex filetype as this is very well suited to files like this, but before we get into that detail let’s take a look at what they are.
JavaScript Object Notation
This filetype is a simple text based format that was introduced around 2001, so it’s nothing new, and it’s used as a method of sharing data between aplications irrespective of the programming language used. For those of you are interested in this stuff it was derived from the ECMAScript programming language and you can find the full specification for it on the JSON website.
I like to read this stuff to an extent, but really I stop at the point where I can figure out how to get at the translatable text. The format of these JSON files is based on a simple structure which I have taken straight from the JSON specification:

The four components on the left represent the structure components and the image on the right is an example file coloured to show you which components are which. Now, the reason I did this is because these files can contain any kind of data, and the important part is for you to know which parts are translatable. If you translate something that should not be translated then it’s likely that the file won’t be fit for purpose when you give it back to your client.
How do you know what should be translated and what should not? You ask your client!!
Handling the file in Studio
Once you know what’s translatable the next step is to create a filetype in Studio to handle this. It’s actually quite straightforward using the regex filetype. The steps are like this:
Create new filetype
Go to File -> Options -> Filetypes and then select New… Select the “Regular Expression Delimited Text” type and click on OK.
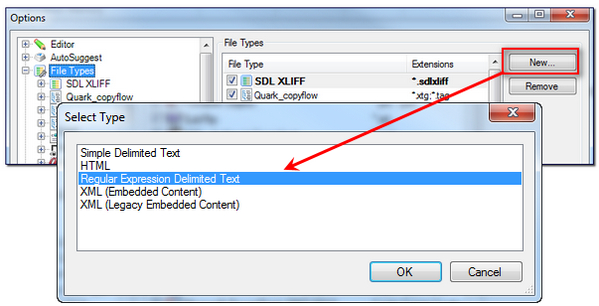
Once you’ve done this you give the new filetype a little bit of information:
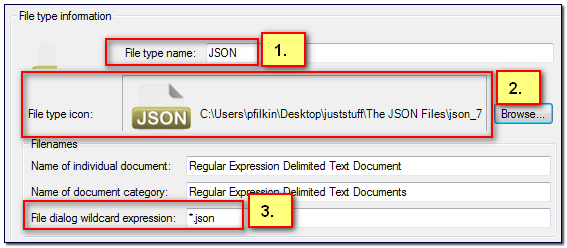
- Filetype name: you can call this whatever you like. I called it JSON
- File type icon: this is completely optional, but as I have never actually done this before in Studio I thought I’d try it! If you want the icon file I used you can download it from here.
- File dialog wildcard expression: this is just the file extension written like this *.json so that Studio knows to use this filetype when you open a JSON file.
Click on OK and that’s it. Your filetype is created! Not too hard was it and you can now open a JSON file and translate it in Studio. However, using my example file which you can find here if you would like to play with it, and you don’t scare easily, the result isn’t too clever because the default will just extract everything in the file like this:
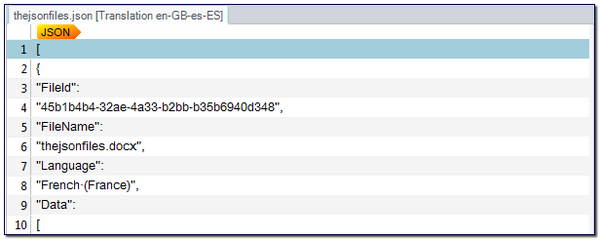
So the next thing you have to do is tell the filetype what you actually want to see in the editor for translation. This is why it’s important to speak to your client so you understand the requirements of the job.
The files I have seen so far all seem to follow the same principle for the translatable text. You have a String at the start followed by a Structural colon and then another String or Number, finally ending in a Stuctural comma like this:
"FileId": "45b1b4b4-32ae-4a33-b2bb-b35b6940d348", "FileName": "thejsonfiles.docx", "Language": "French (France)", "Film": "Friday the 13th", "Year": 1980, "Director": "Sean S. Cunningham", "Writer": "Victor Miller", "Producer": "Sean S. Cunningham", "Synopsis": "Friday the 13th is a 1980 American slasher film etc.", "UtcDateTime": "2015-03-16T22:52:36.1622185Z" "Recorded": true,
The first string represents an identifier of some sort, similar to an element name in an XML file. The second string contains the translatable text. So all you have to do is extract the contents of the second string. We do this using our old friend the regular expression. However, you still need to know if all of them are translatable or only some, and then once you do you can create your expression to suit. The expressions go in here:
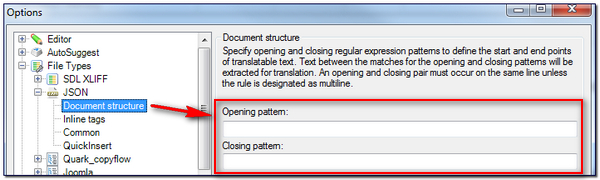
You need two, an opening pattern and a closing pattern. The translatable text will be the text that is inbetween these patterns. So in a line of text that contains code you don’t wish to translate you can move the text found by the opening pattern into the hidden part of the editor so the translator doesn’t have to deal with it; similarly for the closing pattern. So using Regex Buddy (my preferred tool for this stuff) let’s look at a couple of examples and what they would extract. If you don’t understand how to use regular expressions I’d really recommend you learn a few basics, they are incredibly useful. You can find four articles here on how they can be used in Studio that I have written in the past… starting with simple explanations and leading up to slightly more complex examples.
Extract all the second strings
".*": " ",$
The first line is the opening pattern and the second line the closing pattern. The first line basically means look for a quote, then look for anything and keep looking until you find the next quote followed by a colon, then a space and then a colon. So this opening pattern should select the following segments only and make the coloured parts structural ie. hidden in the editor:

The closing pattern is just going to find the last quote and comma and move that into the structure so it’s also hidden in the editor. So when you add these rules into the filetype you see this on opening my test JSON file:
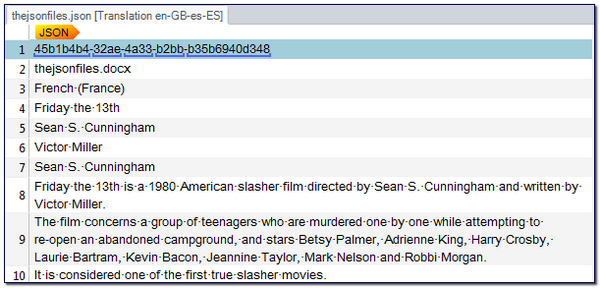
This is much better because now all the JSON structural elements are gone and I’m only getting the second string extracted for translation. However, some of these don’t need to be translated at all so I can further refine my filetype by using a different rule.
Extract only named strings
"(Film|Director|Writer|Producer|Synopsis)".*?" ",$
This time I am saying look for a quote and then find any of the words between the pipe symbols followed by a quote, and then anything at all up to the very next quote. So in effect I extract this:
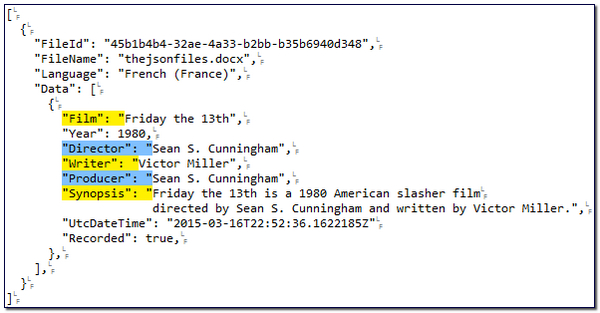
This is because I don’t think I need to translate any of the other strings at all. In reality I guess I would only translate Film and Synopsis from this file, but this is just an example! So have a play and you’ll see how simple this is to work with. However, if the file contains many different translatable strings then the list of identifiers is going to get longer and longer. In this case it might be easier to specify what you don’t want instead!
Extract everything apart from named strings
"(?!FileId|FileName|Language|UtcDateTime)w+".*?" ",$
With this expression we are using something called a negative lookahead… wonderful names but quite sensible. This means take a look ahead of you and see what’s coming, if it doesn’t match the following text then it’s what we want. So the opposite of a positive lookahead where it would match what it found. Maybe takes a little getting your head around, but have a play!
So the expression says look for a quote and then look ahead to see if any of the following words between the pipe symbols match. If they do then don’t use this segment, but if they don’t then look for any word character, one or more, followed by a quote, and then anything at all up to the very next quote. So in effect extracting exactly the same as before. But this time I used a rule to specify what I didn’t want rather than what I wanted!
Phew… makes your head go giddy! But in Studio I now see this:
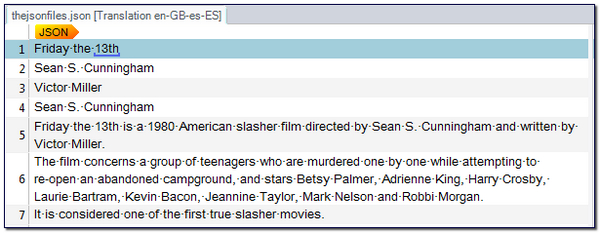
Exactly what I wanted. The beauty in this of course is that the simplicity behind the JSON concept translates nicely into the simplicity of the regex filetype!
A final note here on SDL Passolo after Daniel reminded me! If you want to have full native functionality with JSON files out of the box then you should really create your translation projects in SDL Passolo in the first place. Here you have full control out of the box over all aspects of this filetype including developers comments etc. You can read a little about this here. You will need the full version of Passolo to create the projects in the first place as the free Translator Edition will not allow this. But if you are serious about working with these filetypes then it’s worth the effort. So this article provides, I hope, a good workaround for anyone sent JSON files and they don’t have the full version of SDL Passolo. Perfect for the occasional job but perhaps lacking if you are going to make a habit of it and need to accommodate more variations in the content than I have shown here.
Easy to follow instructions, clear and precise. Thanks Paul.
Excellent article; good practical example of how to apply the regular expression features when creating/adapting a FileType with specific requirements.
This is where Studio ‘Sparkles’ and I am surprised with how many people are unaware or not will to venture into this area to help Studio work for you!
We need to see more of these.
Greetings 🙂
P.
Great instructions, Paul, I really appreciate your work in bringing advanced regexes to the masses :). I had to do a JSON analysis a couple of weeks ago and I ended up using a regex file type as well.
Another method I considered was converting the JSON to XML and then using a custom XML file type (I think this is the method that Joakim was alluding to in the proz thread). JSON->XML->JSON conversion should be lossless as long only element values are modified in the XML, so this method should safe. However, the manual conversion work can be avoided by using the regex type, so I chose that. The XML method might be better for someone who’s familiar with the custom XML types but isn’t comfortable with using regex types (although it should be simple enough with your instructions).
One thing that should be kept in mind with JSON conversion is that often JSON is generated with custom functions (or formatting is flattened to save space), so the formatting might not always be identical. For instance, there might be multiple key value pairs on one line, like this: {“Director”: “Sean S. Cunningham”,”Writer”: “Victor Miller”}. In cases like this the dollar sign in the closing tag wouldn’t match correctly. It’s probably a very rare occurrence, though, but just in case, here’s a link to a site where you can change the formatting of JSON file to a clean format: jsonformatter.curiousconcept.com
Thanks Tommi, and you’re right of course that when the data is condensed in this way it does get trickier. This is where Passolo would do a better job, but I like the website you suggested. Perhaps when on a long flight with nothing better to do than sleep, watch films or read a book it might be fun to see if a regex can be created to handle this scenario too! Complex perhaps, but I’m sure possible.
The problem with Passolo is the sentence-level segmentation, in particular the extremely-long-standing bug in SRX segmenter which I described at http://www.proz.com/forum/sdl_passolo/276433-passolo_srx_segmenter_bugs.html and also at http://www.proz.com/forum/sdl_passolo/276433-passolo_srx_segmenter_bugs.html.
And no one seems to care since the exactly same problem is present also in the latest Passolo 2015 update…
The problem may not be noticeable if your source language is English, but it made Passolo totally useless when my source language was German… I had to switch to Studio in the end :-(.
The good old days of Passolo seem to be gone… back in the days when we worked with Passolo guys close together, fighting .NET parser bugs in Passolo 4 beta…
Ooops, the second link should go to original Passolo forum: http://www.passolo.com/forum/viewtopic.php?t=1163
Hi. I’m using Studio 2015. We’ve been sent some JSON files in which all the strings seem to have been put on a single line. Additionally, in each case the first string is the same as the second string. When I created the filetype there was already a pattern in the filetype (Opening with ^ and closing with $). Should this be deleted? I have tried putting the structural pattern you suggested in and both the first and second strings are being imported into Studio. Any suggestions would be welcome.
You need to modify this for your case, and pick out only the parts of the entire string you want. For eaxmple I did one to help someone else in a similar situation last week. Used an opening pattern like this:
“Content|Question”:”
Closing pattern like this:
“,
Maybe that will help you a little. This is all about using regex to extract what you wish.
Thanks Paul. I don’t think specifying the text for the opening string of each string pair is a practical option for me as there are nearly 600 string pairs in each file, each unique and duplicating the text of its second string.
There doesn’t seem to be any file data. All the string pairs seem to be for translation. In Studio, the first segment is coming up with { and the last segment is coming up with }. The other segments are showing
“string”:
or
“string”,
depending on whether it’s the opening string or closing string. In some cases segmentation is occurring mid-string
Opening the file in Notepad seems to confirm that the only text outside of the translatable strings is the curly bracket at the beginning of the file and the other one at the end.
What I need the filetype to do therefore is to leave out the curly brackets, to leave out each of the opening strings and to leave out the quote marks and commas around the second strings
Is the pattern that I mentioned that appears by default (opens with ^ closes with $) an essential component? I wondered if it might be overriding the pattern that I added, so I tried to remove it, but this seems to make Studio not recognise the filetype at all.
Lots of head-scratching going on.
Hi Malcolm,
The default pattern says start at the beginning and finish at thenend, extract everything you find. This is not what you want for this file. I think the pattern I gave you will work, based on the sparse information you have provided, so perhaps something like this:
“string”:”
Closing pattern like this:
“,
I’d really need the file to confirm this because if you don’t understand what these rules are doing then this alone won’t help you. You need to make the rule do what you need.
Malcolm, if I understand it correctly, then all what you need is to “beautify” (or “prettyprint”) the JSON file before you put it in Studio. Just use one of the many online JSON beautifiers, or use e.g. “JQ” command line utility (http://stedolan.github.io/jq/) to reformat your JSON from single loooooong line to human-readable form, expected by the Studio parser.
Paul, I believe that Studio should be improved to be able to read JSON files as real JSON format, not as plain text files using regexes. The current support is half-baked and needs to be worked on.
It’s not half baked.. there isn’t one! That’s why I used the regex solution. The best approach is probably to use Passolo for JSON files but if you don’t wish to do that then this is the solution to try. I have maned to handle these files in a single line without the beautification but you’re right in that this will make it easier if possible. I haven’t tried them before but will take a look now you mention it.
Thanks
Hehe, if there isn’t one, it’s even worse ;-).
Anyway, it’s my understanding that Malcolm’s file is rather some form of stringtable, i.e. the “name” part in the name/value pair is different for each string… so the approach with defining the start regex by including the actual “name” content would a) be a total overkill, and b) the regex parser would probably not be able to parse such HUGE and LONG regex.
If that is the case I’d agree… I assumed he meant “string” to be the name with the content all different. I suppose if it was all translatable text then he could use something like this which may be worth a go:
“.*?”:”
Closing pattern like this:
“,
Really need the file to have a proper stab at it. Also note that the commenting in wordpress converts my straight quotes to curly, so don’t copy paste without editing them.
Another reason to develop real JSON parser – when you get JSON like this, you’re basically screwed:
{
“text”: “a function”,
“translated”: “”
},
{
“text”: “tap there”,
“translated”: “appuyez ici”
},
{
“text”: “more”,
“translated”: “plus”
},
As you see, there are 2 issues:
1) the translation should go to a different JSON element than where the source is
2) strings are partially translated
And please no “better to use Passolo for this”. While it may be very true, I suppose if someone would spend a fortune for buying Trados Studio, your suggestion to spend another fortune for buying Passolo is not what (s)he’s after…
Thanks Paul and Evzen.
I ended up doing a workaround via MS Word (opened it in MS Word, converted the whole lot to a three column table, one essentially blank apart from the opening and closing curly brackets, one with the opening “strings”: and one with the actual to-be-translated “strings”, then hid the unwanted columns before processing in Studio). I did a full round trip with pseudo-text and got the client to check that the output worked as they wanted.
Downsides: the quote marks and commas remain in the segments in Studio, so the translator will have to be given firm instructions to make sure they remain. I also don’t know how well this will work if we ever get ‘proper’ JSON files.
Our client is an occasional repeater and the person who used to deal with the files used an Okapi-based workflow, but the software interface seems to have changed, so the instructions she left behind were not very clear.
I will have another stab at the regex method (I hadn’t thought about the straight quotes/curly quotes issue so that may have added to my problems) as they are likely to come back and I’m not entirely satisfied with my workaround.
As my description appears to have been less than clear, my files look something like:
{ “Help, I need somebody”: “Help, I need somebody”, “Help, not just anybody”: “Help, not just anybody”, “Help, you know I need someone to Heeeelp”: “Help, you know I need someone to Heeeelp”, …
…”Help me, Help meeeee”: “Help me, Help meeeee”, }
(actual files not in front of me at the moment). The spacing between strings is made up of tabs and there don’t appear to be any carriage returns/line breaks, although opening in Word adds them in.
Thanks again.
When opened with Word 2010, as mentioned, carriage returns are generated between the strings. So (with CR to represent carriage returns) the structure would appear to be:
{CRTAB”Help, I need somebody”:CRTAB”Help, I need somebody”,CRTABCRTAB”Help, not just anybody”:CRTAB”Help, not just anybody”,CRTABCRTAB”Help, you know I need someone to Heeeelp”:CRTAB”Help, you know I need someone to Heeeelp”,…
…”Help me, Help meeeee”:CRTAB”Help me, Help meeeee”CR}
In Notepad, as mentioned, there are no Carriage returns but there does seem to be some kind of invisible character where the Carriage Returns appear in Word; cursoring through the blank space, the cursor seems to remain stationary for a key-press before each TAB.
While preparing this post I noticed that there’s no comma after the last editable string in my file. Is that normal?
Ugh, that’s probably one of the most weird and most clumsy “solutions” I have ever heard of :-
You better start using some decent text editor which can handle Unix linebreaks (which are probably the “mysterious invisible characters”) instead of Notepad.
The person responsible for including Notepad with all its STUPIDITY in today’s operating systems should burn in hell forever 🙁
Oh, and yes, thre’s no comma after the last object on JSON… as you can see in JSON specification at json.org.
I tried this following your example, and created the json file type without problems i Studio 2015. But when I open a new project the new file type is not visible and the files remain Unknown and for reference only. Is there a difference in 2015 compared to what you did in 2014? Or did I do a mistake somewhere (double checked and didn’t see anything)?
I guess the most likely thing is that you did not make the change in the project template you are using to create your projects. But it’s quite hard for mew to answer this under these conditions because I have no idea what you actually did or how you are setup. There are no differences between 2014 nd 2015 in this regard. Maybe we can take take a look together during the week over Skype perhaps?
This is the first time I ever created a new file type… I did what you described above in the general Options. After that I thought I could just create a new project and the new file type would be picked up? I don’t know what you mean by changing the project template, since I created an altogether new project (after restart of Studio) so I thought it would be available automatically? I need to get started Monday (or Tuesday at the latest) but if you have time then to Skype that would be great. My Skype address: eva.heljesten@evrodoc.se
Thanks!
That looks more like an email address… but I sent a contact request to the Eva that popped up in Skype.
I accepted 🙂
Hi Paul, Many thanks for this ! It is really useful and so well explained ! Best,
Sarah
We built free plugin for SDL Trados Studio that handles JSON Files. It should solve most issues discussed here and it’s a bit easier to use than regex. Give it a try and let us know what you think:
https://blog.supertext.ch/en/2016/05/json-file-type-for-trados/
It’s also in the Open Exchange app store.
I see that it actually uses regexp to define the ‘path’… perhaps you can check the JQ’s syntax: https://stedolan.github.io/jq/
It has an extraction feature. So you don’t have to define the regex yourself if you don’t want to. But JQ sounds interested, we will have a look at it for the next version. Thanks for the hint.
Thanks Remy, it works really well too. It’s on the appstore here. One possible enhancement, based on a request I had last night, would be to allow the user to write the translation into a different object than the source. So effectively becoming a bilingual/multilingual filetype. Current solution is to use regex search and replace to put the source into a target object and then translate that.
Great work though.
Hey Paul, yes, we quickly looked at the bilingual feature. But we figured we push the first version out and see what feedback we get. We didn’t need this internally yet, so it was not top priority.
Thank you for explaining JSON beautifully, I would like to share few JSON tools such as http://jsonformatter.org and http://codebeautify.org/jsonviewer for JSON Lovers.
what if json is embeded in of a html.
Then our plugin cannot help you. Sorry. But seems a bit a funky way to deliver JSON anyway?
Hi there, I can extract the translatable lines from my JSON file using the opening and closing patterns, but some have HTML embedded in them (plus tag text in {pointy brackets} (the pointy tags are sometimes mid-sentence, so are presumably merge fields) and instances of ”
“. How do I go about suppressing this from the Trados editor or converting it to tags? I’ll paste an example below. Thanks for any help!
Let op!Als u nu besluit uw deelname aan het netto-ouderdomspensioen te stoppen, dan kunt u niet later
opnieuw besluiten deel te nemen.{DeelnemerBijsparenFN}
The translatable text I need is: Let op! Als u nu besluit uw deelname aan het netto-ouderdomspensioen te stoppen, dan kunt u niet later opnieuw besluiten deel te nemen.
You need to do a little work if you want to show the tags in the comments as the markup will be treated as markup as opposed to the text you wanted.
But perhaps you would be better off looking at the JSON filetype that is part of Studio 2017 already, or the very cool filetype app on the appstore for handling JSON files by Supertext.
Hi Paul, tried the filetype app by Supertext. Really helpful suggestions.
I was wondering if you had any suggestions on how to tackle the following:
In the following snippet, I only want to import the question after localeName English (US). How can I specify that is the only one I want?
“locale” : “en”,
“localeName” : “English (US)”,
“question” : “text to be translated”
}, {
“locale” : “ar”,
“localeName” : “العربية”,
“question” : “existing translation”
Hey Jos
You can use the “Extract” feature and specify which properties you need. Have a look on our help page:
https://blog.supertext.ch/en/2016/05/json-file-type-for-trados/
This is a better solution than messing around with regex!
Remy, did you already fix the bug I reported in the blog post comments? It’s been quite a while since November…
Hello Jos, I’m not sure if this will work in Studio but perhaps something like this:
(?<="English (US)",)
"question"s:s"
I think the line feeds might be a problem here. The expression will also vary depending on how your example has been rendered in this forum. If you send me a file, just a small sample, I'll happily test it? You can email pfilkin@sdl.com
Also note the best place to ask these questions is in our regex forum. Always good to share the Q&A on this stuff… lots of experts out there who know better than me!
Hi Paul and Remy,
Thanks for the help! I did indeed use the Extract option.
It gave me:
questions[d+].title
questions[d+].localeName
questions[d+].question
I am curious how I could filter it down further so it will only show the question that is preceded by localName “English (US)”.
At the moment I have simply locked all the other locales and that is working fine for now, just curious 🙂
Jos:
Just remove the the
questions[d+].title
questions[d+].localeName
and only leave
questions[d+].question
Evzen:
Indeed, it has been a while, but since nobody was interested in sponsoring it, it was not super urgent. But should be finished soon. And any sponsoring is still welcome 😀
Well, Remy, if you don’t like maintaining the stuff you release, you should not have released it in the first place… Or release the source code and you don’t need to care much anymore.
Otherwise you would need to realize that even free stuff needs some care, especially when it comes to bugs.
Evzen… you don’t have to use it!
Oops, completely forgot about that, I should’ve linked to a pastebin. Thanks for the pointer to the filetype app.
Sure… I actually don’t… because the bug makes it unusable here :-.
But, what is the point of releasing (and suggesting to others) stuff which has such bugs? And what is the point of releasing stuff if one is bothered by maintaining it? Isn’t in every developer’s best interest to maintain the stuff they decided to release?
Am I really the only one who sees it as very weird?
Probably… yes! I think you just don’t get it. Supertext created a filetype for their own use and then shared it for others to use at no cost. I guess if the bug that bothered you affected them too then they’d fix it. Otherwise they fix it in their own time. I guess they could opensource it and then people could fix it, but I can tell you very few people fix anything that others deliver… it’s easier to complain!
I would love to have a few more developers in my team and a budget that’s twice the size. Unfortunately I don’t. So we have to deal with what we have. And there are mission critical issues that just have higher impact for us than this one. But as I said, we’re open for anyone who wants to sponsor us working on this issue. If it is that important, then it’s sure worth something. Otherwise it’s obviously not important enough. Second, it is actually pretty high on our to-do list now. You can also try the new JSON filter that comes with Trados 2017.
I definitely think it’s worth something Rémy… sadly reality is something else and I doubt even Evzen would contribute to this.
@Evzen, there should be a new version of our JSON in the appstore by tomorrow. We’ve uploaded it already, just waiting for approval. Give it a try and let us know if it fixed your issue. You can send the “Thank you beers” to Supertext in Switzerland.
All published Rémy 🙂
Great JSON article.
At the same time share a website, hoping to help JSON lovers .
https://www.jsonformatting.com/